如何使用该插件
Runtime AI Chatbot Integrator 提供两大主要功能:文本到文本聊天和文本到语音转换。这两项功能遵循相似的工作流程:
- 注册您的 API 提供商令牌
- 配置特定功能设置
- 发送请求并处理响应
注册提供商令牌
在发送任何请求之前,请使用 RegisterProviderToken 函数注册您的 API 提供商令牌。
Ollama 在本地运行,不需要 API 令牌。对于 Ollama,您可以跳过此步骤。
- Blueprint
- C++
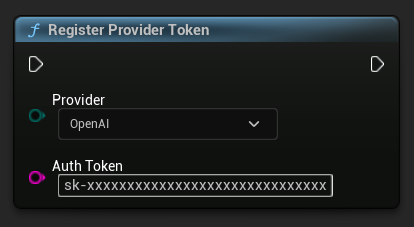
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
// Register other providers as needed
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::Anthropic,
TEXT("sk-ant-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::DeepSeek,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
etc
文本到文本聊天功能
该插件为每个提供商支持两种聊天请求模式:
非流式聊天请求
在一次调用中获取完整的响应。
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
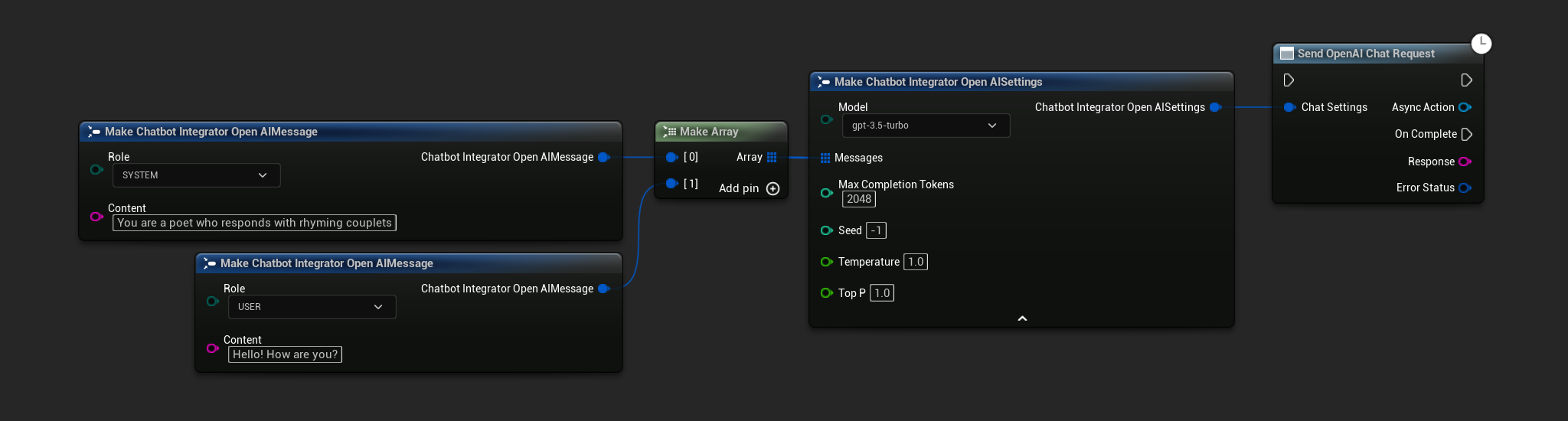
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
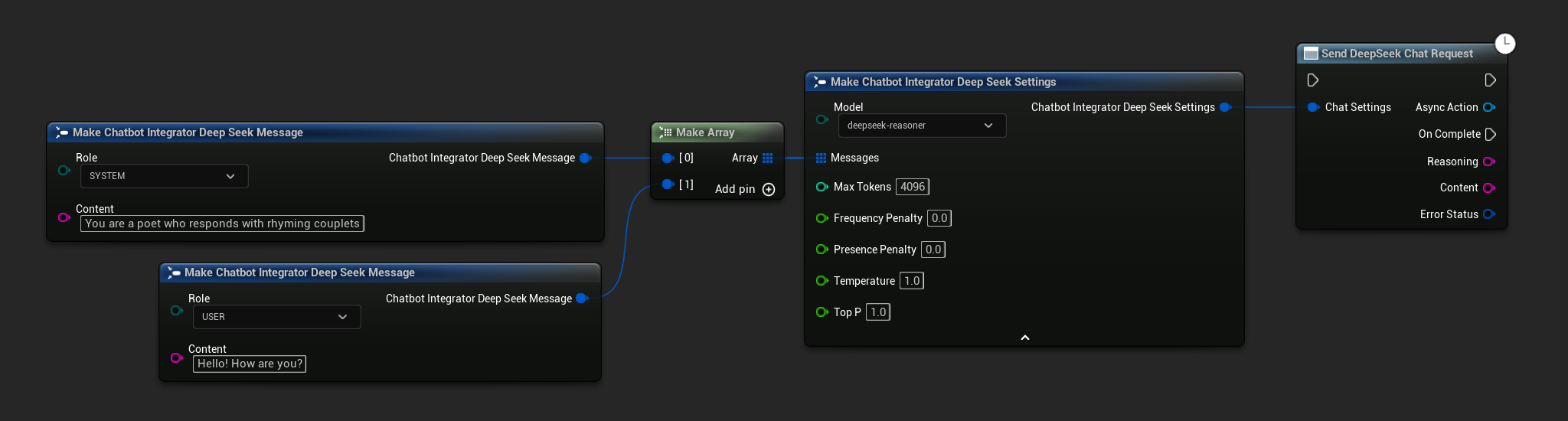
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
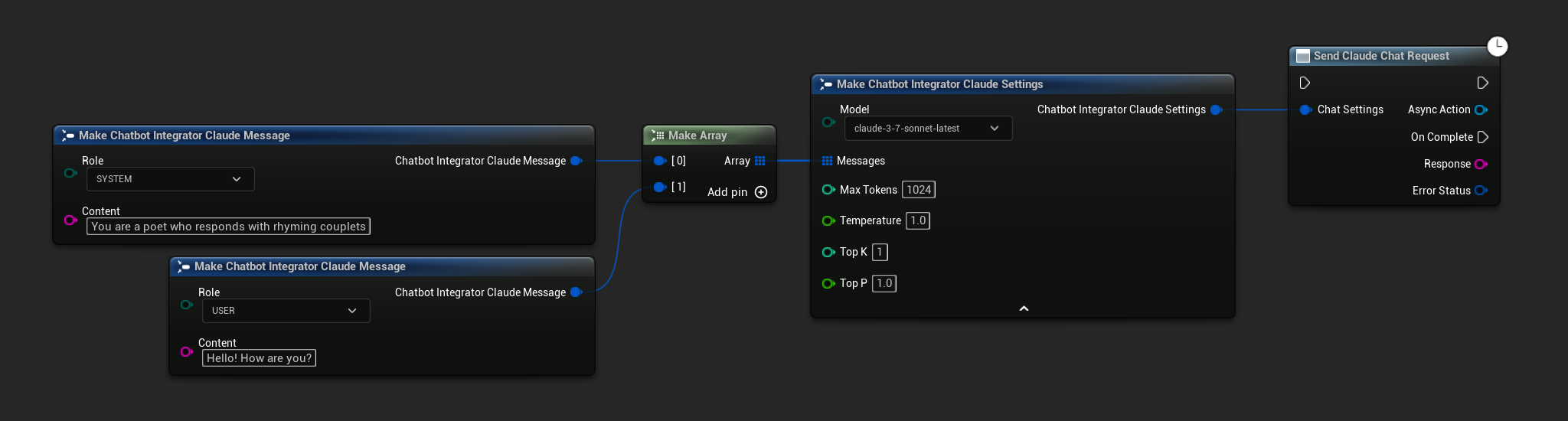
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaude::SendChatRequestNative(
Settings,
FOnClaudeChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGemini::SendChatRequestNative(
Settings,
FOnGeminiChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++

// Example of sending a non-streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrok::SendChatRequestNative(
Settings,
FOnGrokChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Response: %s, Error: %d: %s"),
*Reasoning, *Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a non-streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllama::SendChatRequestNative(
Settings,
FOnOllamaChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
流式聊天请求
实时接收响应数据块,实现更动态的交互。
- OpenAI
- DeepSeek
- Claude
- Gemini
- Grok
- Ollama
- Blueprint
- C++
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAIStreamingSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage{
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage{
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
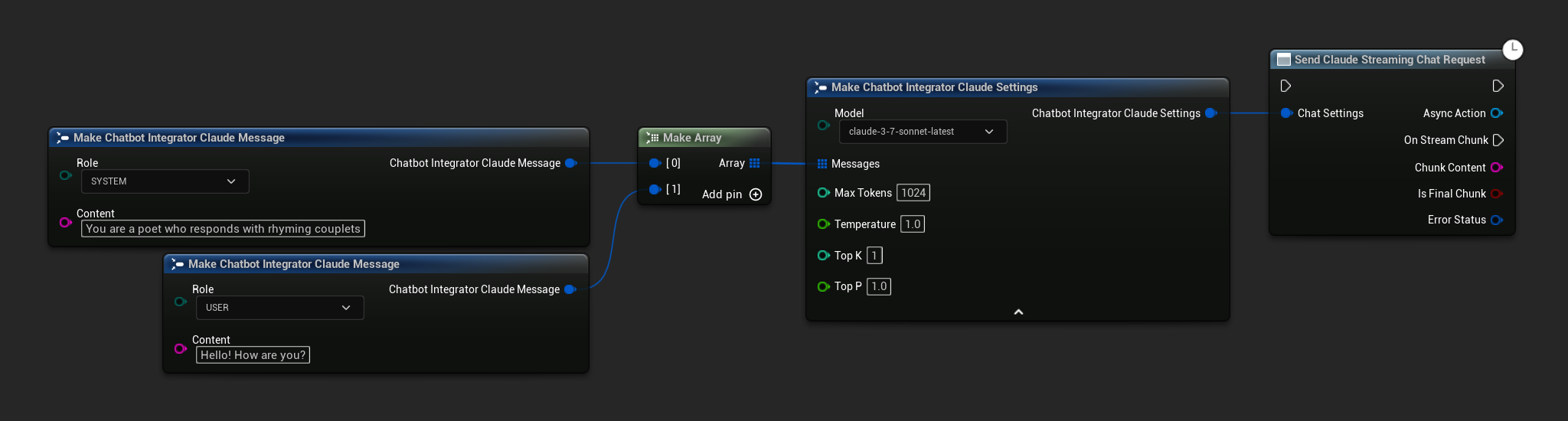
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage{
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
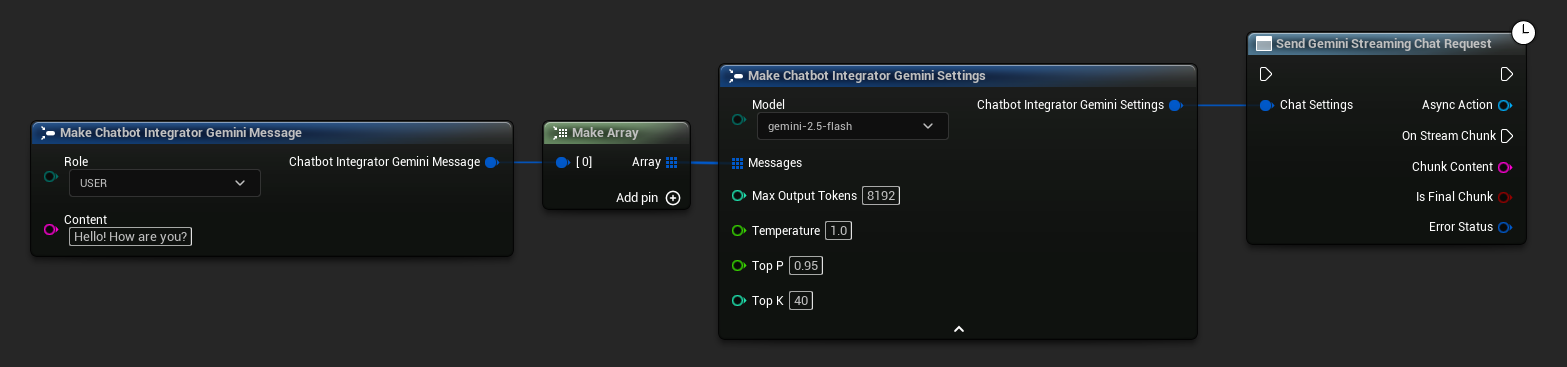
// Example of sending a streaming chat request to Gemini
FChatbotIntegrator_GeminiSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GeminiMessage{
EChatbotIntegrator_GeminiRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGeminiStream::SendStreamingChatRequestNative(
Settings,
FOnGeminiChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++

// Example of sending a streaming chat request to Grok
FChatbotIntegrator_GrokSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_GrokMessage{
EChatbotIntegrator_GrokRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorGrokStream::SendStreamingChatRequestNative(
Settings,
FOnGrokChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming reasoning: %s, content: %s, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
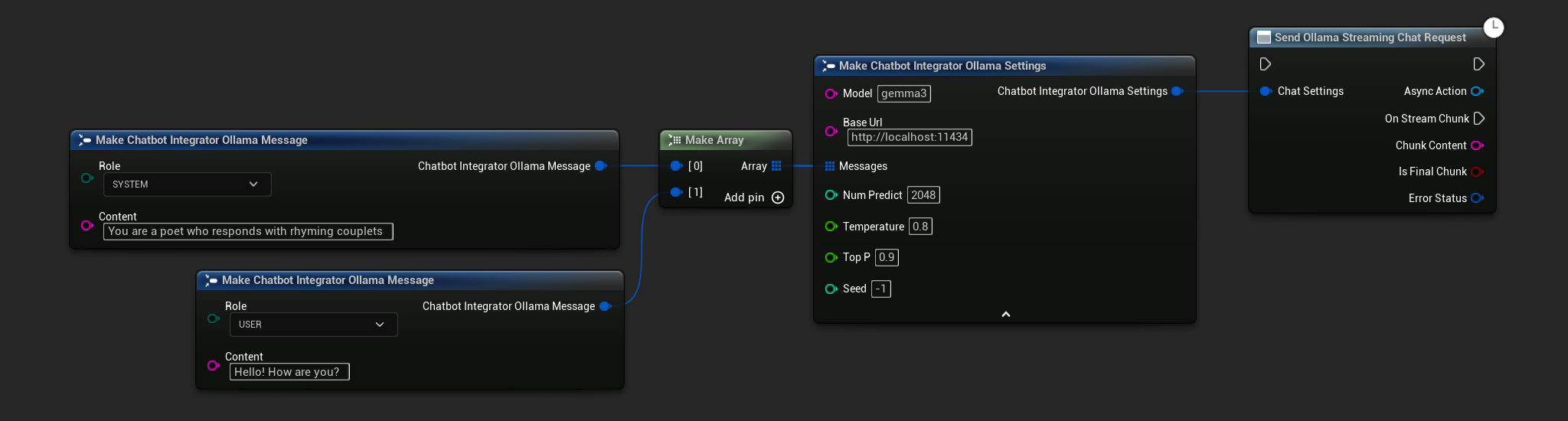
// Example of sending a streaming chat request to Ollama
FChatbotIntegrator_OllamaSettings Settings;
Settings.Model = TEXT("gemma3");
Settings.BaseUrl = TEXT("http://localhost:11434");
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::SYSTEM,
TEXT("You are a helpful assistant.")
});
Settings.Messages.Add(FChatbotIntegrator_OllamaMessage{
EChatbotIntegrator_OllamaRole::USER,
TEXT("What is the capital of France?")
});
UAIChatbotIntegratorOllamaStream::SendStreamingChatRequestNative(
Settings,
FOnOllamaChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ChunkContent, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat chunk: %s, IsFinalChunk: %d, Error: %d: %s"),
*ChunkContent, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
文本转语音 (TTS) 功能
使用领先的 TTS 提供商将文本转换为高质量的语音音频。该插件返回原始音频数据 (TArray<uint8>),您可以根据项目需求进行处理。
虽然下面的示例演示了使用 Runtime Audio Importer 插件进行音频播放处理(请参阅 音频导入文档),但 Runtime AI Chatbot Integrator 被设计为灵活的。该插件仅返回原始音频数据,让您在处理特定用例时拥有完全的自由度,这可能包括音频播放、保存到文件、进一步的音频处理、传输到其他系统、自定义可视化等等。
非流式 TTS 请求
非流式 TTS 请求在整个文本处理完成后,在单个响应中返回完整的音频数据。这种方法适用于等待完整音频不成问题的较短文本。
- OpenAI TTS
- ElevenLabs TTS
- Google Cloud TTS
- Azure TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnOpenAITTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
}
)
);
- Blueprint
- C++
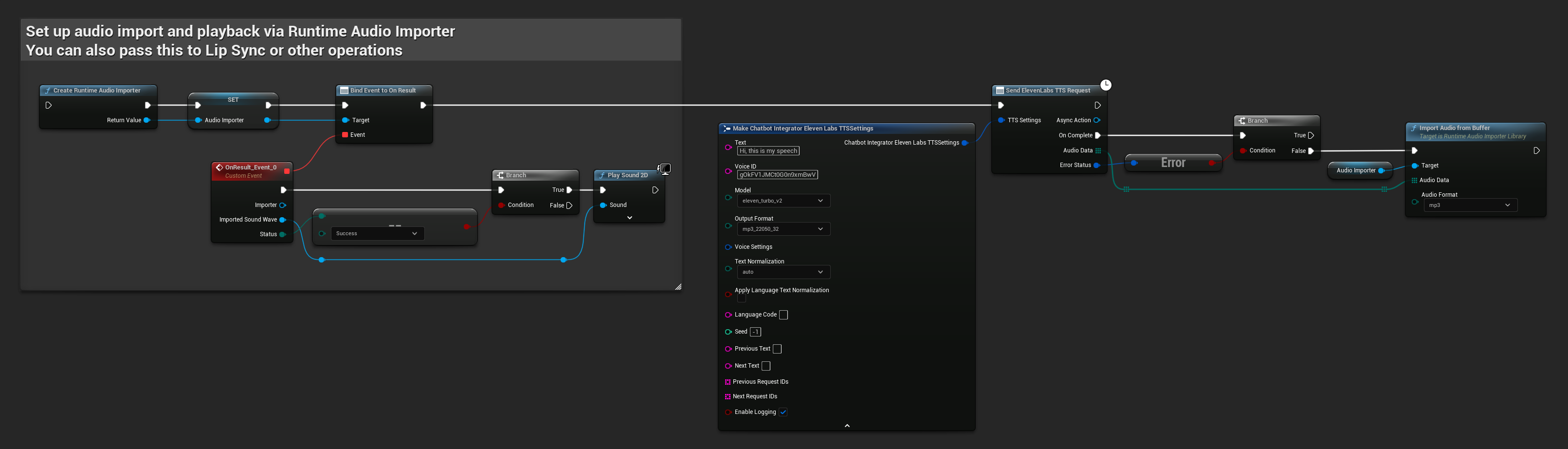
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process audio data as needed
}
}
)
);
- Blueprint
- C++
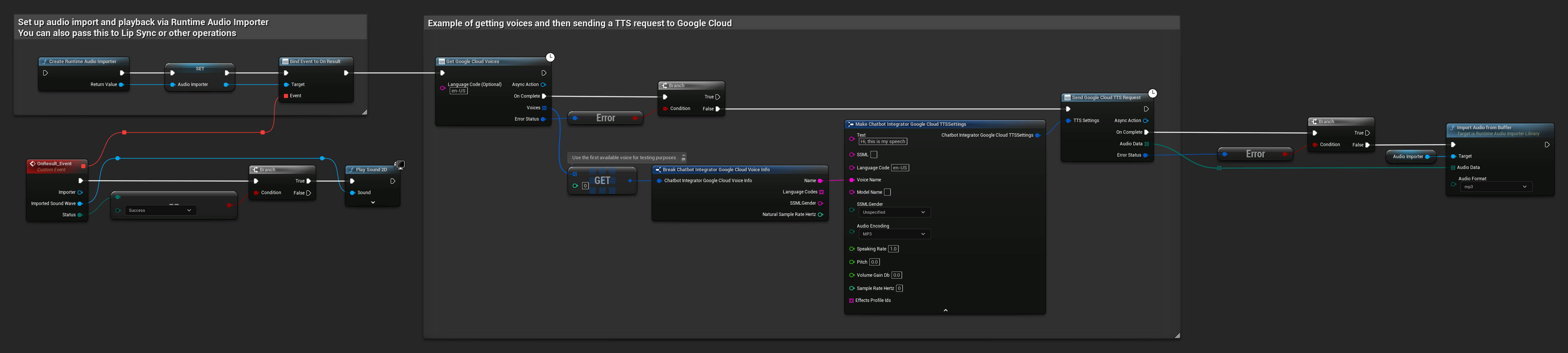
// Example of getting voices and then sending a TTS request to Google Cloud
// First, get available voices
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_GoogleCloudVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s"), *FirstVoice.Name);
// Now send TTS request with the selected voice
FChatbotIntegrator_GoogleCloudTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.LanguageCode = FirstVoice.LanguageCodes.Num() > 0 ? FirstVoice.LanguageCodes[0] : TEXT("en-US");
TTSSettings.VoiceName = FirstVoice.Name;
TTSSettings.AudioEncoding = EChatbotIntegrator_GoogleCloudAudioEncoding::MP3;
UAIChatbotIntegratorGoogleCloudTTS::SendTTSRequestNative(
TTSSettings,
FOnGoogleCloudTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
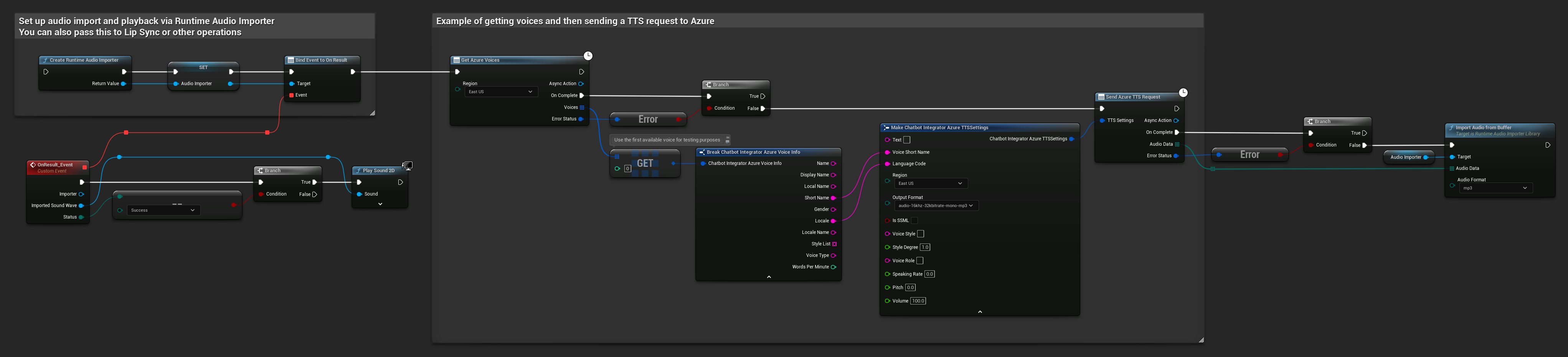
// Example of getting voices and then sending a TTS request to Azure
// First, get available voices
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && Voices.Num() > 0)
{
// Use the first available voice
const FChatbotIntegrator_AzureVoiceInfo& FirstVoice = Voices[0];
UE_LOG(LogTemp, Log, TEXT("Using voice: %s (%s)"), *FirstVoice.DisplayName, *FirstVoice.ShortName);
// Now send TTS request with the selected voice
FChatbotIntegrator_AzureTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceShortName = FirstVoice.ShortName;
TTSSettings.LanguageCode = FirstVoice.Locale;
TTSSettings.Region = EChatbotIntegrator_AzureRegion::EAST_US;
TTSSettings.OutputFormat = EChatbotIntegrator_AzureTTSFormat::AUDIO_16KHZ_32KBITRATE_MONO_MP3;
UAIChatbotIntegratorAzureTTS::SendTTSRequestNative(
TTSSettings,
FOnAzureTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& TTSErrorStatus)
{
if (!TTSErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Process the audio data using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio"));
// Handle ImportedSoundWave playback
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *TTSErrorStatus.ErrorMessage);
}
}
)
);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voices: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
流式 TTS 请求
流式 TTS 在音频块生成时立即交付,允许您增量处理数据,而无需等待整个音频合成完成。这显著降低了长文本的感知延迟,并支持实时应用。ElevenLabs 流式 TTS 还支持动态文本生成场景的高级分块流式功能。
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
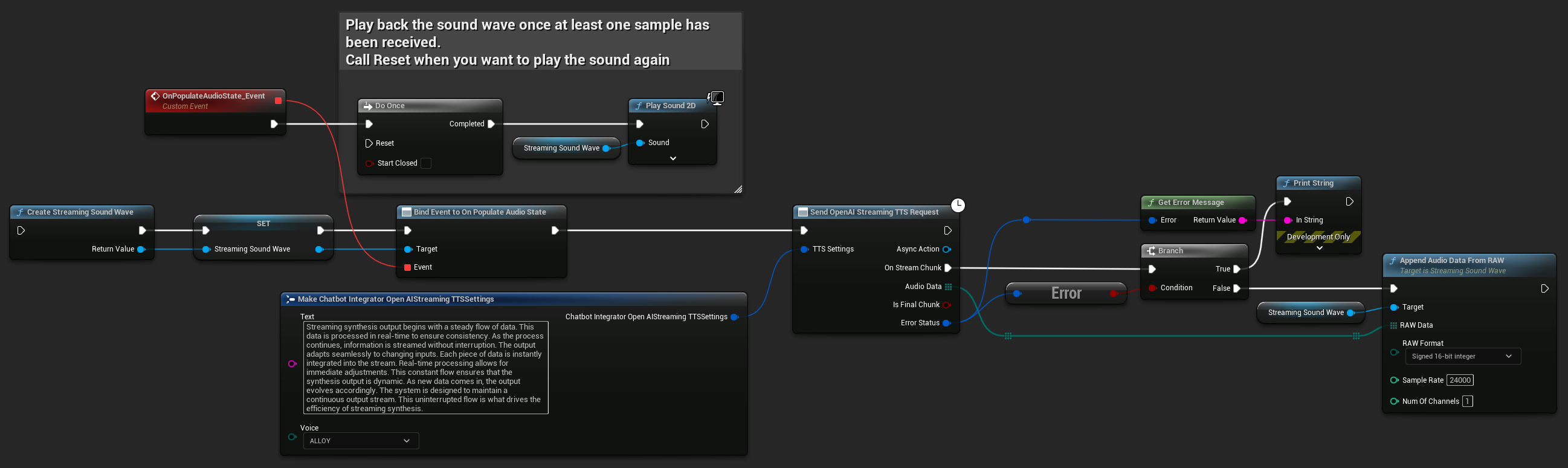
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
}));
}
ElevenLabs Streaming TTS 支持标准流式传输和高级分块流式传输两种模式,为不同的使用场景提供了灵活性。
标准流式传输模式
标准流式传输模式处理预定义的文本,并在音频块生成时立即交付。
- Blueprint
- C++
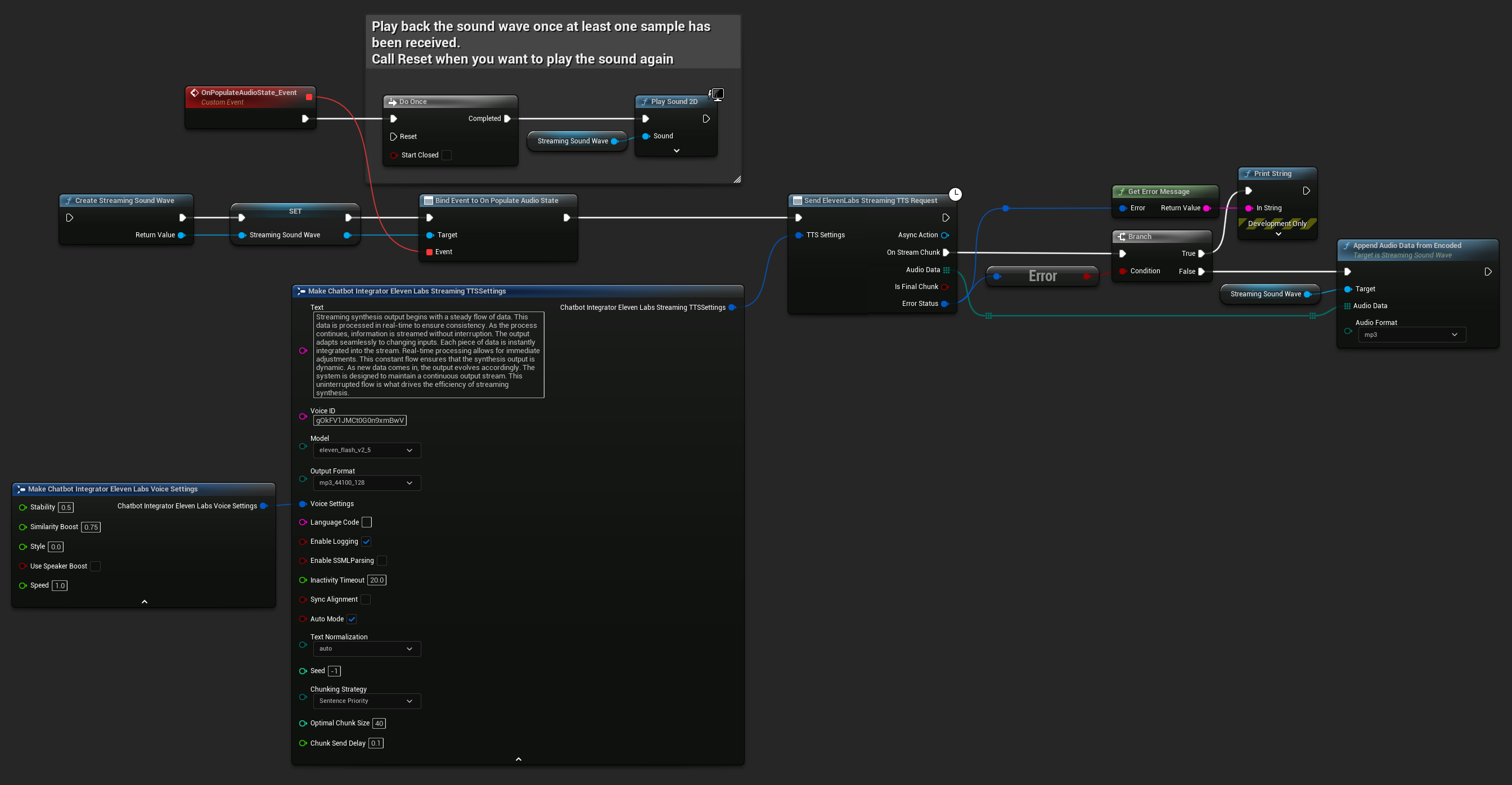
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = false; // Standard streaming mode
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
}));
}
分块流式传输模式
分块流式传输模式允许您在合成过程中动态追加文本,非常适合需要增量生成文本的实时应用(例如,AI聊天响应在生成时即被合成)。要启用此模式,请在您的TTS设置中将 bEnableChunkedStreaming 设置为 true。
- Blueprint
- C++
初始设置: 通过在TTS设置中启用分块流式传输模式并创建初始请求来设置分块流式传输。该请求函数返回一个异步操作对象,该对象提供了用于管理分块流式传输会话的方法:
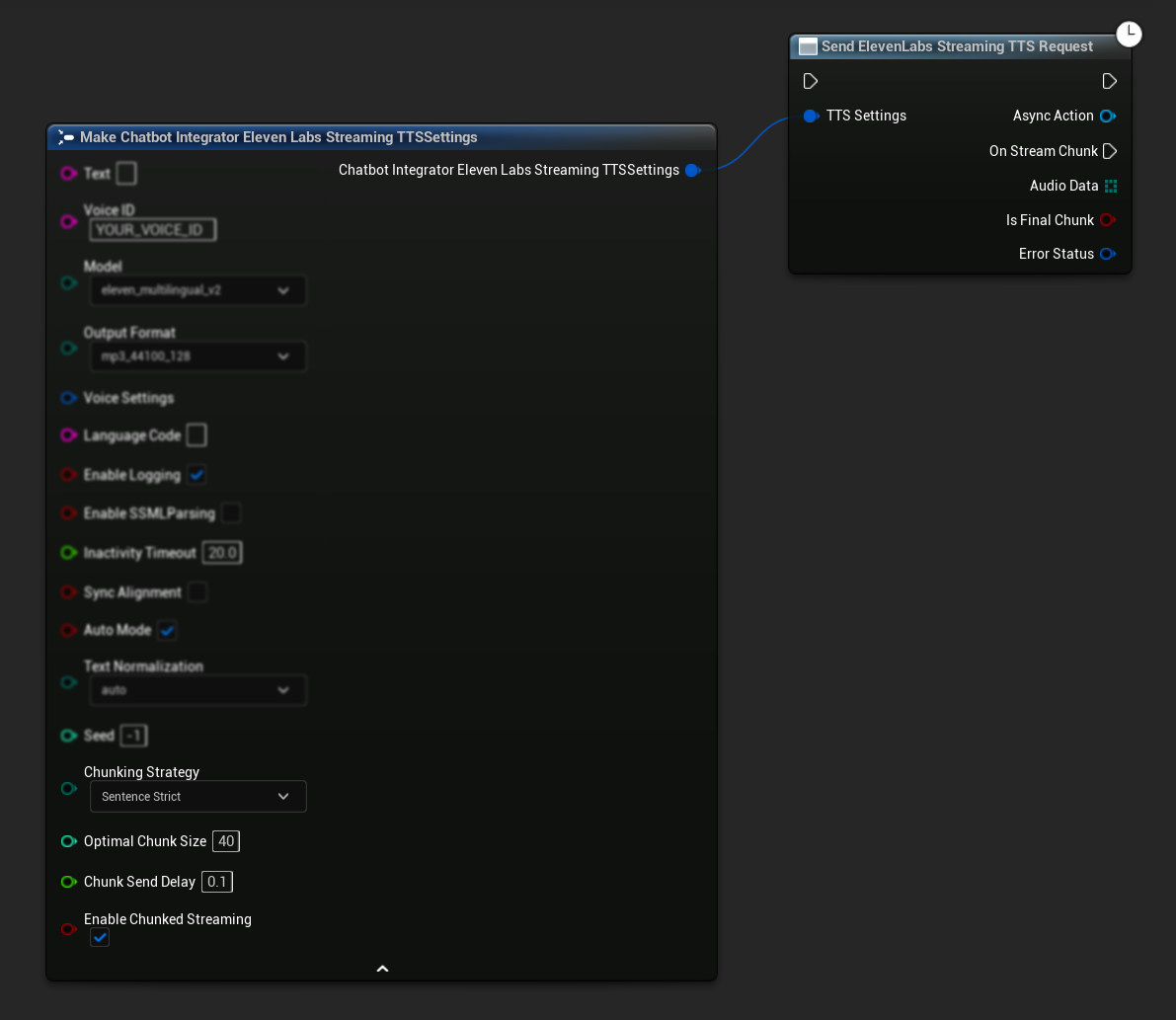
追加文本进行合成:
在返回的异步操作对象上使用此函数,可在活动的分块流式传输会话期间动态添加文本。bContinuousMode 参数控制文本的处理方式:

- 当
bContinuousMode为true时:文本在内部缓冲,直到检测到完整的句子边界(句号、感叹号、问号)。系统会自动提取完整的句子进行合成,同时将不完整的文本保留在缓冲区中。当文本以片段或部分单词的形式到达,且句子完整性不确定时使用此模式。 - 当
bContinuousMode为false时:文本会立即处理,无需缓冲或句子边界分析。每次调用都会导致立即处理分块并进行合成。当您拥有预先形成的完整句子或短语,不需要边界检测时使用此模式。
刷新连续缓冲区: 强制处理异步操作对象上任何已缓冲的连续文本,即使未检测到句子边界。当您知道一段时间内不会有更多文本到达时非常有用:
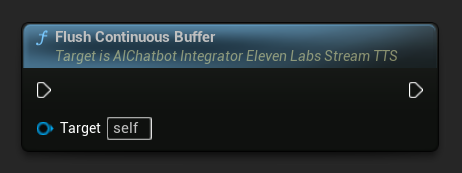
设置连续刷新超时: 配置异步操作对象上连续缓冲区的自动刷新,当在指定超时时间内没有新文本到达时触发:
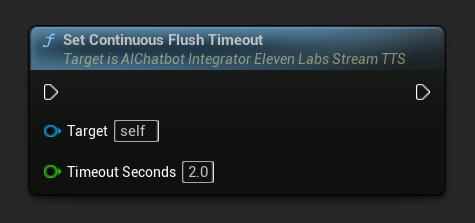
设置为 0 以禁用自动刷新。对于实时应用,推荐值为 1-3 秒。
完成分块流式传输: 关闭异步操作对象上的分块流式传输会话,并将当前合成标记为最终状态。完成添加文本后务必调用此函数:
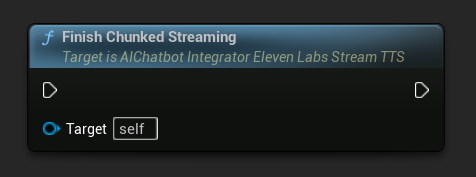
UPROPERTY()
UAIChatbotIntegratorElevenLabsStreamTTS* ChunkedTTSRequest;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartChunkedStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT(""); // Start with empty text in chunked mode
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
TTSSettings.bEnableChunkedStreaming = true; // Enable chunked streaming mode
// Store the returned async action object to call chunked streaming functions on it
ChunkedTTSRequest = UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(
GetWorld(),
TTSSettings,
FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError && AudioData.Num() > 0)
{
UE_LOG(LogTemp, Log, TEXT("Received TTS audio chunk: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
if (IsFinalChunk)
{
UE_LOG(LogTemp, Log, TEXT("Chunked streaming session completed"));
ChunkedTTSRequest = nullptr;
}
})
);
// Now you can append text dynamically as it becomes available
// For example, from an AI chat response stream:
AppendTextToTTS(TEXT("Hello, this is the first part of the message. "));
}
UFUNCTION(BlueprintCallable)
void AppendTextToTTS(const FString& AdditionalText)
{
// Call AppendTextForSynthesis on the returned async action object
if (ChunkedTTSRequest)
{
// Use continuous mode (true) when text is being generated word-by-word
// and you want to wait for complete sentences before processing
bool bContinuousMode = true;
bool bSuccess = ChunkedTTSRequest->AppendTextForSynthesis(AdditionalText, bContinuousMode);
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Successfully appended text: %s"), *AdditionalText);
}
}
}
// Configure continuous text buffering with custom timeout
UFUNCTION(BlueprintCallable)
void SetupAdvancedChunkedStreaming()
{
// Call SetContinuousFlushTimeout on the async action object
if (ChunkedTTSRequest)
{
// Set automatic flush timeout to 1.5 seconds
// Text will be automatically processed if no new text arrives within this timeframe
ChunkedTTSRequest->SetContinuousFlushTimeout(1.5f);
}
}
// Example of handling real-time AI chat response synthesis
UFUNCTION(BlueprintCallable)
void HandleAIChatResponseForTTS(const FString& ChatChunk, bool IsStreamFinalChunk)
{
if (ChunkedTTSRequest)
{
if (!IsStreamFinalChunk)
{
// Append each chat chunk in continuous mode
// The system will automatically extract complete sentences for synthesis
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
}
else
{
// Add the final chunk
ChunkedTTSRequest->AppendTextForSynthesis(ChatChunk, true);
// Flush any remaining buffered text and finish the session
ChunkedTTSRequest->FlushContinuousBuffer();
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
}
// Example of immediate chunk processing (bypassing sentence boundary detection)
UFUNCTION(BlueprintCallable)
void AppendImmediateText(const FString& Text)
{
// Call AppendTextForSynthesis with continuous mode = false on the async action object
if (ChunkedTTSRequest)
{
// Use continuous mode = false for immediate processing
// Useful when you have complete sentences or phrases ready
ChunkedTTSRequest->AppendTextForSynthesis(Text, false);
}
}
UFUNCTION(BlueprintCallable)
void FinishChunkedTTS()
{
// Call FlushContinuousBuffer and FinishChunkedStreaming on the async action object
if (ChunkedTTSRequest)
{
// Flush any remaining buffered text
ChunkedTTSRequest->FlushContinuousBuffer();
// Mark the session as finished
ChunkedTTSRequest->FinishChunkedStreaming();
}
}
ElevenLabs 分块流式传输的关键特性:
- 连续模式:当
bContinuousMode为true时,文本会被缓冲,直到检测到完整的句子边界,然后才进行处理以进行合成 - 立即模式:当
bContinuousMode为false时,文本会立即作为独立的分块进行处理,无需缓冲 - 自动刷新:可配置的超时时间,当在指定时间内没有新的输入到达时,会处理缓冲的文本
- 句子边界检测:检测句子结尾(.、!、?)并从缓冲文本中提取完整的句子
- 实时集成:支持增量文本输入,即内容随时间以片段形式到达
- 灵活的文本分块:提供多种策略(句子优先、句子严格、基于大小)以优化合成处理
获取可用语音
一些 TTS 提供商提供语音列表 API,以便以编程方式发现可用语音。
- Google Cloud Voices
- Azure 语音
- Blueprint
- C++
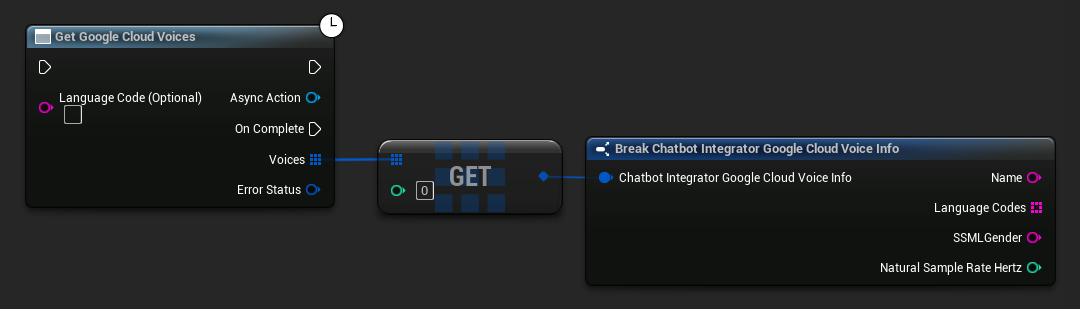
// Example of getting available voices from Google Cloud
UAIChatbotIntegratorGoogleCloudVoices::GetVoicesNative(
TEXT("en-US"), // Optional language filter
FOnGoogleCloudVoicesResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_GoogleCloudVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.Name, *Voice.SSMLGender);
}
}
}
)
);
- Blueprint
- C++
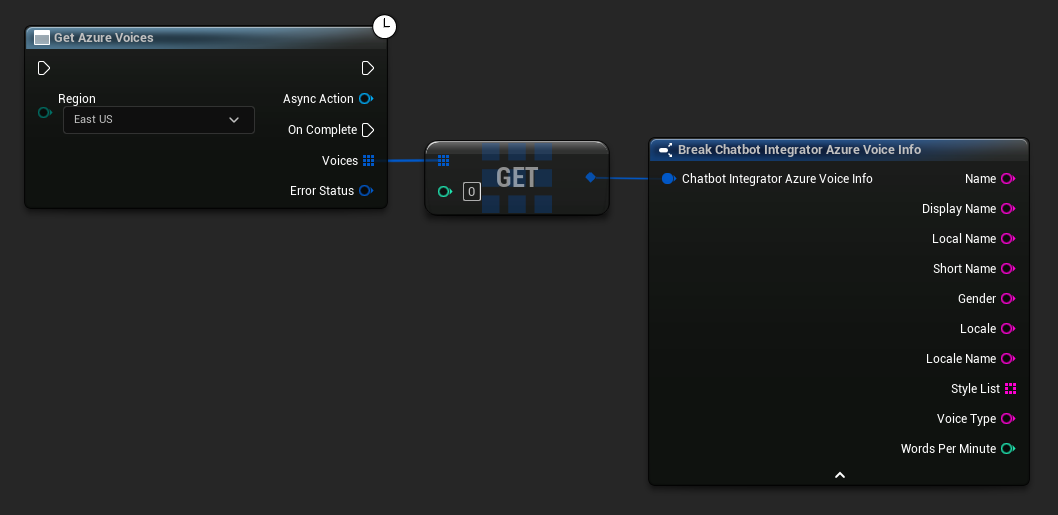
// Example of getting available voices from Azure
UAIChatbotIntegratorAzureGetVoices::GetVoicesNative(
EChatbotIntegrator_AzureRegion::EAST_US,
FOnAzureVoiceListResponseNative::CreateWeakLambda(
this,
[this](const TArray<FChatbotIntegrator_AzureVoiceInfo>& Voices, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const auto& Voice : Voices)
{
UE_LOG(LogTemp, Log, TEXT("Voice: %s (%s)"), *Voice.DisplayName, *Voice.Gender);
}
}
}
)
);
列出 Ollama 模型
您可以使用 ListOllamaModels 函数查询本地 Ollama 实例以获取所有可用模型。这在某些场景下很有用,例如为您的 UI 动态填充模型选择器。为了方便起见,GetModelNames 辅助函数可以从结果中提取出纯名称字符串。
- Blueprint
- C++
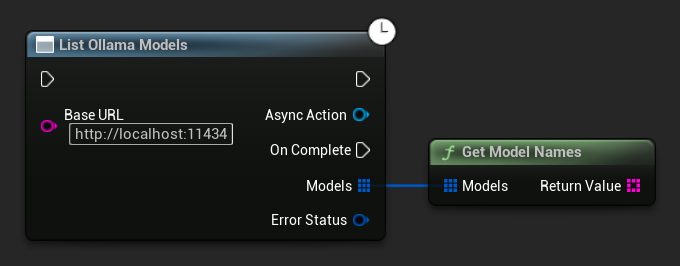
// Example of listing locally available Ollama models
UAIChatbotIntegratorOllamaModelList::ListModelsNative(
TEXT("http://localhost:11434"),
FOnOllamaListModelsResponseNative::CreateWeakLambda(
this,
[this](const TArray<FOllamaModelInfo>& Models, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
for (const FOllamaModelInfo& Model : Models)
{
UE_LOG(LogTemp, Log, TEXT("Model: %s | Family: %s | Parameters: %s | Quantization: %s | Size: %lld bytes"),
*Model.Name, *Model.Family, *Model.ParameterSize, *Model.QuantizationLevel, Model.Size);
}
// Convenience helper to get just the name strings, e.g. for a UI dropdown
TArray<FString> ModelNames = UAIChatbotIntegratorOllamaModelList::GetModelNames(Models);
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to list Ollama models: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
错误处理
发送任何请求时,通过回调函数检查 ErrorStatus 来处理潜在错误至关重要。ErrorStatus 提供了请求过程中可能出现的任何问题的信息。
- Blueprint
- C++
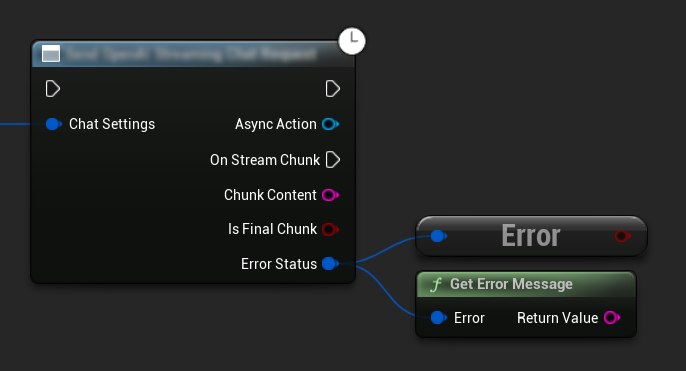
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
取消请求
该插件允许您在文本转文本和 TTS 请求进行中时取消它们。这在您想要中断长时间运行的请求或动态改变对话流程时非常有用。
- Blueprint
- C++
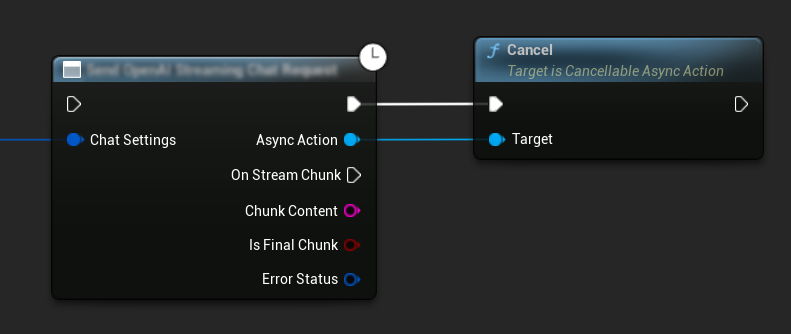
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
最佳实践
- 始终通过检查回调中的
ErrorStatus来处理潜在错误 - 注意每个提供商的 API 速率限制和成本
- 对于长篇或交互式对话,使用流式模式
- 考虑取消不再需要的请求以有效管理资源
- 对较长的文本使用流式 TTS 以减少感知延迟
- 对于音频处理,Runtime Audio Importer 插件提供了一个便捷的解决方案,但您也可以根据项目需求实现自定义处理
- 使用推理模型(DeepSeek Reasoner, Grok)时,请妥善处理推理输出和内容输出
- 在实现 TTS 功能之前,使用语音列表 API 来发现可用的语音
- 对于 ElevenLabs 分块流式传输:当文本是增量生成时(如 AI 响应)使用连续模式,对于预先形成的文本块使用立即模式
- 为连续模式配置适当的刷新超时,以平衡响应速度和自然的语音流
- 根据应用程序的实时性要求选择最佳的分块大小和发送延迟
- 对于 Ollama:使用
ListOllamaModels来动态发现可用模型,而不是硬编码模型名称
故障排除
- 验证您为每个提供商配置的 API 凭据是否正确
- 检查您的网络连接
- 确保在使用 TTS 功能时,您使用的任何音频处理库(如 Runtime Audio Importer)都已正确安装
- 处理 TTS 响应数据时,请确认您使用了正确的音频格式
- 对于流式 TTS,请确保正确处理音频块
- 对于推理模型,请确保您同时处理了推理输出和内容输出
- 查阅提供商特定的文档以了解模型的可用性和功能
- 对于 ElevenLabs 分块流式传输:确保在完成后调用
FinishChunkedStreaming以正确关闭会话 - 对于连续模式问题:检查文本中的句子边界是否正确检测
- 对于实时应用程序:根据您的延迟要求调整分块发送延迟和刷新超时
- 对于 Ollama:在发送请求之前,确保 Ollama 服务器正在运行,并且可以通过配置的
BaseUrl访问