プラグインの使用方法
Runtime AI Chatbot Integrator は、主に2つの機能を提供します:テキスト対テキストチャットとテキスト読み上げ(TTS)。両機能とも同様のワークフローに従います:
- APIプロバイダートークンを登録する
- 機能固有の設定を構成する
- リクエストを送信し、レスポンスを処理する
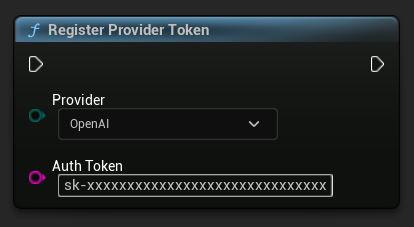
プロバイダートークンの登録
リクエストを送信する前に、RegisterProviderToken 関数を使用してAPIプロバイダートークンを登録してください。
Ollamaはローカルで動作し、APIトークンを必要としません。Ollamaの場合はこのステップをスキップできます。
- Blueprint
- C++
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
テキスト対テキストチャット機能
このプラグインは、各プロバイダーに対して2つのチャットリクエストモードをサポートしています:
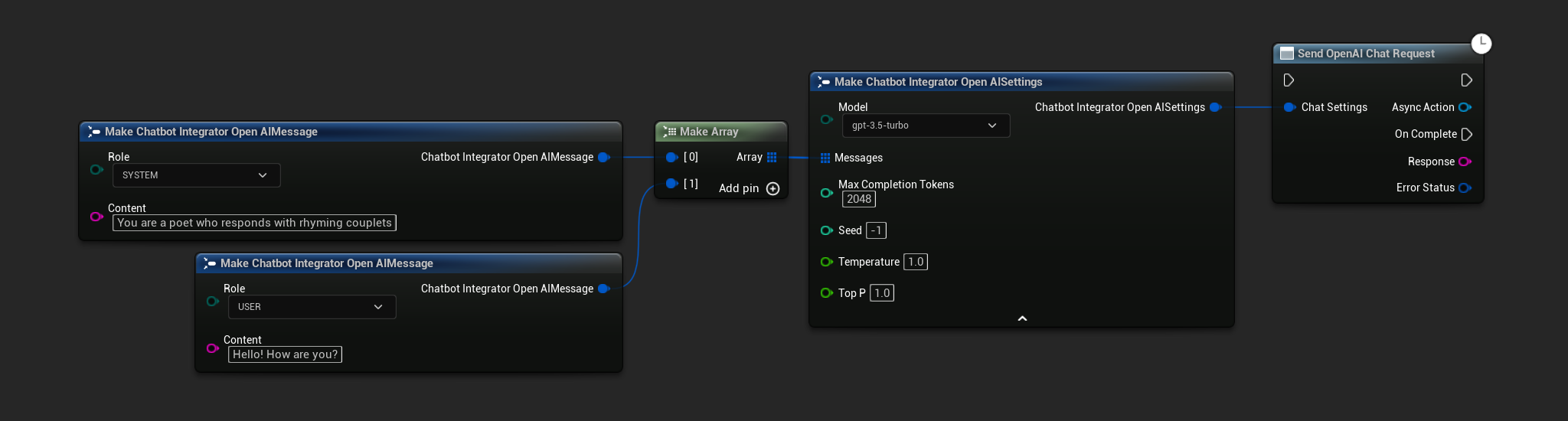
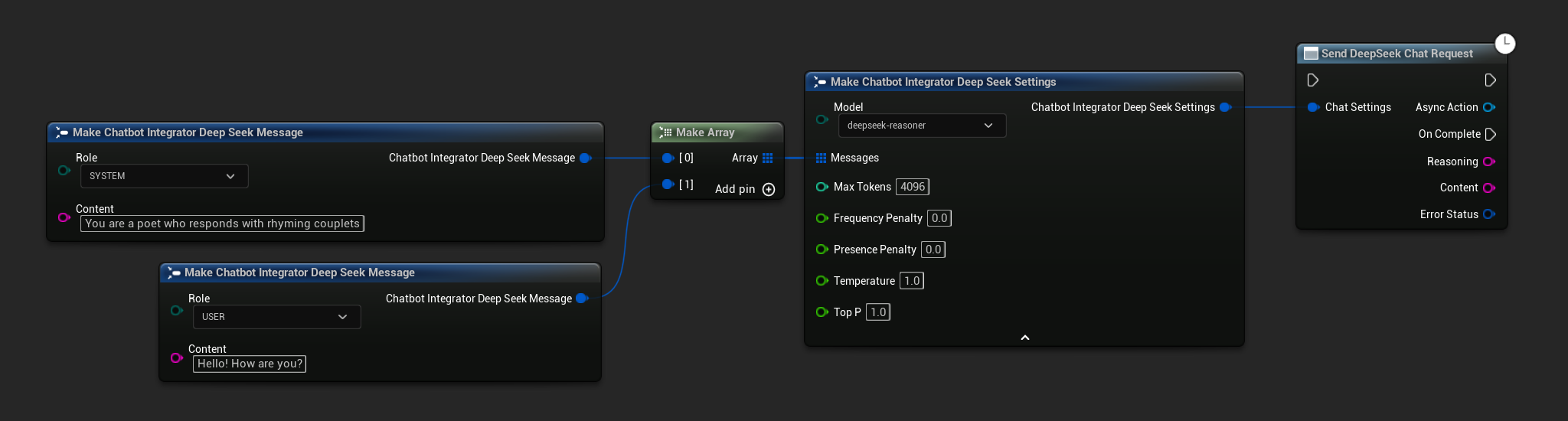
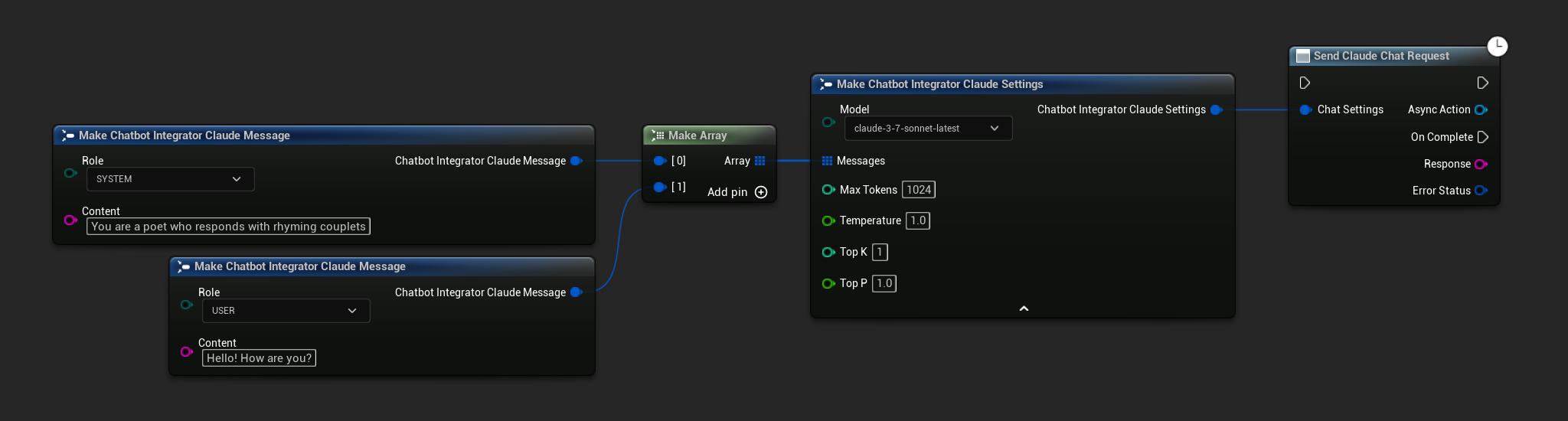
非ストリーミングチャットリクエスト
単一の呼び出しで完全な応答を取得します。
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
ストリーミングチャットリクエスト
よりダイナミックなインタラクションのために、リアルタイムでレスポンスのチャンクを受信します。
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
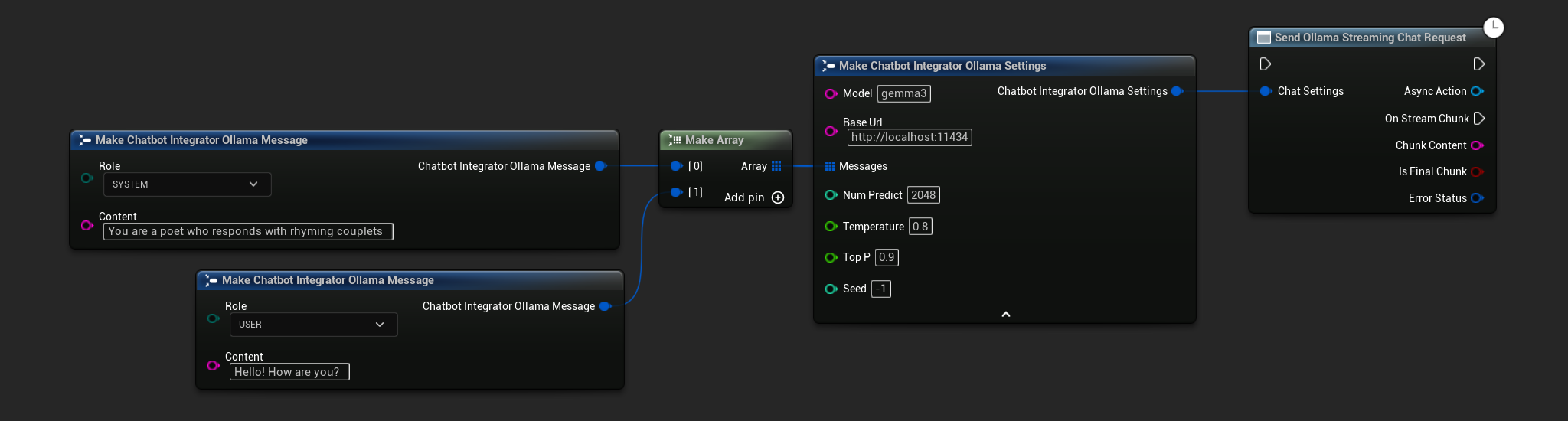
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
テキスト読み上げ (TTS) 機能
主要なTTSプロバイダーを使用して、テキストを高品質な音声オーディオに変換します。このプラグインは生のオーディオデータ (TArray<uint8>) を返すため、プロジェクトのニーズに応じて処理できます。
以下の例では、Runtime Audio Importer プラグインを使用した再生用のオーディオ処理をデモンストレーションしています(オーディオインポートのドキュメントを参照)。しかし、Runtime AI Chatbot Integratorは柔軟に設計されています。このプラグインは単に生のオーディオデータを返すため、特定のユースケースに応じて、オーディオ再生、ファイルへの保存、さらなるオーディオ処理、他のシステムへの送信、カスタムビジュアライゼーションなど、どのように処理するかは完全に自由です。
非ストリーミングTTSリクエスト
非ストリーミングTTSリクエストは、テキスト全体が処理された後、完全なオーディオデータを単一の応答で返します。このアプローチは、完全なオーディオを待っても問題ない短いテキストに適しています。
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
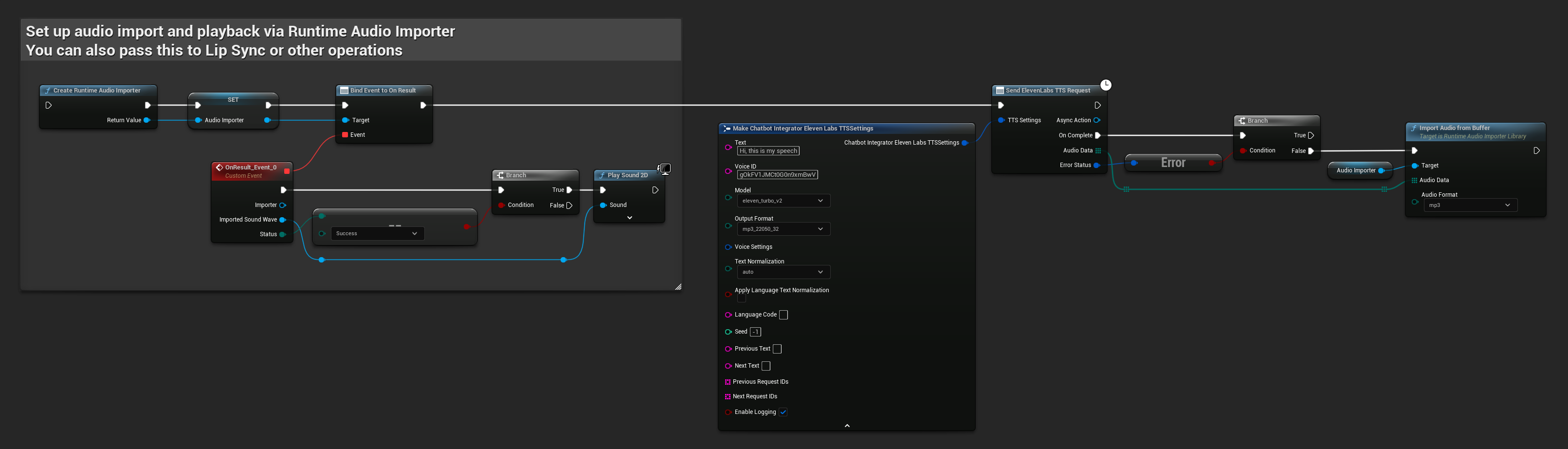
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
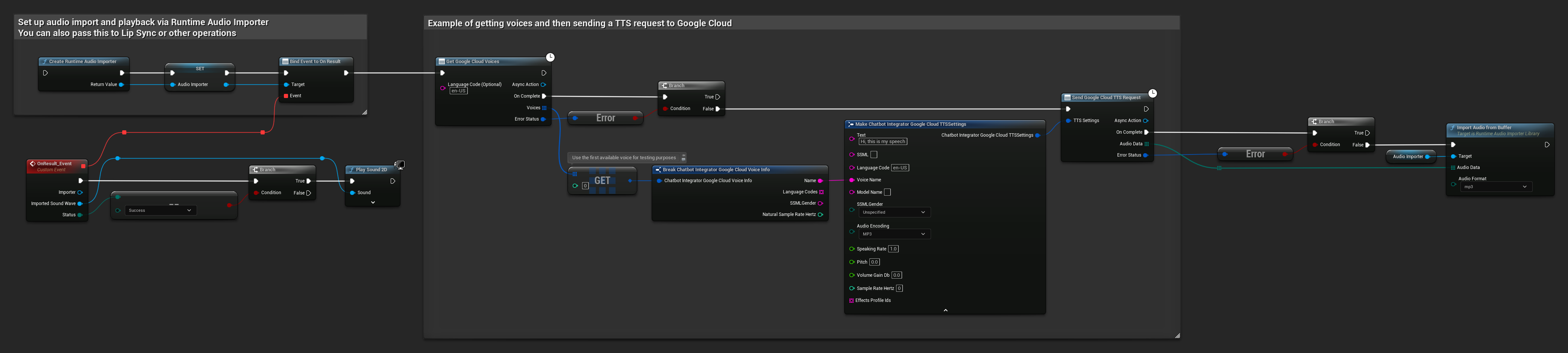
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
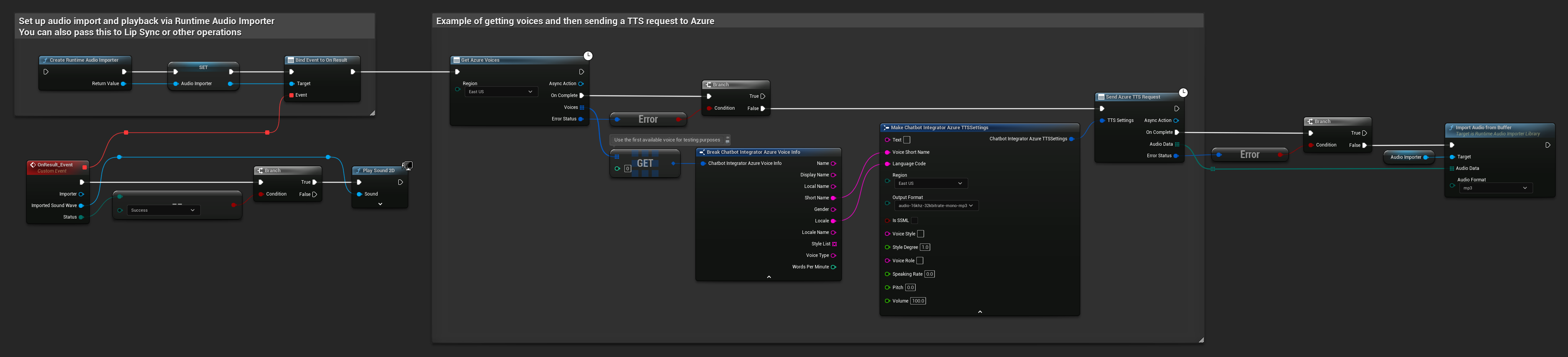
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
ストリーミングTTSリクエスト
ストリーミングTTSは、オーディオチャンクが生成されると同時に配信し、オーディオ全体が合成されるのを待つことなく、データを段階的に処理できるようにします。これにより、長いテキストに対する知覚される遅延が大幅に減少し、リアルタイムアプリケーションが可能になります。ElevenLabs Streaming TTSは、動的なテキスト生成シナリオのための高度なチャンクストリーミング機能もサポートしています。
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
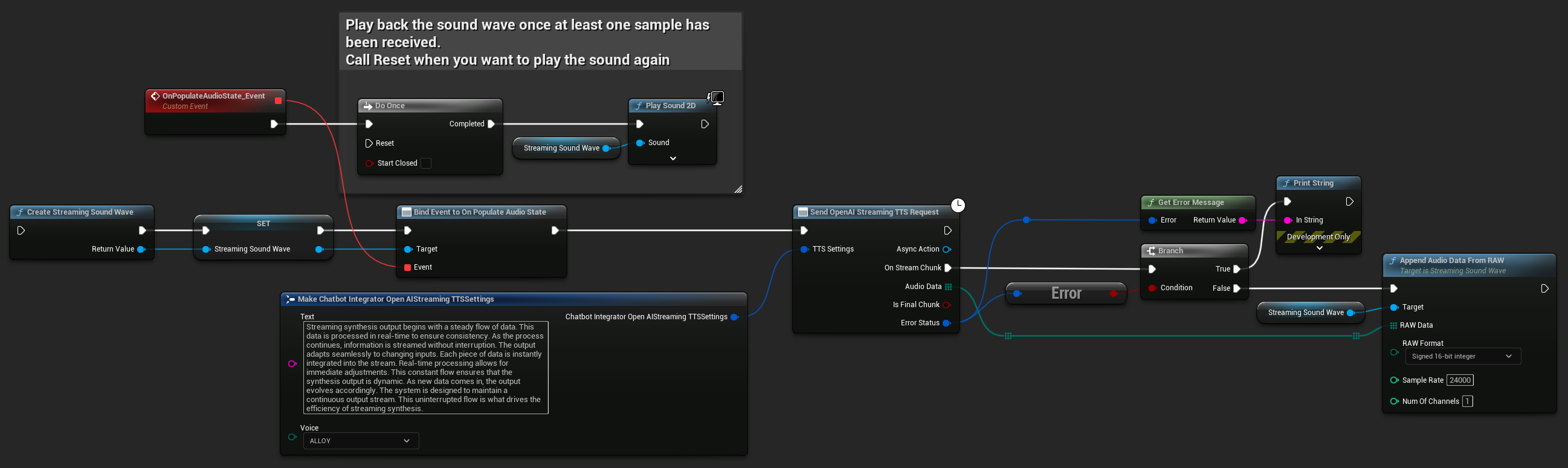
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
ElevenLabs Streaming TTSは、標準的なストリーミングモードと高度なチャンクストリーミングモードの両方をサポートしており、さまざまなユースケースに柔軟に対応できます。
標準ストリーミングモード
標準ストリーミングモードは、事前に定義されたテキストを処理し、生成されたオーディオチャンクを配信します。
- Blueprint
- C++
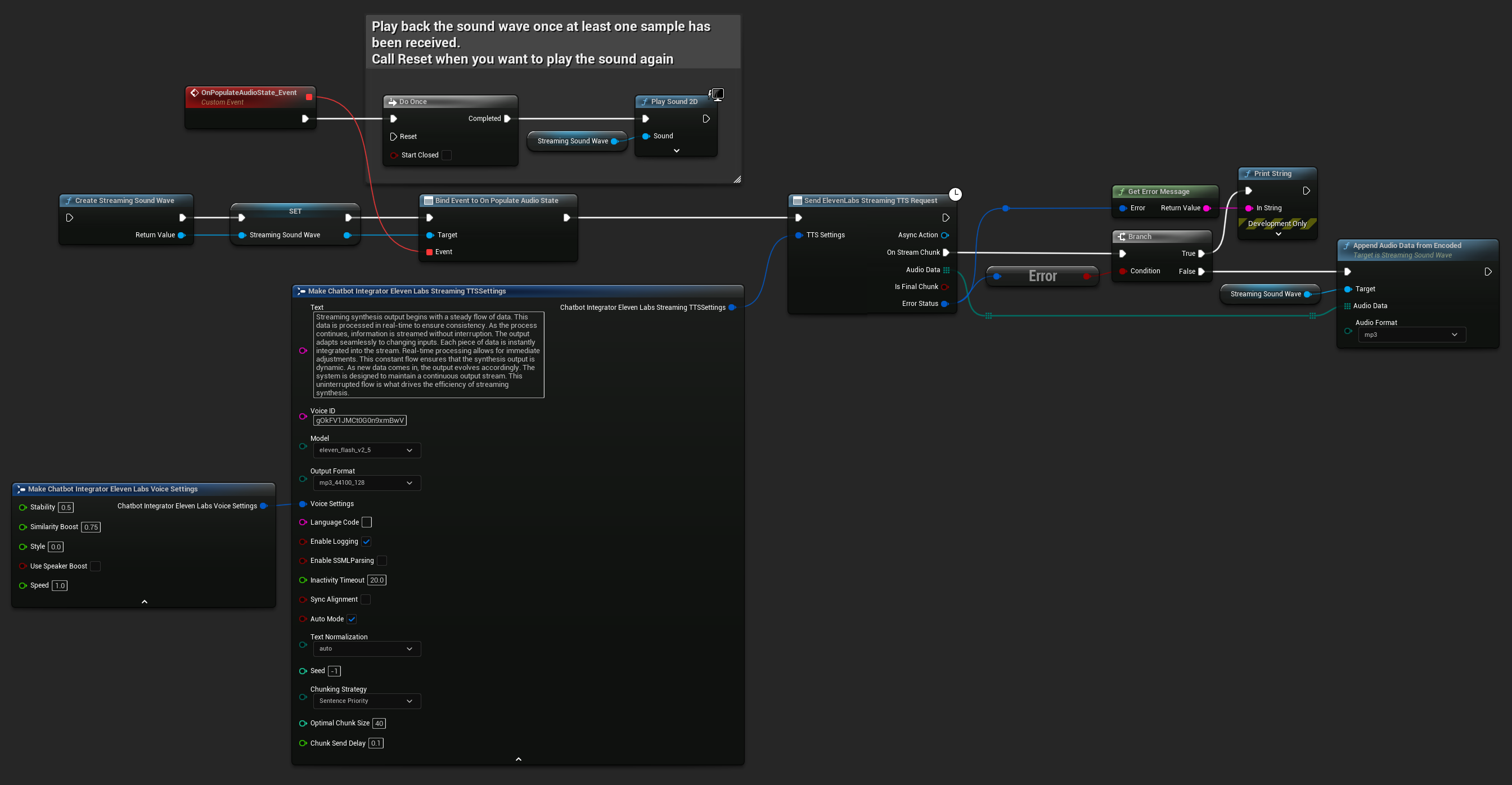
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
チャンクストリーミングモード
チャンクストリーミングモードでは、合成中にテキストを動的に追加できます。これは、テキストが段階的に生成されるリアルタイムアプリケーション(例:生成されながら合成されるAIチャット応答)に最適です。このモードを有効にするには、TTS設定で bEnableChunkedStreaming を true に設定します。
- Blueprint
- C++
初期設定: TTS設定でチャンクストリーミングモードを有効にし、初期リクエストを作成してチャンクストリーミングをセットアップします。リクエスト関数は、チャンクストリーミングセッションを管理するためのメソッドを提供する非同期アクションオブジェクトを返します:
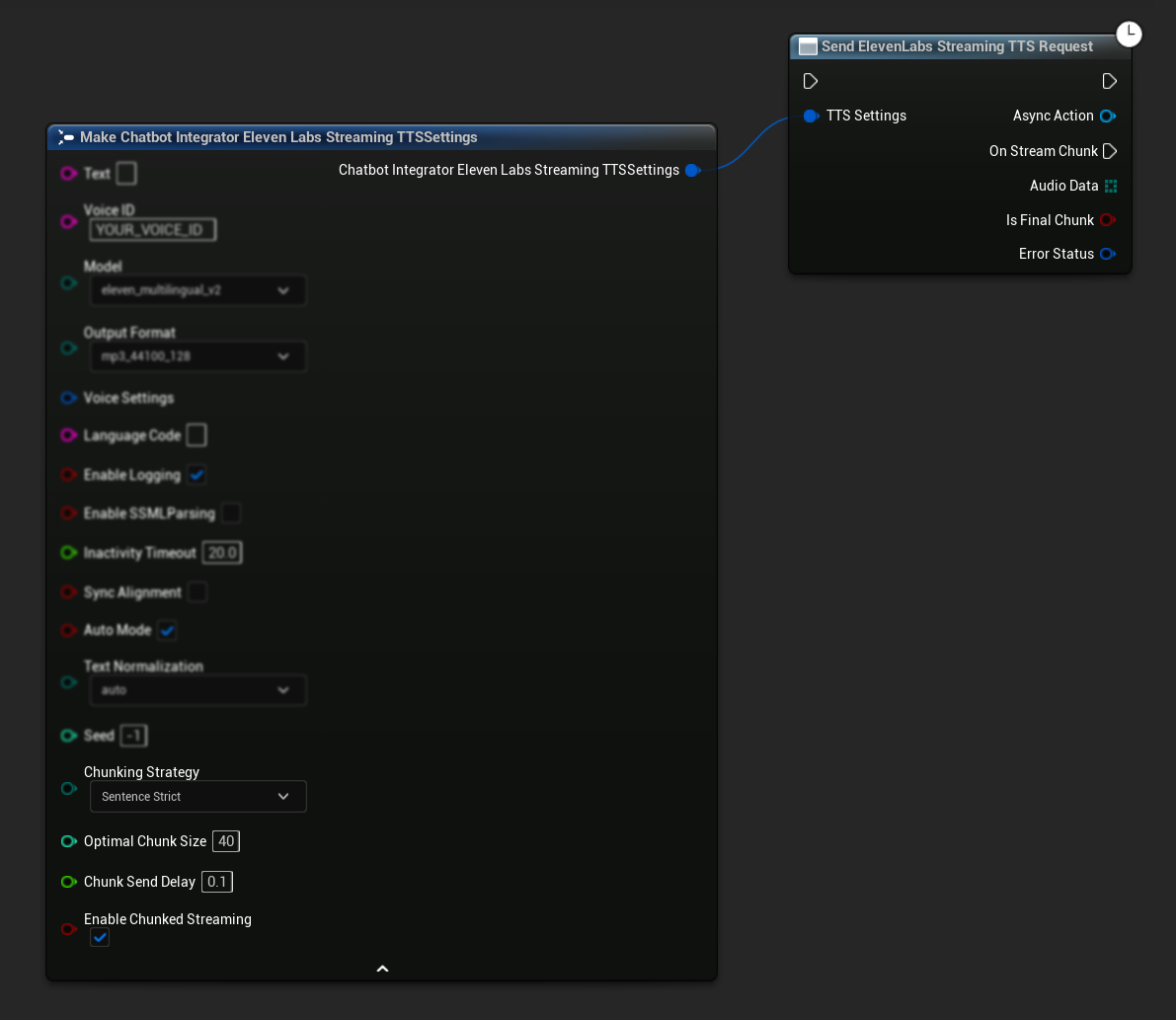
合成用テキストの追加:
返された非同期アクションオブジェクトでこの関数を使用して、アクティブなチャンクストリーミングセッション中に動的にテキストを追加します。bContinuousMode パラメータは、テキストの処理方法を制御します:

bContinuousModeがtrueの場合:テキストは内部でバッファリングされ、完全な文の境界(ピリオド、感嘆符、疑問符)が検出されるまで保持されます。システムは自動的に完全な文を抽出して合成し、不完全なテキストはバッファに保持します。テキストが断片や部分的な単語として到着し、文の完了が不確実な場合に使用します。bContinuousModeがfalseの場合:テキストはバッファリングや文の境界分析なしですぐに処理されます。各呼び出しは即時のチャンク処理と合成を引き起こします。事前に形成された完全な文やフレーズがあり、境界検出を必要としない場合に使用します。
連続バッファのフラッシュ: 非同期アクションオブジェクト上で、文の境界が検出されていなくても、バッファリングされた連続テキストの処理を強制します。しばらくテキストが来ないことがわかっている場合に便利です:
連続フラッシュタイムアウトの設定: 指定されたタイムアウト内に新しいテキストが到着しない場合、非同期アクションオブジェクト上の連続バッファの自動フラッシュを設定します:
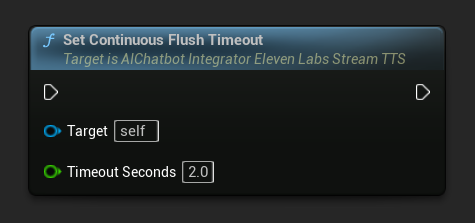
自動フラッシュを無効にするには0に設定します。リアルタイムアプリケーションでは1〜3秒が推奨値です。
チャンクストリーミングの終了: 非同期アクションオブジェクト上のチャンクストリーミングセッションを閉じ、現在の合成を最終的なものとしてマークします。テキストの追加が完了したら常にこれを呼び出してください:
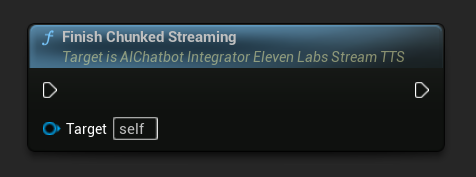
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
ElevenLabs チャンクストリーミングの主な機能:
- 連続モード:
bContinuousModeがtrueの場合、テキストは完全な文の境界が検出されるまでバッファリングされ、その後合成のために処理されます - 即時モード:
bContinuousModeがfalseの場合、テキストはバッファリングせずに個別のチャンクとして即座に処理されます - 自動フラッシュ: 設定可能なタイムアウトにより、指定された時間枠内に新しい入力が到着しない場合、バッファリングされたテキストが処理されます
- 文境界検出: 文の終わり(.、!、?)を検出し、バッファリングされたテキストから完全な文を抽出します
- リアルタイム統合: コンテンツが時間の経過とともに断片として到着する、インクリメンタルなテキスト入力をサポートします
- 柔軟なテキストチャンキング: 合成処理を最適化するための複数の戦略(文優先、文厳密、サイズベース)が利用可能です
利用可能な音声の取得
一部の TTS プロバイダーは、利用可能な音声をプログラムで発見するための音声一覧 API を提供しています。
- Google Cloud Voices
- Azure Voices
- Blueprint
- C++
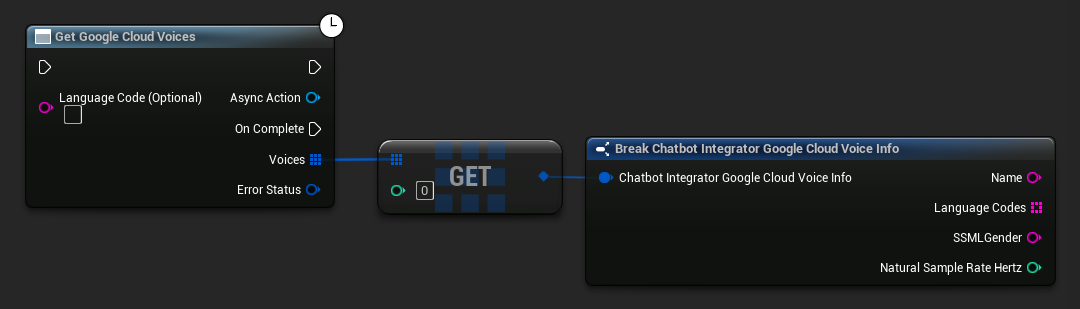
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
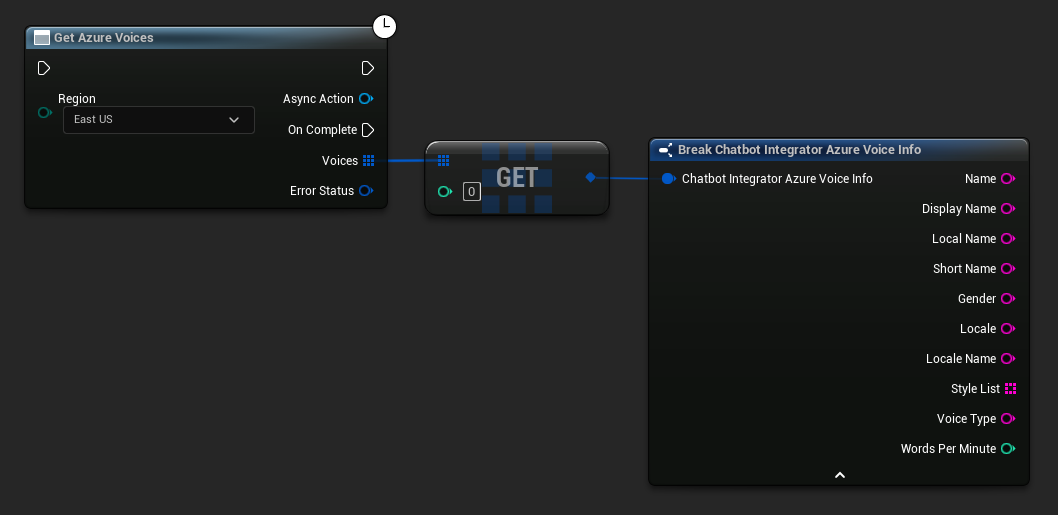
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
Ollamaモデルの一覧表示
ローカルのOllamaインスタンスで利用可能なすべてのモデルを、ListOllamaModels関数を使用して照会できます。これは、UIのモデルピッカーを動的に作成する場合などに便利です。GetModelNamesヘルパーは、結果から名前の文字列だけを抽出して利便性を高めます。
- Blueprint
- C++
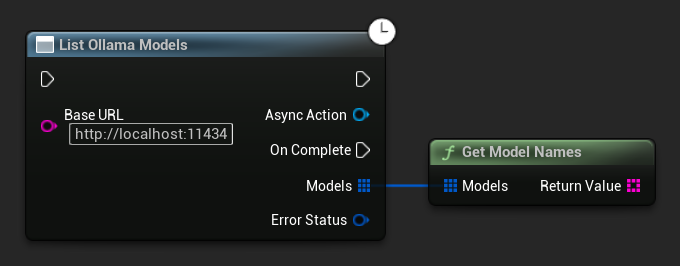
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
エラー処理
リクエストを送信する際は、コールバック内で ErrorStatus をチェックして潜在的なエラーを処理することが重要です。ErrorStatus は、リクエスト中に発生する可能性のある問題に関する情報を提供します。
- Blueprint
- C++
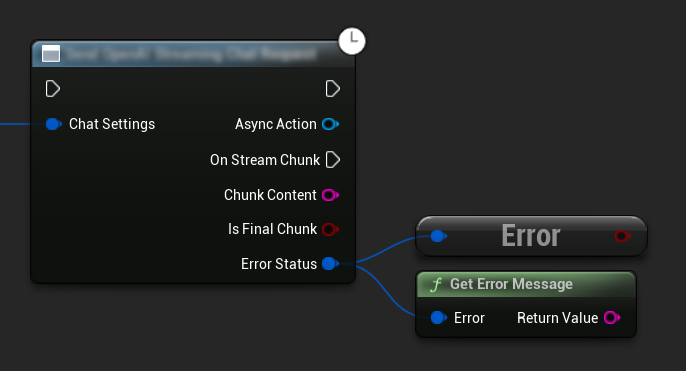
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
リクエストのキャンセル
このプラグインでは、進行中のテキスト対テキストおよびTTSリクエストの両方をキャンセルすることができます。これは、長時間実行されているリクエストを中断したい場合や、会話の流れを動的に変更したい場合に便利です。
- Blueprint
- C++
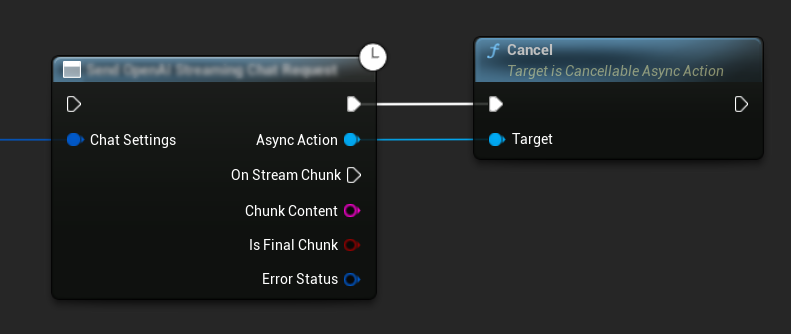
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
ベストプラクティス
- コールバック内で
ErrorStatusをチェックし、潜在的なエラーを常に処理する - 各プロバイダーのAPIレート制限とコストに注意する
- 長文やインタラクティブな会話にはストリーミングモードを使用する
- 不要になったリクエストはキャンセルしてリソースを効率的に管理することを検討する
- 長いテキストにはストリーミングTTSを使用して、体感される遅延を減らす
- オーディオ処理には、Runtime Audio Importerプラグインが便利な解決策を提供しますが、プロジェクトのニーズに基づいてカスタム処理を実装することも可能です
- 推論モデル(DeepSeek Reasoner、Grok)を使用する場合は、推論出力とコンテンツ出力の両方を適切に処理する
- TTS機能を実装する前に、音声一覧取得APIを使用して利用可能な音声を確認する
- ElevenLabsのチャンクストリーミングの場合: テキストが段階的に生成される場合(AI応答など)は連続モードを、事前に形成されたテキストチャンクには即時モードを使用する
- 連続モードでは、応答性と自然な音声の流れのバランスを取るために適切なフラッシュタイムアウトを設定する
- アプリケーションのリアルタイム要件に基づいて、最適なチャンクサイズと送信遅延を選択する
- Ollamaの場合: モデル名をハードコードするのではなく、
ListOllamaModelsを使用して利用可能なモデルを動的に検出する
トラブルシューティング
- 各プロバイダーのAPI認証情報が正しいことを確認する
- インターネット接続を確認する
- TTS機能を扱う際、使用するオーディオ処理ライブラリ(Runtime Audio Importerなど)が適切にインストールされていることを確認する
- TTS応答データを処理する際に、正しいオーディオフォーマットを使用していることを確認する
- ストリーミングTTSの場合、オーディオチャンクを正しく処理していることを確認する
- 推論モデルの場合、推論出力とコンテンツ出力の両方を処理していることを確認する
- モデルの可用性と機能については、プロバイダー固有のドキュメントを確認する
- ElevenLabsのチャンクストリーミングの場合: 完了時に
FinishChunkedStreamingを呼び出してセッションを適切に閉じることを確認する - 連続モードの問題の場合: テキスト内の文の境界が適切に検出されていることを確認する
- リアルタイムアプリケーションの場合: レイテンシ要件に基づいてチャンク送信遅延とフラッシュタイムアウトを調整する
- Ollamaの場合: リクエストを送信する前に、設定された
BaseUrlでOllamaサーバーが実行され、アクセス可能であることを確認する