如何使用插件
Runtime Speech Recognizer 插件旨在從傳入的音訊資料中辨識單詞。它使用略微修改過的 whisper.cpp 版本來與引擎協作。若要使用此插件,請遵循以下步驟:
編輯器端
- 為您的專案選擇適當的語言模型,如此處所述。
執行時期端
- 建立一個 Speech Recognizer 並設定必要的參數(CreateSpeechRecognizer,參數請參閱此處)。
- 綁定所需的委派(OnRecognitionFinished、OnRecognizedTextSegment 和 OnRecognitionError)。
- 啟動語音辨識(StartSpeechRecognition)。
- 處理音訊資料並等待委派的結果(ProcessAudioData)。
- 在需要時停止語音辨識器(例如,在 OnRecognitionFinished 廣播之後)。
該插件支援以浮點數 32 位元交錯 PCM 格式傳入的音訊。雖然它與 Runtime Audio Importer 配合良好,但並不直接依賴於它。
辨識參數
該插件同時支援串流和非串流音訊資料的辨識。若要針對您的特定使用案例調整辨識參數,請呼叫 SetStreamingDefaults 或 SetNonStreamingDefaults。此外,您可以靈活地手動設定個別參數,例如執行緒數量、步長、是否將傳入語言翻譯成英文,以及是否使用先前的轉錄。請參閱辨識參數列表以取得可用參數的完整列表。
提升效能
請參閱如何提升效能章節,以獲取有關最佳化插件效能的提示。
語音活動偵測 (VAD)
在處理音訊輸入時,特別是在串流場景中,建議使用語音活動偵測 (VAD) 來過濾掉空白或僅有噪音的音訊片段,然後再將其傳遞給辨識器。此過濾功能可以在可捕捉音波端啟用,使用 Runtime Audio Importer 插件,這有助於防止語言模型產生幻覺——即試圖在噪音中尋找模式並生成錯誤的轉錄。
為了獲得最佳的語音辨識結果,我們建議使用 Silero VAD 提供者,它提供卓越的噪音容忍度和更準確的語音偵測。Silero VAD 可作為 Runtime Audio Importer 插件的擴充功能使用。有關 VAD 配置的詳細說明,請參閱語音活動偵測文件。
下方範例中的可複製節點出於相容性原因使用預設的 VAD 提供者。若要提升辨識準確度,您可以透過以下方式輕鬆切換到 Silero VAD:
- 按照 Silero VAD 擴充功能章節中的說明安裝 Silero VAD 擴充功能
- 在使用 Toggle VAD 節點啟用 VAD 後,新增一個 Set VAD Provider 節點,並從下拉選單中選擇 "Silero"
在插件附帶的示範專案中,VAD 預設為啟用狀態。您可以在示範專案中找到更多關於示範實作的資訊。
範例
插件中的 Content -> Demo 資料夾內包含一個良好的專案示範,您可以將其用作實作的範例。
這些範例說明了如何使用 Runtime Speech Recognizer 插件處理串流和非串流音訊輸入,並以 Runtime Audio Importer 作為取得音訊資料的範例。請注意,需要單獨下載 RuntimeAudioImporter 才能使用範例中展示的相同音訊匯入功能集(例如可捕捉音波和 ImportAudioFromFile)。這些範例僅用於說明核心概念,不包含錯誤處理。
串流音訊輸入範例
注意: 在 UE 5.3 及其他版本中,複製 Blueprints 後可能會遇到缺少節點的情況。這可能是由於不同引擎版本之間的節點序列化差異所致。請務必驗證您的實作中所有節點是否都已正確連接。
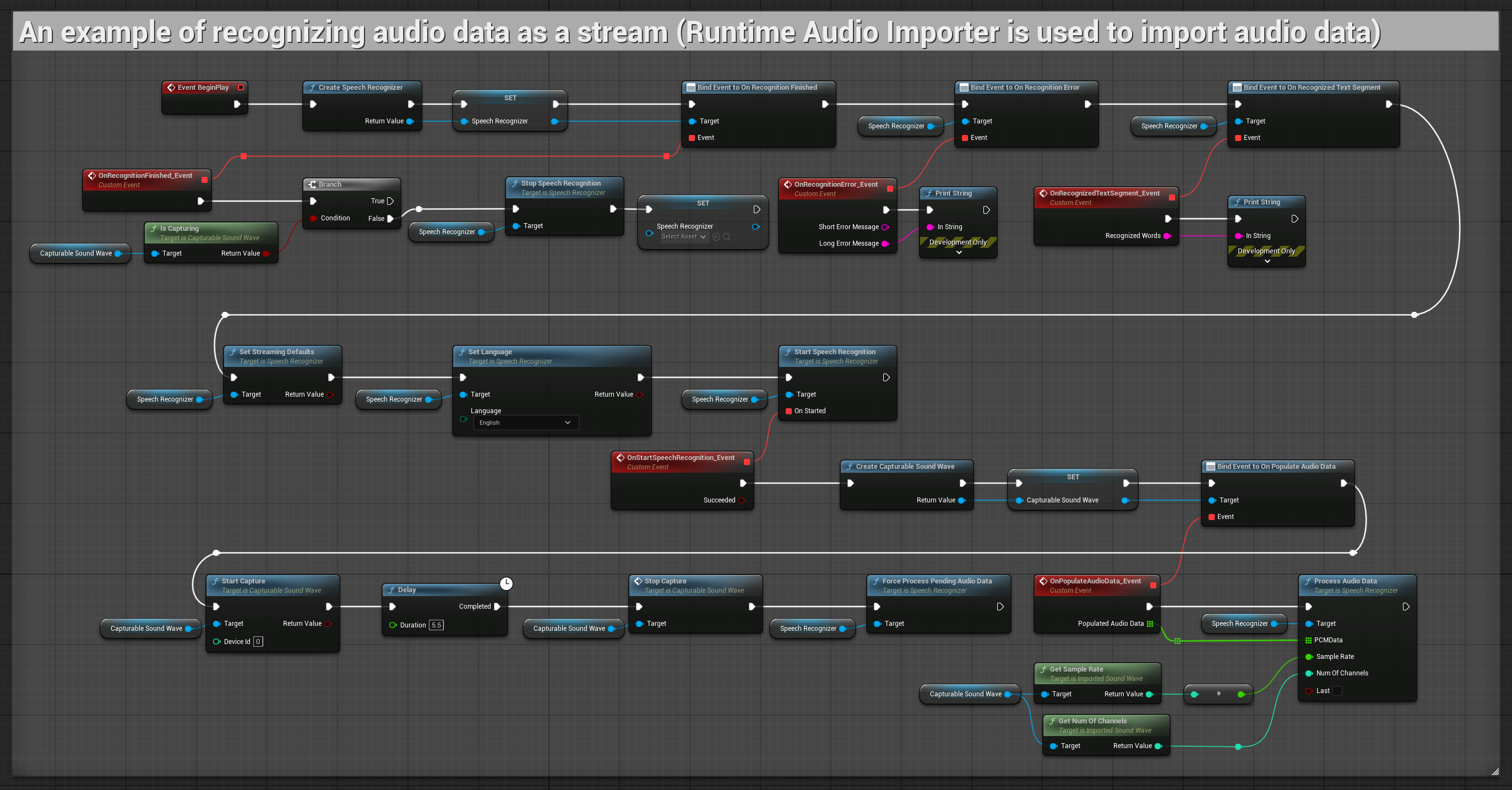
1. 基本串流辨識
此範例示範了使用可捕捉音波從麥克風捕捉音訊資料作為串流,並將其傳遞給語音辨識器的基本設定。它會錄製約 5 秒的語音,然後處理辨識,適用於快速測試和簡單實作。 可複製的節點。
此設定的主要功能:
- 固定的 5 秒錄製時間
- 簡單的一次性辨識
- 最低設定要求
- 非常適合測試和原型設計
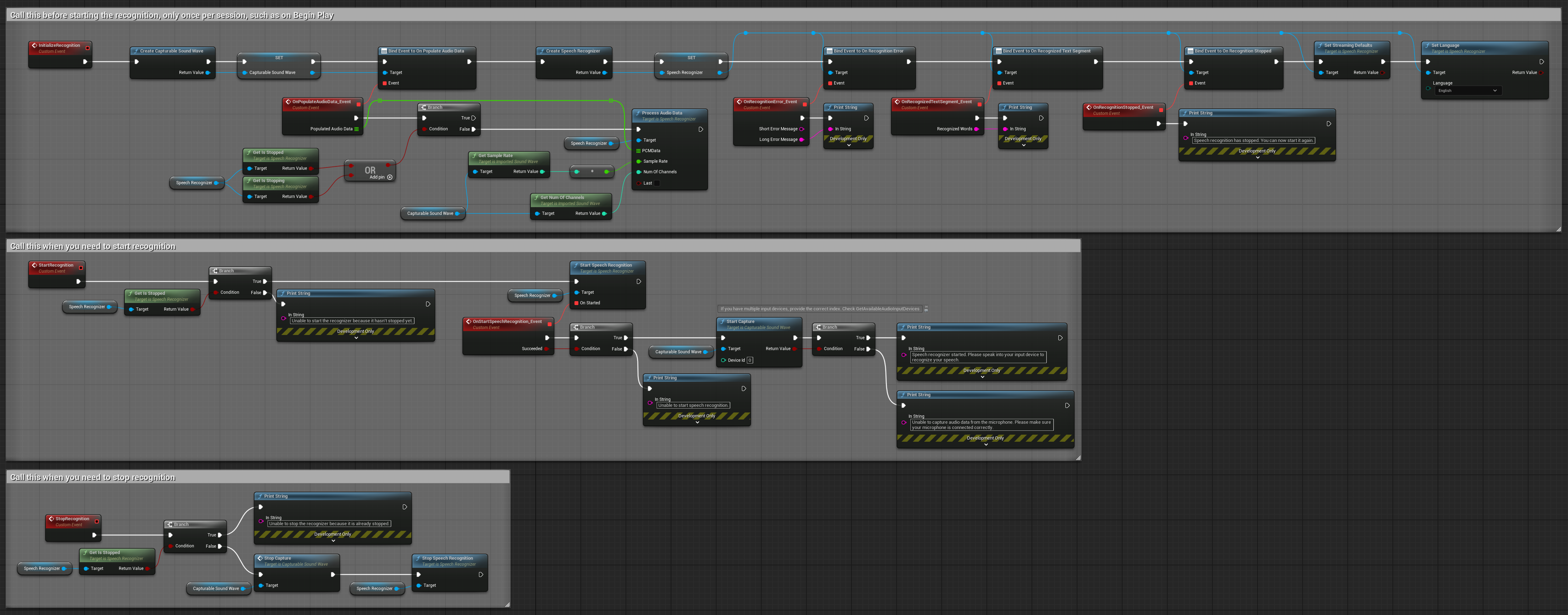
2. 受控串流辨識
此範例擴展了基本的串流設定,增加了對辨識過程的手動控制。它允許您隨意開始和停止辨識,適用於需要精確控制辨識時機的場景。 可複製的節點。
此設定的主要功能:
- 手動開始/停止控制
- 連續辨識能力
- 靈活的錄製時間
- 適用於互動式應用程式
3. 語音啟動指令辨識
此範例針對指令辨識場景進行了最佳化。它將串流辨識與語音活動偵測 (VAD) 結合,以在使用者停止說話時自動處理語音。辨識器僅在偵測到靜音時才開始處理累積的語音,使其成為指令式介面的理想選擇。 可複製的節點。
此設定的主要功能:
- 手動開始/停止控制
- 啟用語音活動偵測 (VAD) 以偵測語音片段
- 偵測到靜音時自動觸發辨識
- 最佳化於短指令辨識
- 透過僅辨識實際語音來減少處理開銷
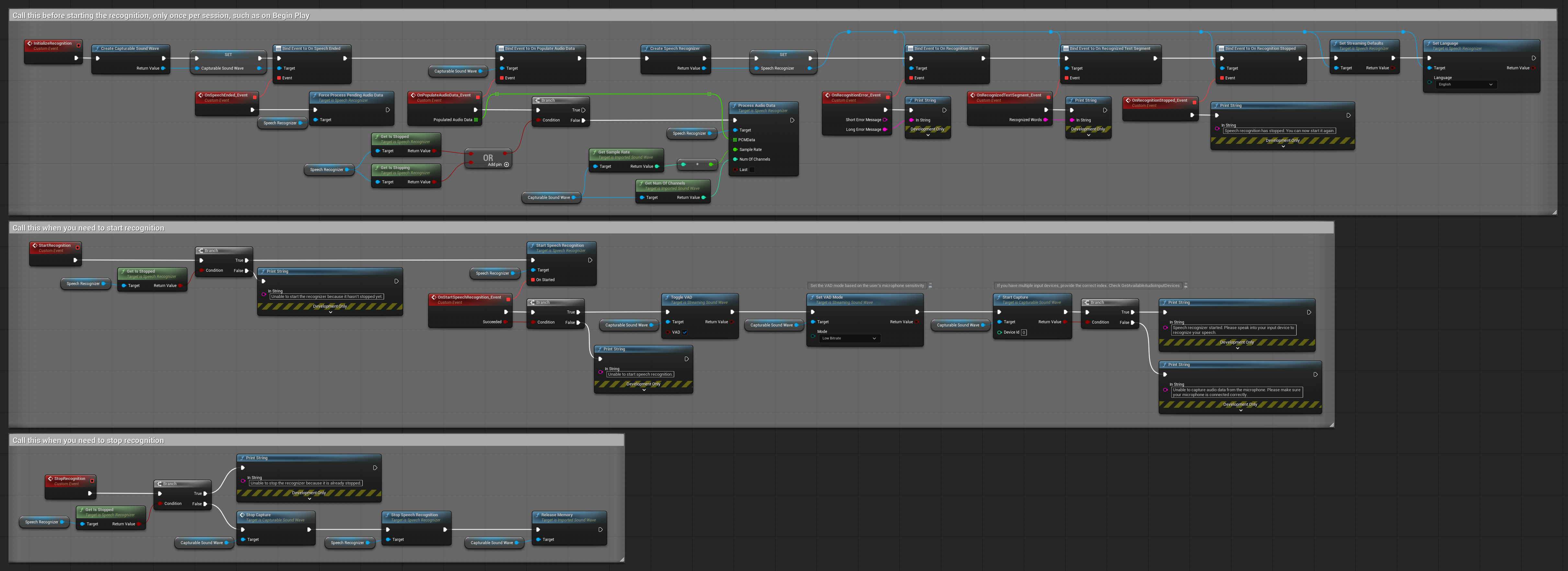
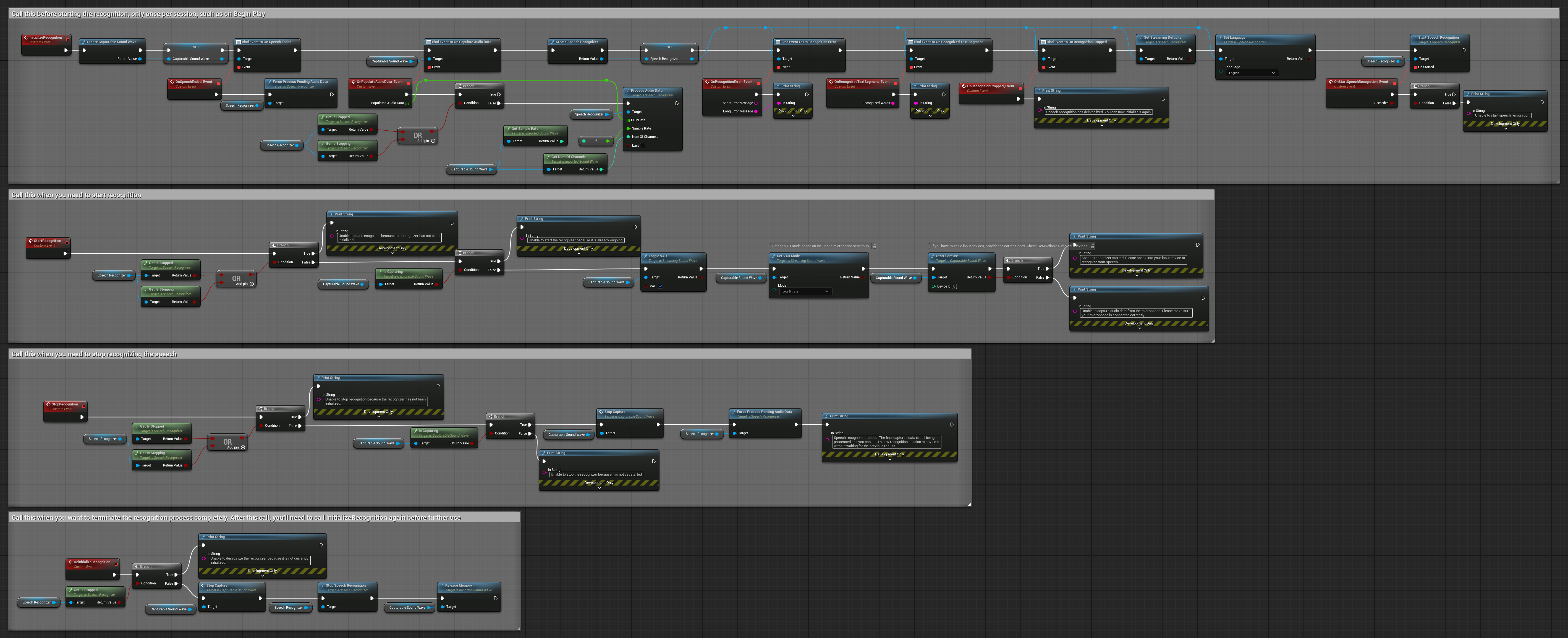
4. 自動初始化語音辨識並處理最終緩衝區
此範例是語音啟動辨識方法的另一種變體,具有不同的生命週期處理方式。它會在初始化期間自動啟動辨識器,並在解除初始化期間自動停止。一個關鍵功能是,它會在停止辨識器之前處理最後累積的音訊緩衝區,確保當使用者想要結束辨識過程時不會遺失任何語音資料。此設定對於需要在說話中途停止時仍能捕捉完整使用者話語的應用程式特別有用。 可複製的節點。
此設定的主要功能:
- 初始化時自動啟動辨識器
- 解除初始化時自動停止辨識器
- 在完全停止前處理最終音訊緩衝區
- 使用語音活動偵測 (VAD) 進行高效辨識
- 確保停止時不會遺失任何語音資料
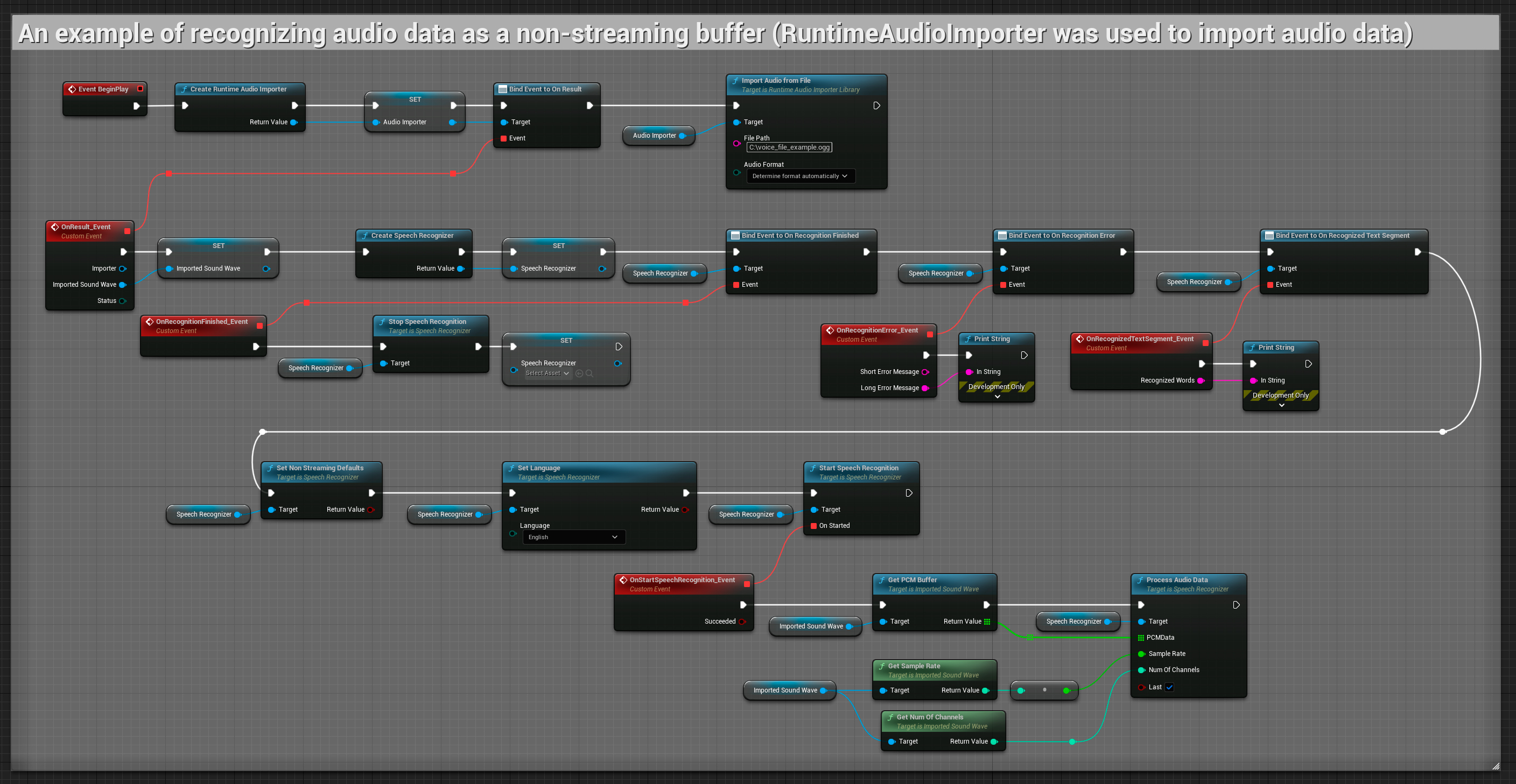
非串流音訊輸入
此範例將音訊資料匯入到 Imported sound wave,並在匯入完成後辨識完整的音訊資料。 可複製的節點。