如何使用語言模型
選擇、下載與打包模型
目前,此插件設計為支援單一語言模型,需先在編輯器中選取,以便與專案一起打包和使用。請依照以下步驟來選擇、下載並暫存特定的語言模型:
-
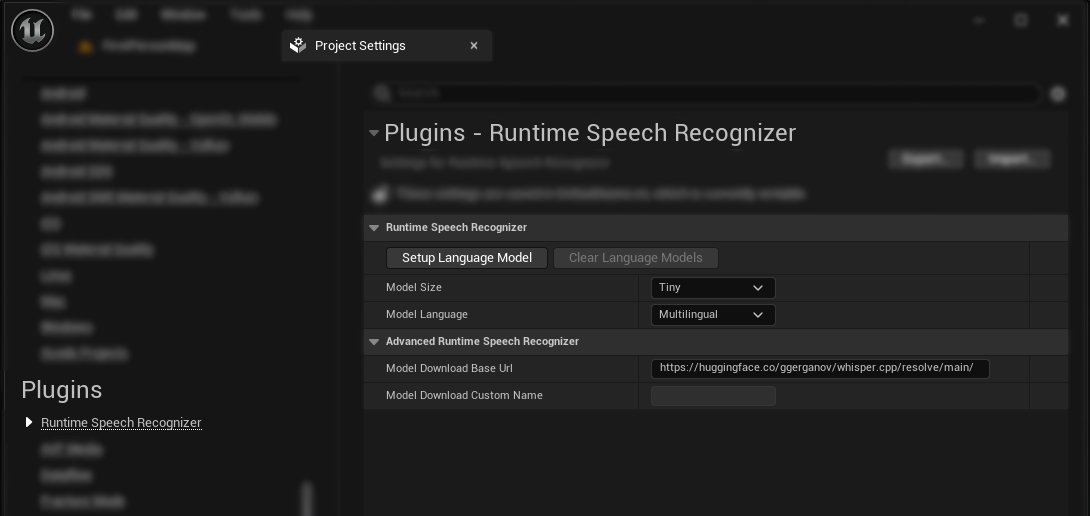
從可用選項中選擇所需的模型。此插件預設支援以下模型:
標準模型:
- Tiny
- Base
- Small
- Medium
- Large V1
- Large V2
- Large V3
- Large V3 Turbo
量化模型(檔案大小較小):
- Tiny Quantized (Q5_1) - 量化至 5 位元與 1 個小數點
- Tiny Quantized (Q8_0) - 量化至 8 位元與 0 個小數點
- Base Quantized (Q5_1) - 量化至 5 位元與 1 個小數點
- Small Quantized (Q5_1) - 量化至 5 位元與 1 個小數點
- Medium Quantized (Q5_0) - 量化至 5 位元與 0 個小數點
- Large V2 Quantized (Q5_0) - 量化至 5 位元與 0 個小數點
- Large V3 Quantized (Q5_0) - 量化至 5 位元與 0 個小數點
- Large V3 Turbo Quantized (Q5_0) - 量化至 5 位元與 0 個小數點
蒸餾模型:
- Distil Small - Small 模型的蒸餾版本
- Distil Medium - Medium 模型的蒸餾版本
- Distil Large V2 - Large V2 模型的蒸餾版本
- Distil Large V3 - Large V3 模型的蒸餾版本
自訂模型:
- Custom - 指定自訂模型名稱與 URL,從伺服器下載您自己的語言模型
每個模型(Custom 除外)均可設定為多語言或僅限英文。
-
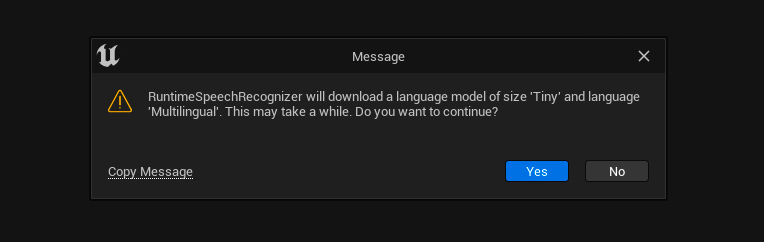
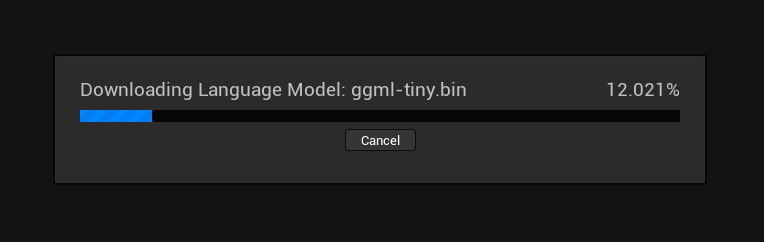
點擊設定語言模型按鈕,若所選語言模型尚未存在於您的本機電腦上,系統將自動要求您下載。
-
下載完成後,編輯器將在 "Plugins/RuntimeSpeechRecognizer/Content/LanguageModels/LanguageModel.uasset" 位置產生一個語言模型資產。此語言模型資產將是唯一與您的專案一起打包的模型。
您也可以點擊清除語言模型按鈕,移除任何已下載的本機語言模型。
或者,您也可以手動從 https://huggingface.co/ggerganov/whisper.cpp 下載語言模型,並將其僅放置於 "Plugins/RuntimeSpeechRecognizer/Content" 資料夾中。
請注意,只有選取的語言模型會與您的專案一起打包。因此,您無需擔心其他模型,因為它們在打包階段將被排除。