플러그인 사용 방법
Runtime AI Chatbot Integrator는 두 가지 주요 기능을 제공합니다: 텍스트-텍스트 채팅과 텍스트-음성 변환(TTS). 두 기능 모두 유사한 워크플로우를 따릅니다:
- API 제공자 토큰 등록
- 기능별 설정 구성
- 요청 전송 및 응답 처리
제공자 토큰 등록
어떤 요청을 보내기 전에, RegisterProviderToken 함수를 사용하여 API 제공자 토큰을 등록하세요.
Ollama는 로컬에서 실행되며 API 토큰이 필요하지 않습니다. Ollama의 경우 이 단계를 건너뛸 수 있습니다.
- Blueprint
- C++
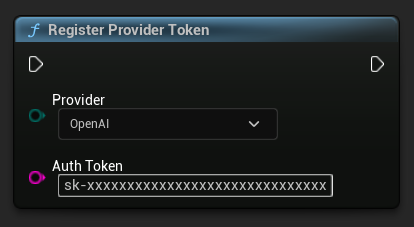
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
텍스트-텍스트 채팅 기능
이 플러그인은 각 제공업체별로 두 가지 채팅 요청 모드를 지원합니다:
비스트리밍 채팅 요청
단일 호출로 완전한 응답을 받습니다.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
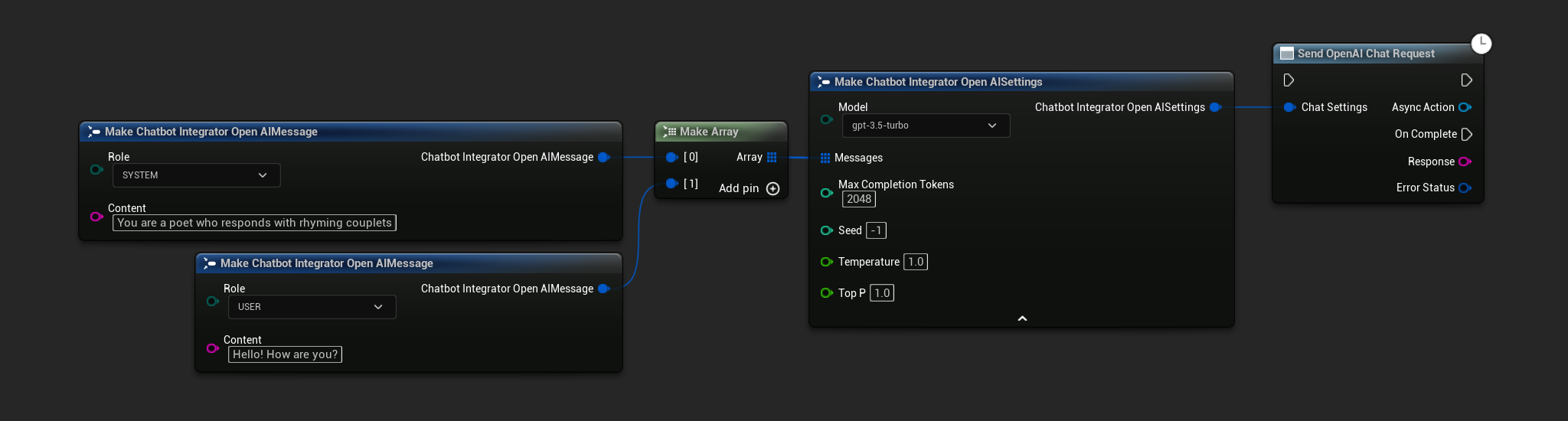
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
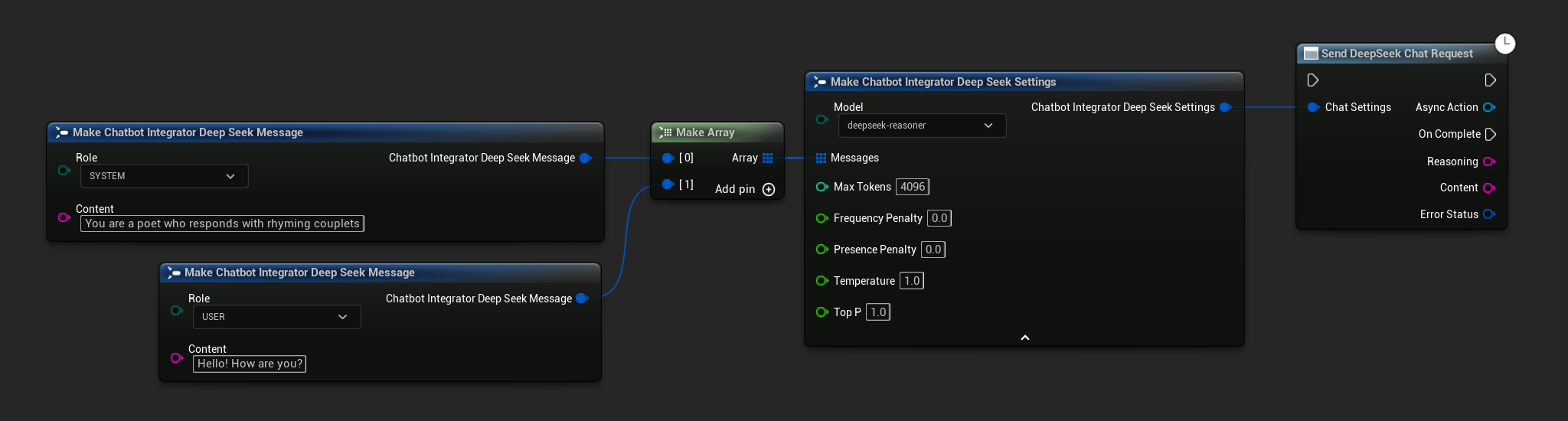
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
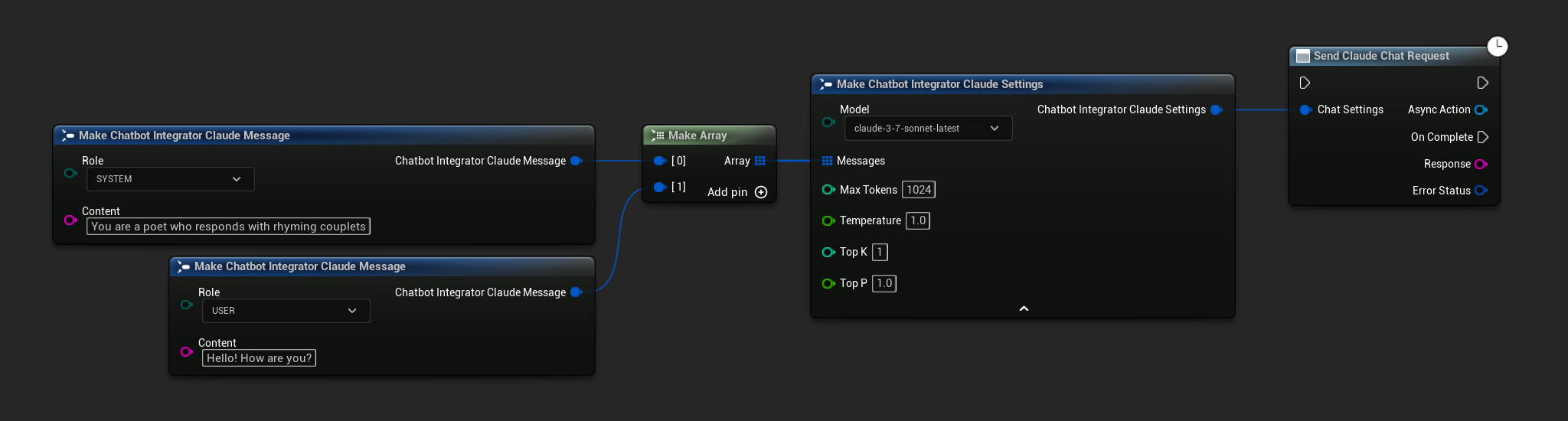
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
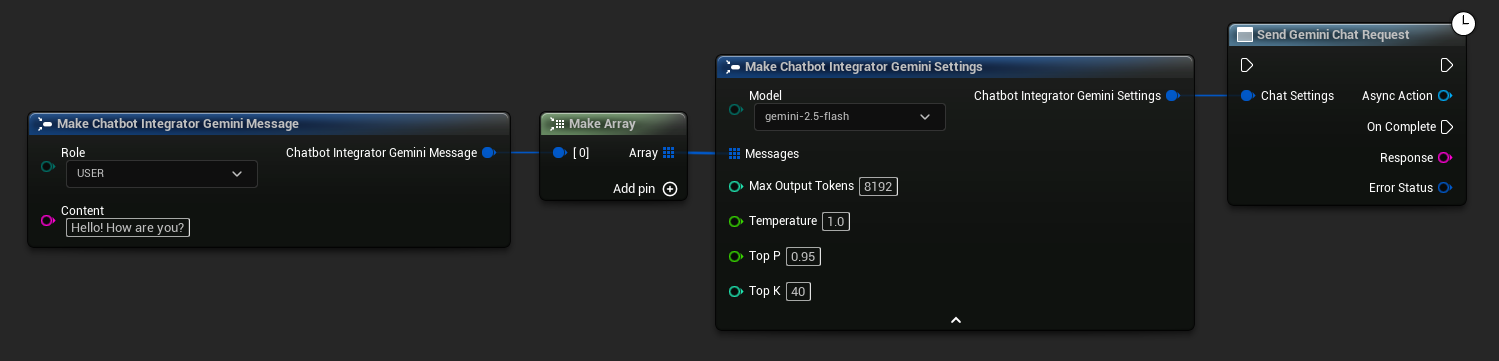
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
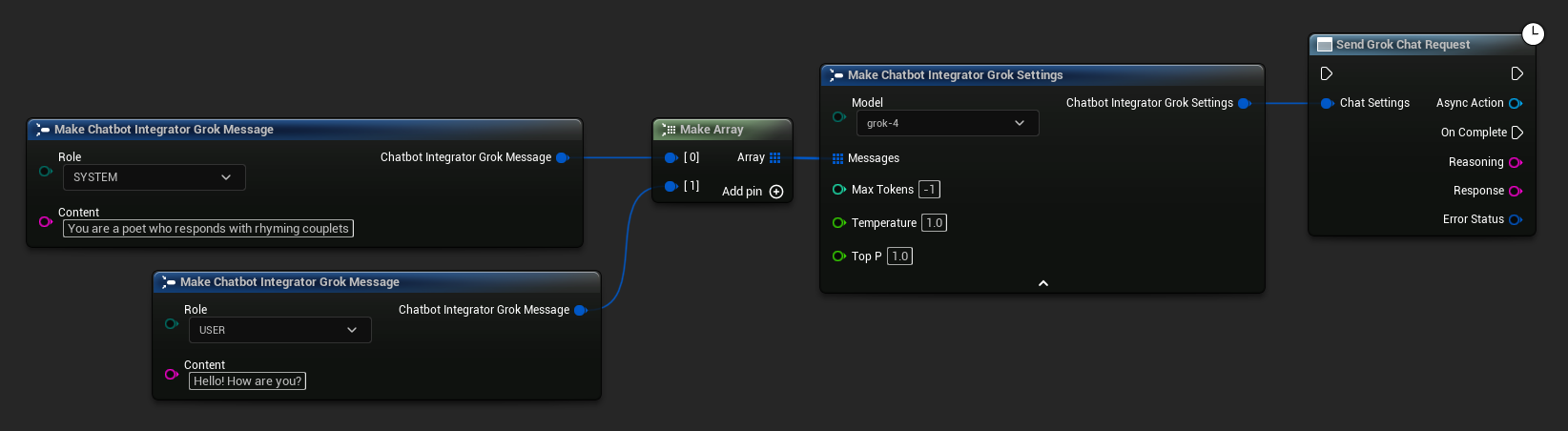
// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
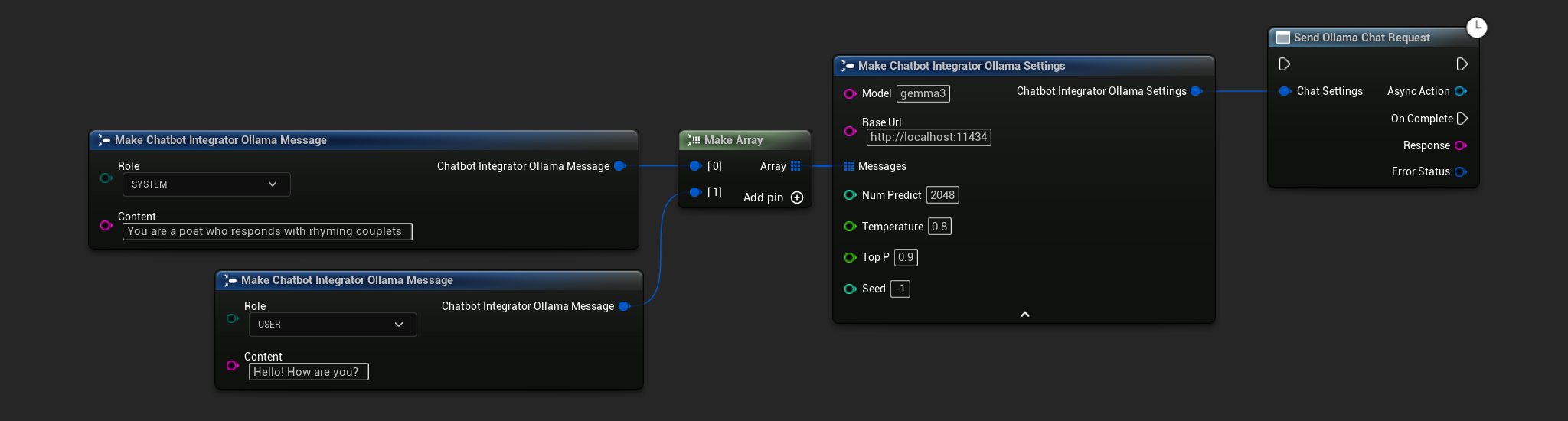
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
스트리밍 채팅 요청
더 동적인 상호작용을 위해 실시간으로 응답 청크를 수신합니다.
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
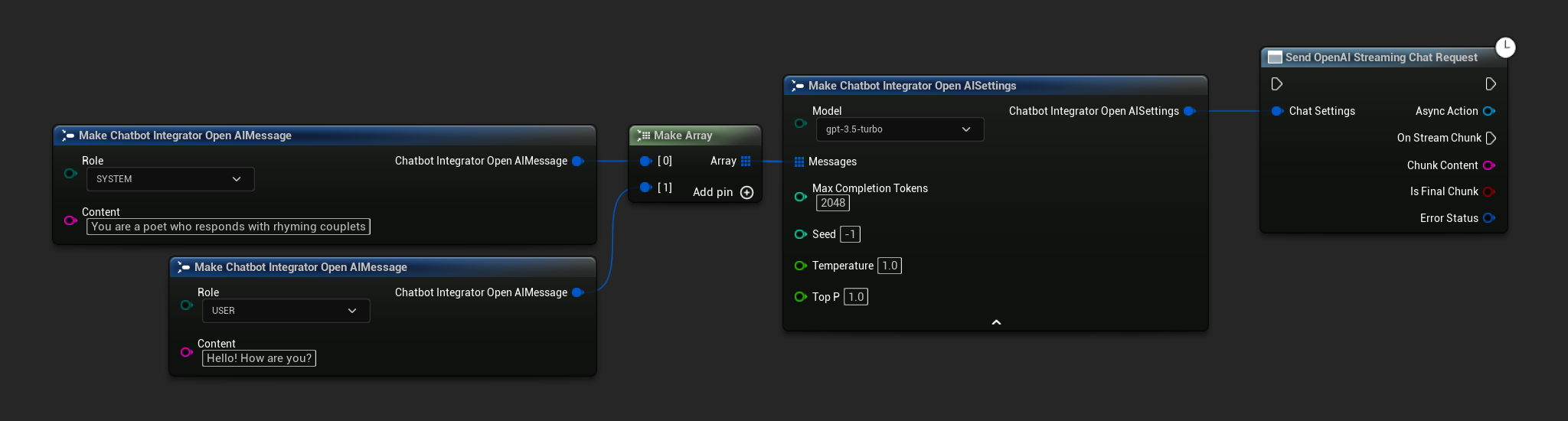
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
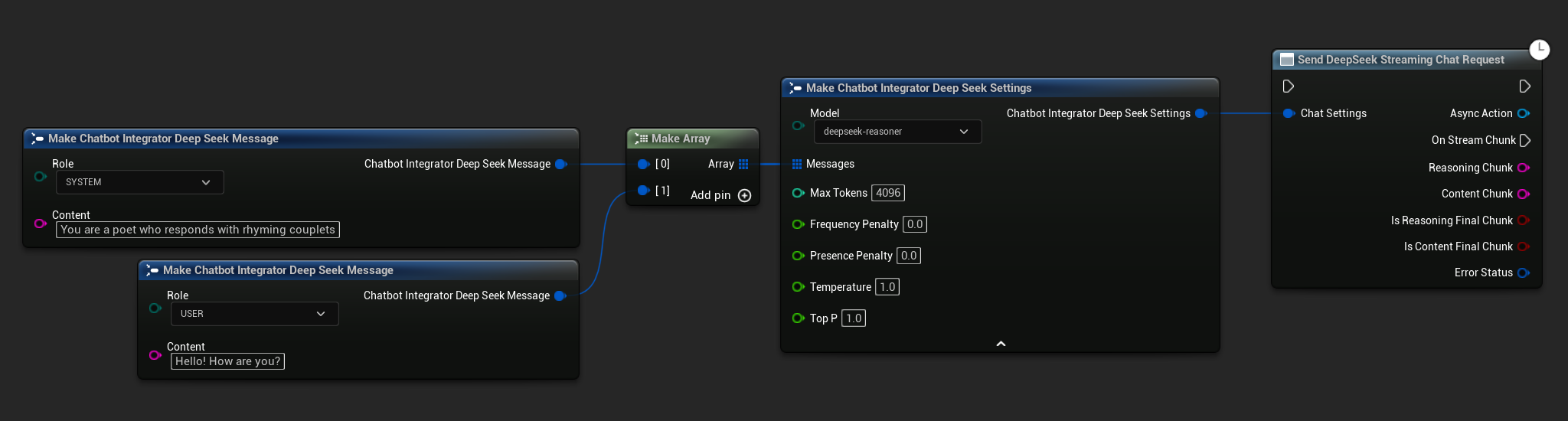
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
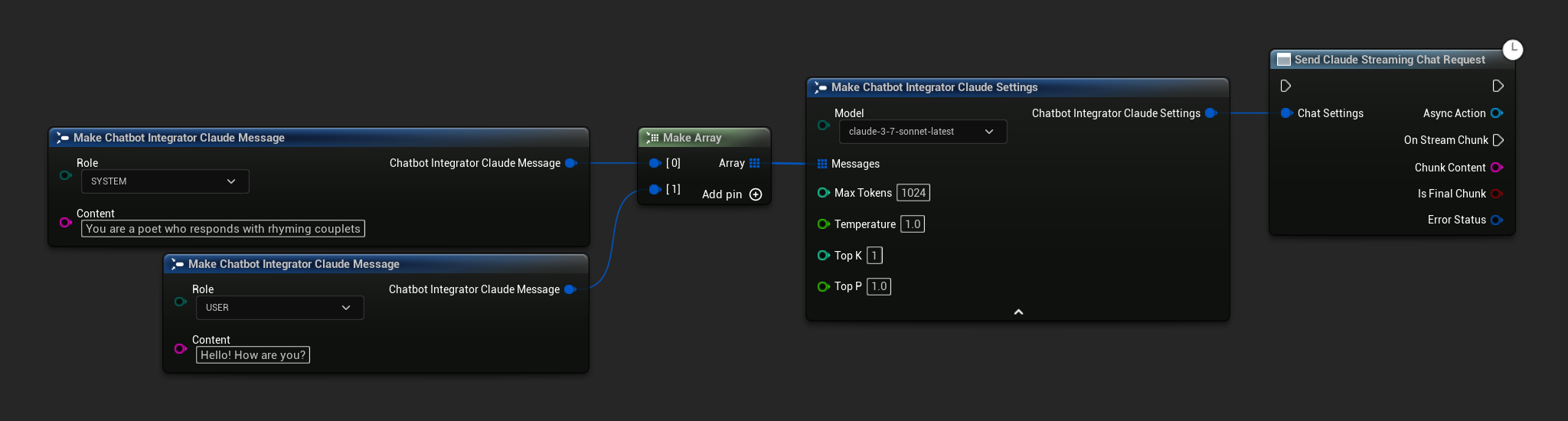
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
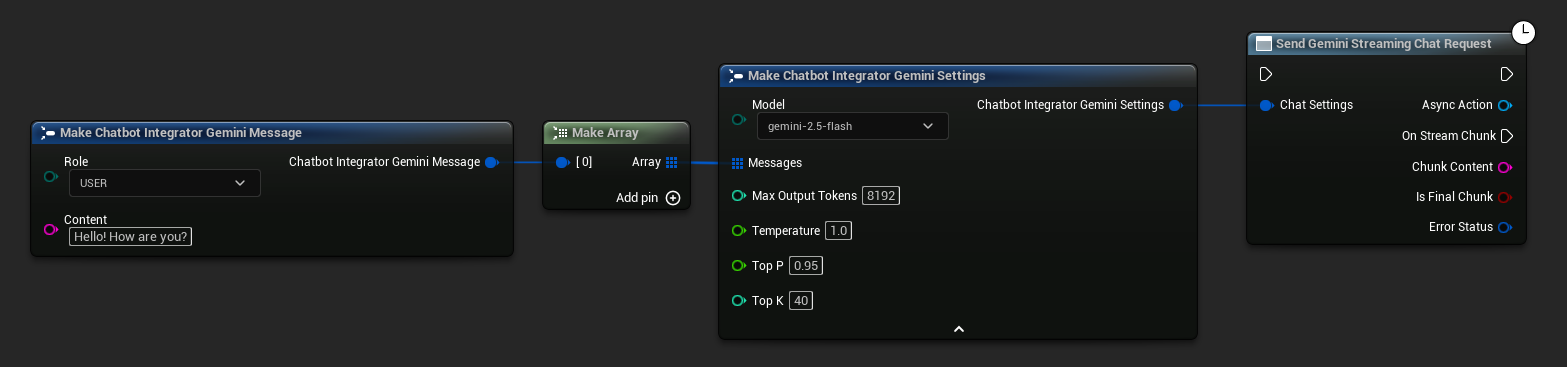
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
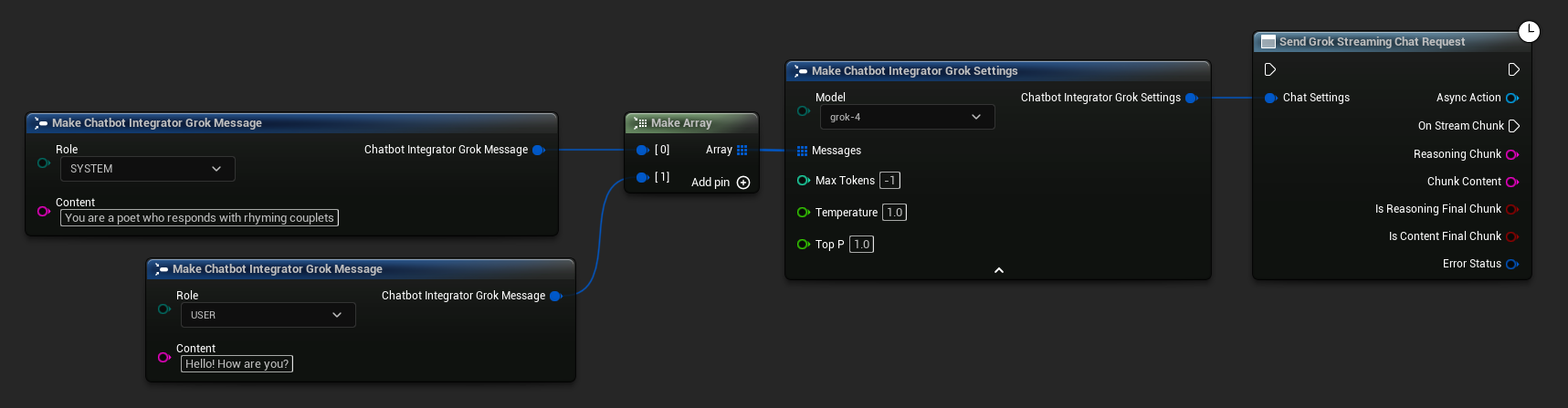
// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
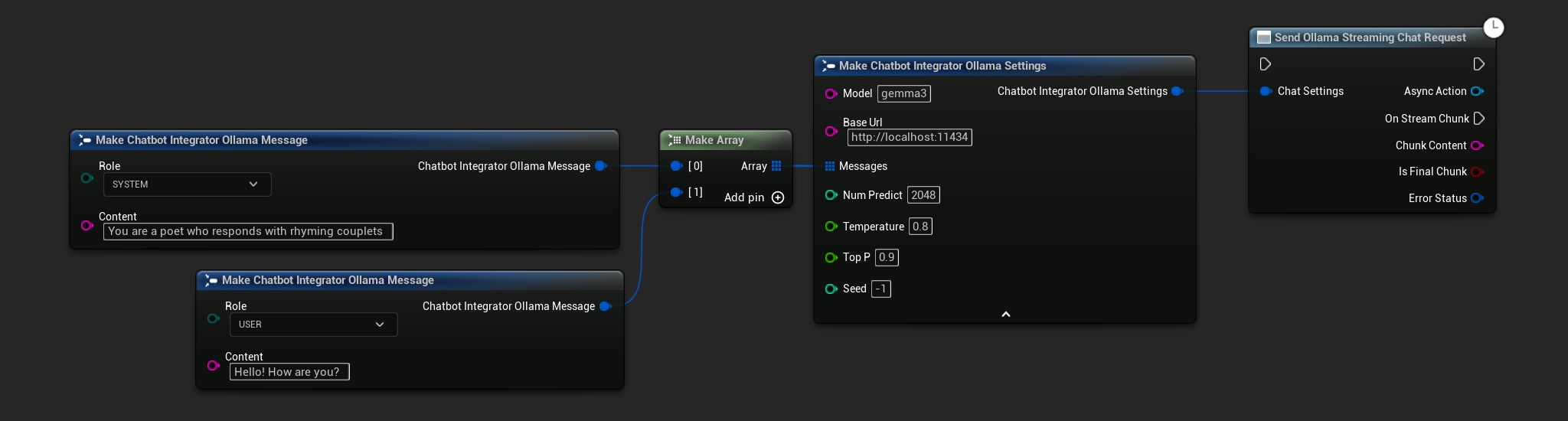
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
텍스트 음성 변환(TTS) 기능
선도적인 TTS 제공업체를 사용하여 텍스트를 고품질 음성 오디오로 변환합니다. 이 플러그인은 원시 오디오 데이터(TArray<uint8>)를 반환하며, 프로젝트의 필요에 따라 처리할 수 있습니다.
아래 예제들은 Runtime Audio Importer 플러그인( 오디오 임포트 문서 참조)을 사용한 재생을 위한 오디오 처리를 보여주지만, Runtime AI Chatbot Integrator는 유연하게 설계되었습니다. 이 플러그인은 단순히 원시 오디오 데이터를 반환하므로, 특정 사용 사례에 맞게 이를 처리하는 방법에 대한 완전한 자유를 제공합니다. 여기에는 오디오 재생, 파일 저장, 추가 오디오 처리, 다른 시스템으로 전송, 사용자 정의 시각화 등이 포함될 수 있습니다.
비스트리밍 TTS 요청
비스트리밍 TTS 요청은 전체 텍스트가 처리된 후 단일 응답으로 완전한 오디오 데이터를 반환합니다. 이 접근 방식은 전체 오디오를 기다리는 것이 문제가 되지 않는 짧은 텍스트에 적합합니다.
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
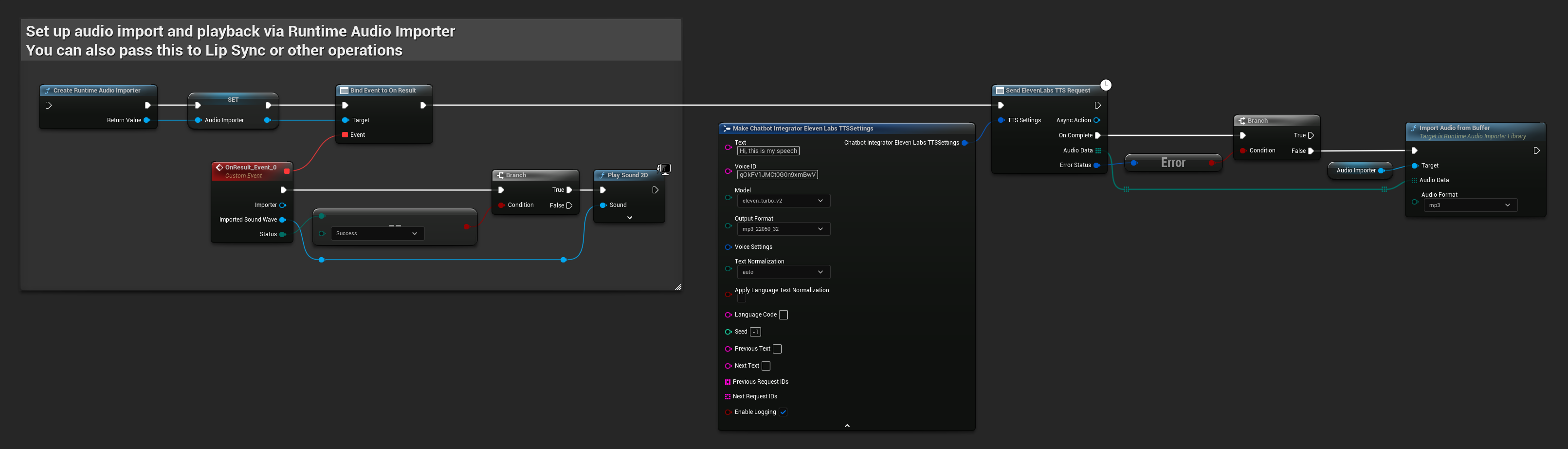
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
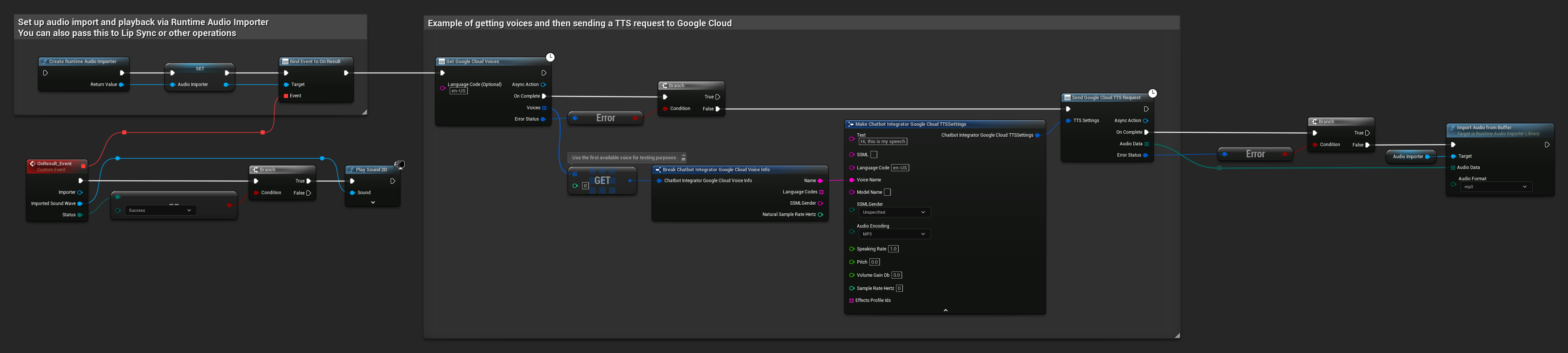
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
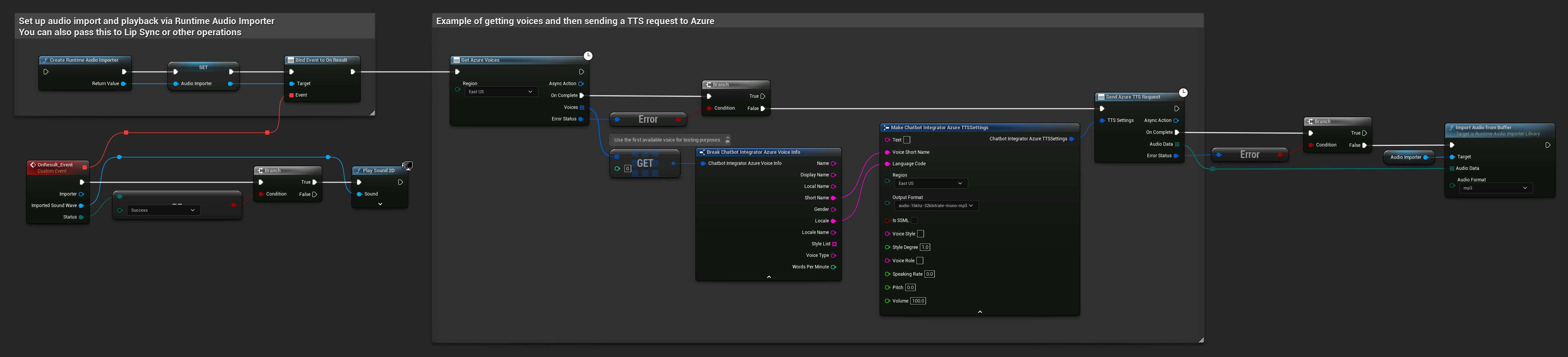
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
스트리밍 TTS 요청
스트리밍 TTS는 오디오 청크가 생성되는 대로 전달하여 전체 오디오가 합성되기를 기다리지 않고 데이터를 점진적으로 처리할 수 있게 합니다. 이는 긴 텍스트에 대한 인지된 지연 시간을 크게 줄이고 실시간 애플리케이션을 가능하게 합니다. ElevenLabs 스트리밍 TTS는 또한 동적 텍스트 생성 시나리오를 위한 고급 청크 스트리밍 기능을 지원합니다.
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
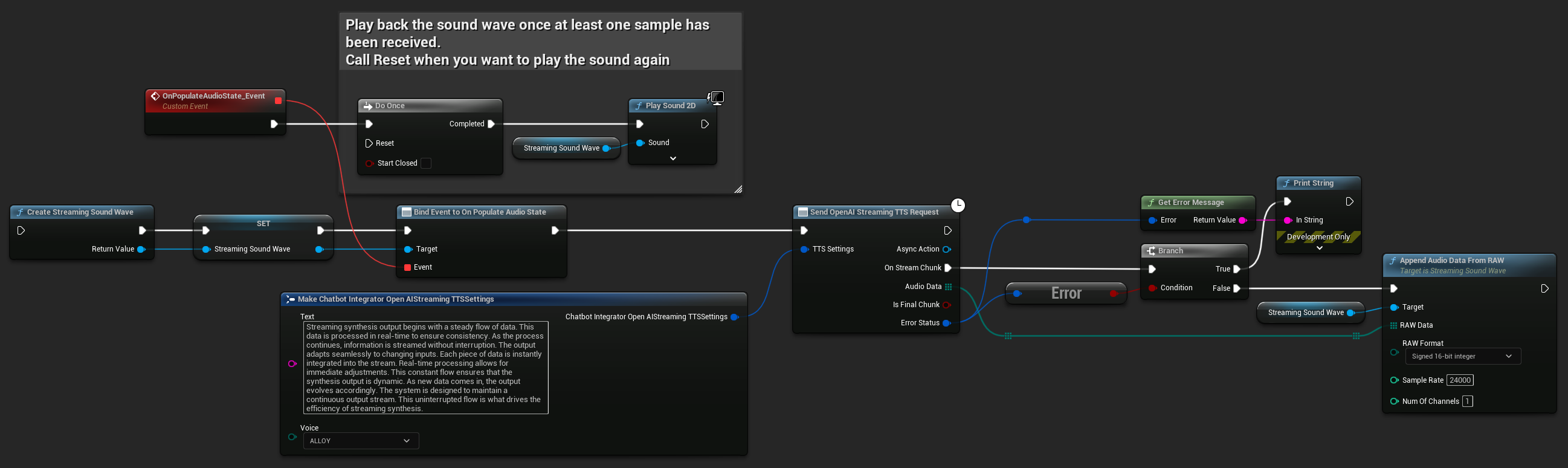
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
ElevenLabs Streaming TTS는 표준 스트리밍 모드와 고급 청크 스트리밍 모드를 모두 지원하여 다양한 사용 사례에 유연성을 제공합니다.
표준 스트리밍 모드
표준 스트리밍 모드는 미리 정의된 텍스트를 처리하고 생성되는 대로 오디오 청크를 전달합니다.
- Blueprint
- C++
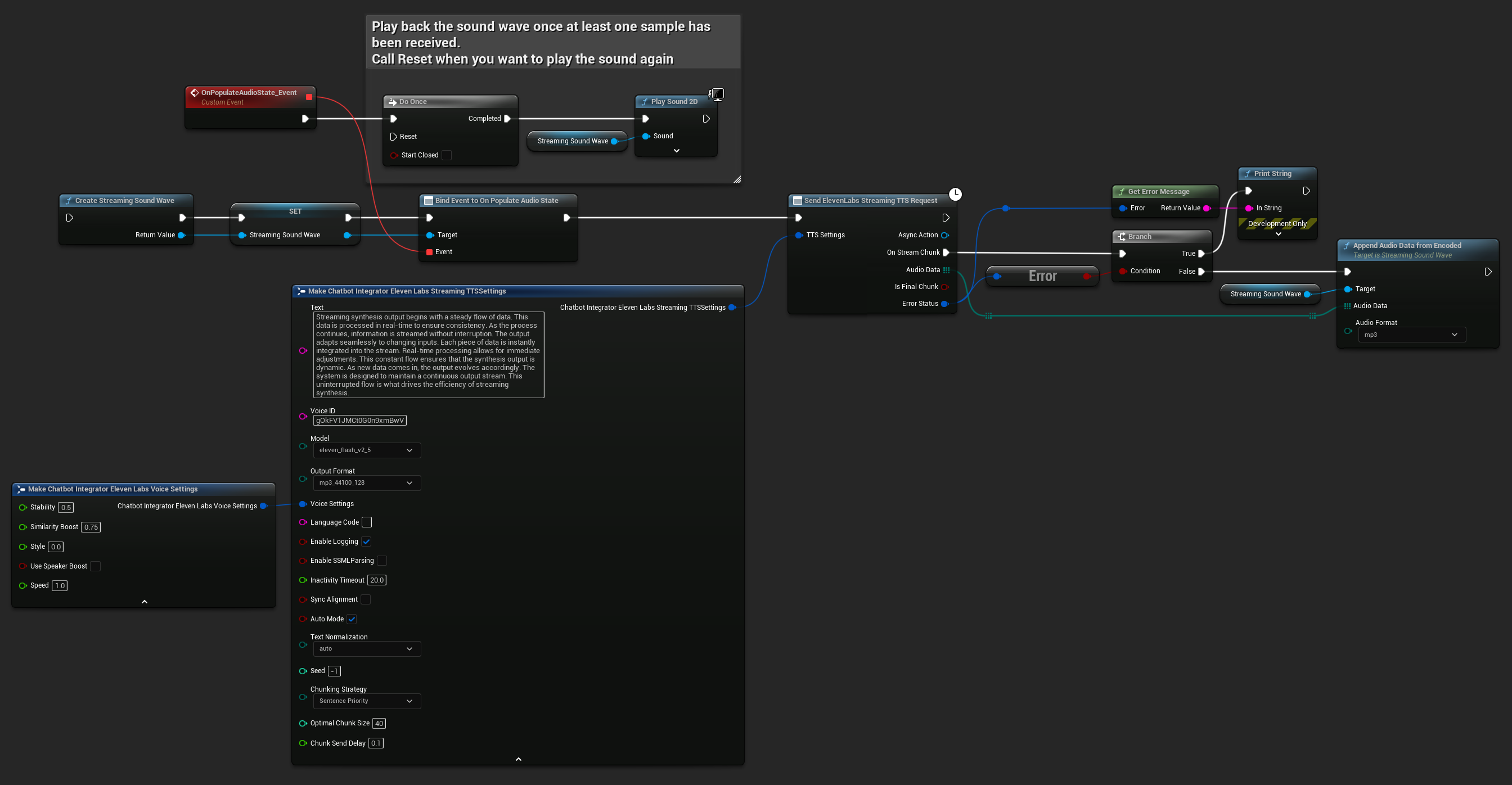
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
청크 스트리밍 모드
청크 스트리밍 모드를 사용하면 합성 중에 텍스트를 동적으로 추가할 수 있어, 텍스트가 점진적으로 생성되는 실시간 애플리케이션(예: 생성되는 대로 합성되는 AI 채팅 응답)에 이상적입니다. 이 모드를 활성화하려면 TTS 설정에서 bEnableChunkedStreaming을 true로 설정하세요.
- Blueprint
- C++
초기 설정: TTS 설정에서 청크 스트리밍 모드를 활성화하고 초기 요청을 생성하여 청크 스트리밍을 설정합니다. 요청 함수는 청크 스트리밍 세션을 관리하는 메서드를 제공하는 비동기 액션 객체를 반환합니다:
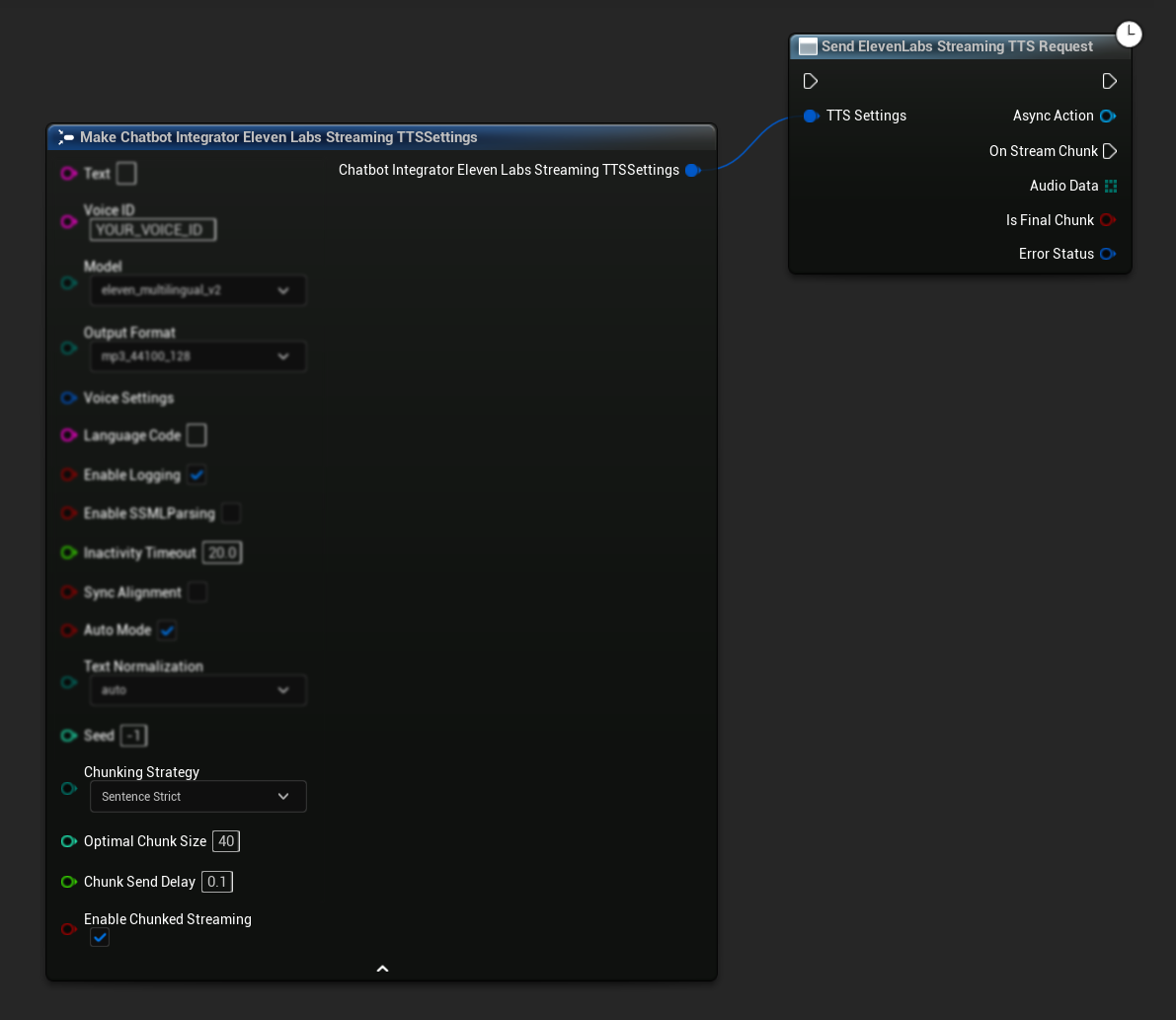
합성을 위한 텍스트 추가:
반환된 비동기 액션 객체에서 이 함수를 사용하여 활성 청크 스트리밍 세션 중에 텍스트를 동적으로 추가하세요. bContinuousMode 매개변수는 텍스트가 처리되는 방식을 제어합니다:

bContinuousMode가true일 때: 텍스트는 완전한 문장 경계(마침표, 느낌표, 물음표)가 감지될 때까지 내부적으로 버퍼링됩니다. 시스템은 자동으로 완전한 문장을 추출하여 합성하는 동시에 불완전한 텍스트를 버퍼에 유지합니다. 텍스트가 조각이나 부분 단어로 도착하고 문장 완성이 불확실할 때 이 모드를 사용하세요.bContinuousMode가false일 때: 텍스트는 버퍼링이나 문장 경계 분석 없이 즉시 처리됩니다. 각 호출은 즉각적인 청크 처리와 합성으로 이어집니다. 사전에 형성된 완전한 문장이나 구가 있고 경계 감지가 필요하지 않을 때 이 모드를 사용하세요.
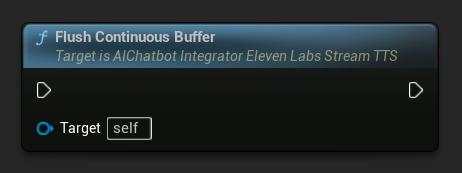
연속 버퍼 플러시: 비동기 액션 객체에서 문장 경계가 감지되지 않았더라도 버퍼링된 연속 텍스트의 처리를 강제합니다. 더 이상 텍스트가 오지 않을 것임을 알고 있을 때 유용합니다:
연속 플러시 타임아웃 설정: 비동기 액션 객체에서 지정된 타임아웃 내에 새 텍스트가 도착하지 않을 때 연속 버퍼의 자동 플러시를 구성합니다:
자동 플러시를 비활성화하려면 0으로 설정하세요. 실시간 애플리케이션의 경우 권장 값은 1-3초입니다.
청크 스트리밍 완료: 비동기 액션 객체에서 청크 스트리밍 세션을 닫고 현재 합성을 최종으로 표시합니다. 텍스트 추가를 완료했을 때 항상 이 함수를 호출하세요:
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
ElevenLabs 청킹 스트리밍의 주요 기능:
- 연속 모드:
bContinuousMode가true일 때, 텍스트는 완전한 문장 경계가 감지될 때까지 버퍼링된 후 합성을 위해 처리됩니다 - 즉시 모드:
bContinuousMode가false일 때, 텍스트는 버퍼링 없이 별도의 청크로 즉시 처리됩니다 - 자동 플러시: 구성 가능한 타임아웃은 지정된 시간 내에 새로운 입력이 도착하지 않으면 버퍼링된 텍스트를 처리합니다
- 문장 경계 감지: 문장 끝(., !, ?)을 감지하고 버퍼링된 텍스트에서 완전한 문장을 추출합니다
- 실시간 통합: 시간이 지남에 따라 조각으로 내용이 도착하는 증분 텍스트 입력을 지원합니다
- 유연한 텍스트 청킹: 합성 처리를 최적화하기 위해 여러 전략(문장 우선, 문장 엄격, 크기 기반)을 사용할 수 있습니다
사용 가능한 음성 가져오기
일부 TTS 제공업체는 사용 가능한 음성을 프로그래밍 방식으로 발견할 수 있는 음성 목록 API를 제공합니다.
- Google Cloud Voices
- Azure Voices
- Blueprint
- C++
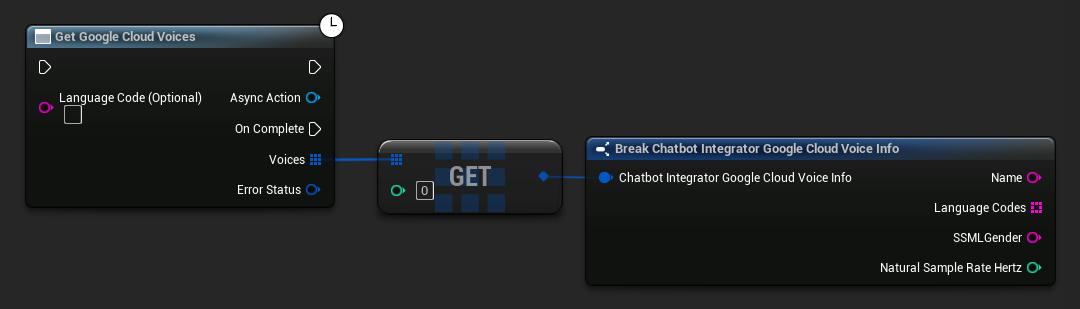
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
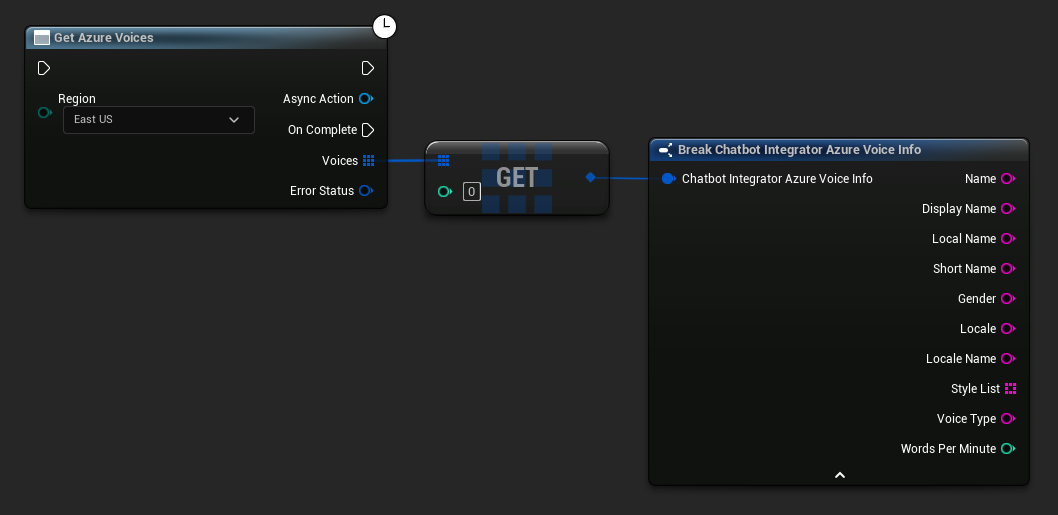
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
Ollama 모델 목록 조회
ListOllamaModels 함수를 사용하여 로컬 Ollama 인스턴스에서 사용 가능한 모든 모델을 조회할 수 있습니다. 이는 UI에서 모델 선택기를 동적으로 채우는 등에 유용할 수 있습니다. GetModelNames 헬퍼는 편의를 위해 결과에서 이름 문자열만 추출합니다.
- Blueprint
- C++
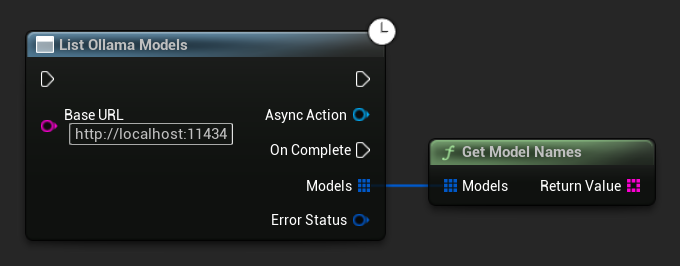
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
오류 처리
요청을 보낼 때는 콜백에서 ErrorStatus를 확인하여 잠재적인 오류를 처리하는 것이 중요합니다. ErrorStatus는 요청 중 발생할 수 있는 문제에 대한 정보를 제공합니다.
- Blueprint
- C++
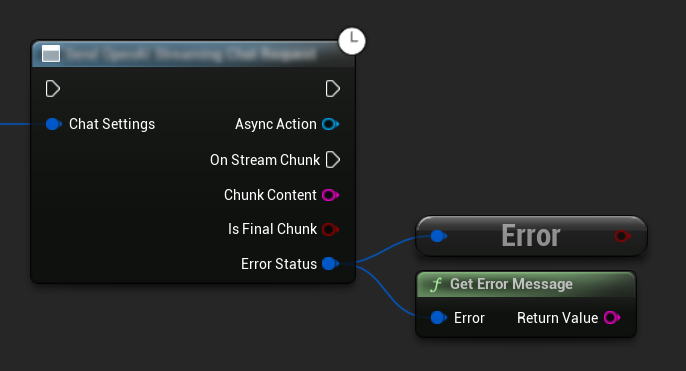
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
요청 취소
이 플러그인은 진행 중인 텍스트-텍스트 및 TTS 요청을 모두 취소할 수 있도록 합니다. 이는 장시간 실행되는 요청을 중단하거나 대화 흐름을 동적으로 변경하고자 할 때 유용할 수 있습니다.
- Blueprint
- C++
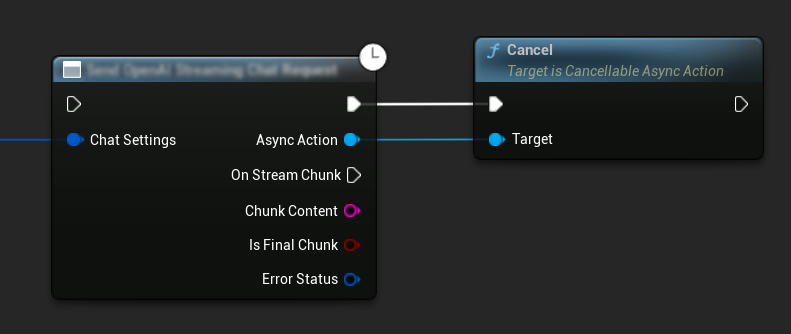
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
모범 사례
- 콜백에서
ErrorStatus를 확인하여 잠재적 오류를 항상 처리하세요 - 각 제공업체별 API 속도 제한 및 비용에 유의하세요
- 장문 또는 대화형 대화에는 스트리밍 모드를 사용하세요
- 더 이상 필요하지 않은 요청을 취소하여 리소스를 효율적으로 관리하세요
- 긴 텍스트에는 스트리밍 TTS를 사용하여 인지된 지연 시간을 줄이세요
- 오디오 처리의 경우 Runtime Audio Importer 플러그인이 편리한 솔루션을 제공하지만, 프로젝트 요구 사항에 따라 맞춤형 처리를 구현할 수 있습니다
- 추론 모델(DeepSeek Reasoner, Grok)을 사용할 때는 추론 출력과 콘텐츠 출력을 모두 적절히 처리하세요
- TTS 기능을 구현하기 전에 음성 목록 API를 사용하여 사용 가능한 음성을 확인하세요
- ElevenLabs 청크 스트리밍의 경우: 텍스트가 점진적으로 생성될 때(예: AI 응답)는 연속 모드를 사용하고, 미리 형성된 텍스트 청크에는 즉시 모드를 사용하세요
- 연속 모드의 경우 응답성과 자연스러운 음성 흐름 사이의 균형을 맞추기 위해 적절한 플러시 타임아웃을 구성하세요
- 애플리케이션의 실시간 요구 사항에 따라 최적의 청크 크기와 전송 지연 시간을 선택하세요
- Ollama의 경우: 모델 이름을 하드코딩하기보다
ListOllamaModels를 사용하여 사용 가능한 모델을 동적으로 탐색하세요
문제 해결
- 각 제공업체에 대한 API 자격 증명이 올바른지 확인하세요
- 인터넷 연결을 확인하세요
- TTS 기능 작업 시 사용하는 모든 오디오 처리 라이브러리(예: Runtime Audio Importer)가 올바르게 설치되어 있는지 확인하세요
- TTS 응답 데이터를 처리할 때 올바른 오디오 형식을 사용하고 있는지 확인하세요
- 스트리밍 TTS의 경우 오디오 청크를 올바르게 처리하고 있는지 확인하세요
- 추론 모델의 경우 추론 출력과 콘텐츠 출력을 모두 처리하고 있는지 확인하세요
- 모델 가용성 및 기능에 대한 제공업체별 문서를 확인하세요
- ElevenLabs 청크 스트리밍의 경우: 세션을 올바르게 닫으려면 작업 완료 시
FinishChunkedStreaming을 호출하세요 - 연속 모드 문제의 경우: 텍스트에서 문장 경계가 올바르게 감지되는지 확인하세요
- 실시간 애플리케이션의 경우: 지연 시간 요구 사항에 따라 청크 전송 지연 시간과 플러시 타임아웃을 조정하세요
- Ollama의 경우: 요청을 보내기 전에 구성된
BaseUrl에서 Ollama 서버가 실행 중이고 접근 가능한지 확인하세요