辨識參數列表
這些參數只能在辨識器未運行時設定。
此處並非 Whisper 可用參數的完整列表,僅列出最重要的參數。如有需要,此列表將會更新。
設定辨識參數
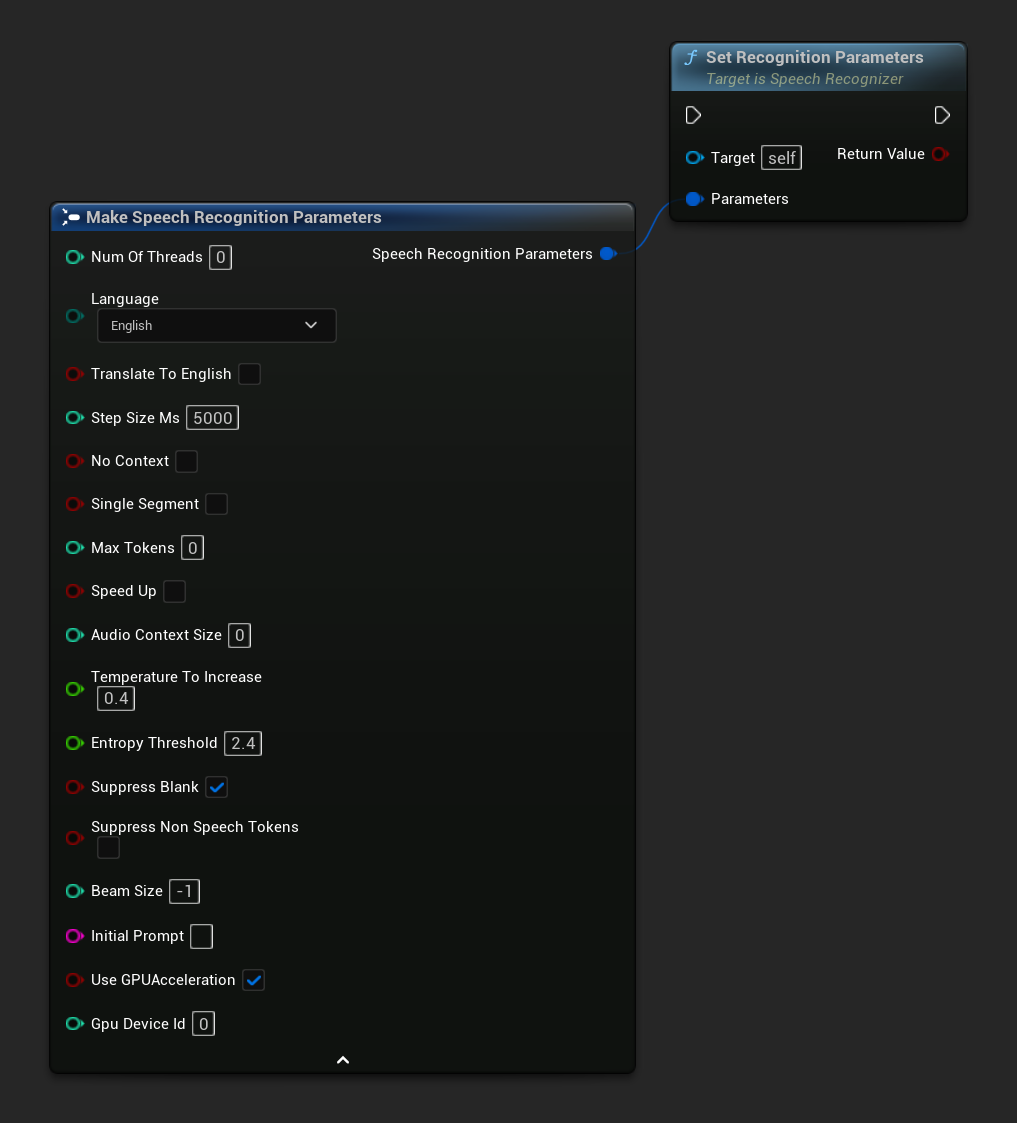
設定語音辨識的參數。如果您只想變更特定參數,請考慮使用個別的設定函式。
設定串流預設值
設定適用於串流語音辨識的預設參數。
此函式會覆蓋所有先前套用的參數。如果您需要以串流預設值作為基礎配置,請務必在設定自訂參數之前呼叫此函式。
設定非串流預設值
設定適用於非串流語音辨識的預設參數。
此函式會覆蓋所有先前套用的參數。如果您需要以非串流預設值作為基礎配置,請務必在設定自訂參數之前呼叫此函式。
設定執行緒數量
設定用於語音辨識的執行緒數量。將此值設為 0 以使用核心數量。
設定語言
設定用於語音辨識的語言。必須是編輯器設定中所選語言模型支援的語言。
將語言設為自動會降低辨識準確度和效能。
取得偵測到的語言
從上一次辨識中取得偵測到的語言。以列舉值的形式傳回語言。
注意: 此函式僅在執行辨識後才能運作。如果語言偵測失敗或未執行,則會傳回 Auto。這在啟用自動語言偵測時特別有用,可用於識別實際辨識到的語言。
取得語言代碼
將語言列舉值轉換為其語言代碼字串(例如,En -> "en",Fr -> "fr",De -> "de")。
取得語言完整名稱
將語言列舉值轉換為其完整語言名稱(例如,En -> "English",Fr -> "French",De -> "German")。
設定翻譯為英文
![]()
設定是否將辨識到的詞彙翻譯為英文。如果啟用,語言模型必須是多語言的。
設定步長
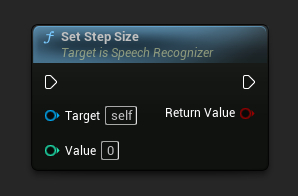
設定以毫秒為單位的步長。決定傳送音訊資料進行辨識的頻率。預設值為 5000 毫秒(5 秒)。
設定無上下文
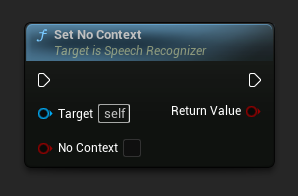
設定是否使用先前的轉錄(如果有的話)作為解碼器的初始提示。
設定單一段落
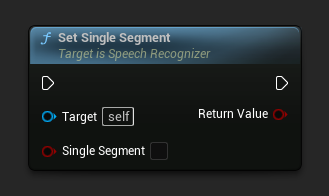
設定是否強制輸出單一段落(適用於串流)。
設定最大 Token 數
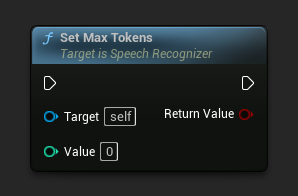
設定每個文字段落的最大 token 數量。設為 0 表示無限制。
設定加速
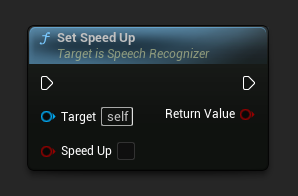
設定是否使用 Phase Vocoder 將辨識速度提升 2 倍。設為 false 可改善輸出品質。
設定音訊上下文大小
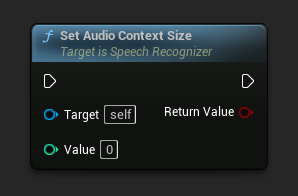
設定音訊上下文的大小。設為 0 可改善輸出品質。
設定遞增溫度
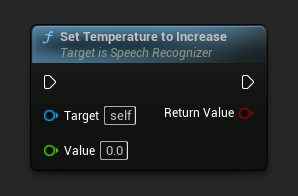
設定當解碼失敗且未達到以下任一閾值時,要遞增的溫度值。
設定熵閾值
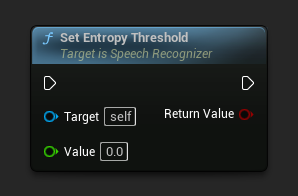
設定熵閾值。如果壓縮率高於此值,則將解碼視為失敗。類似於 OpenAI 的 "compression_ratio_threshold"。
設定抑制空白
![]()
設定是否抑制輸出中出現的空白。
設定抑制非語音 Token
設定是否抑制輸出中出現的非語音 token。
設定 Beam 大小
設定 beam search 中的 beam 數量。僅在溫度為零時適用。
設定初始提示
設定第一個視窗的初始提示。這可用於為辨識提供上下文,使其更有可能正確預測詞彙,例如自訂詞彙或專有名詞。
有關有效提示策略的更多詳細資訊,請參閱 Whisper 提示指南。
設定 GPU 加速
設定是否使用 GPU 加速進行語音辨識(目前僅適用於 Windows)。
設定 GPU 裝置 ID
設定用於語音辨識的 GPU 裝置 ID。預設值為 0。這對於具有多個 GPU 的系統很有用,可指定用於辨識過程的 GPU。如果指定的 GPU 裝置 ID 無效,則會改用第一個可用的 GPU 裝置索引。