How to use the plugin
The Runtime AI Chatbot Integrator provides two main functionalities: Text-to-Text chat and Text-to-Speech (TTS). Both features follow a similar workflow:
- Register your API provider token
- Configure feature-specific settings
- Send requests and process responses
Register Provider Token
Before sending any requests, register your API provider token using the RegisterProviderToken function.
- Blueprint
- C++
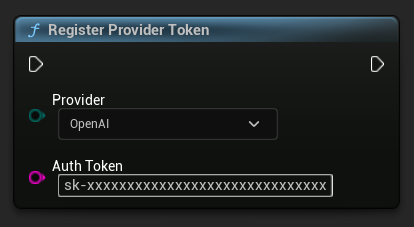
// Register an OpenAI provider token, as an example
UAIChatbotCredentialsManager::RegisterProviderToken(
EAIChatbotIntegratorOrgs::OpenAI,
TEXT("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
);
Text-to-Text Chat Functionality
The plugin supports two chat request modes for each provider:
Non-Streaming Chat Requests
Retrieve the complete response in a single call.
- OpenAI
- DeepSeek
- Claude
- Blueprint
- C++
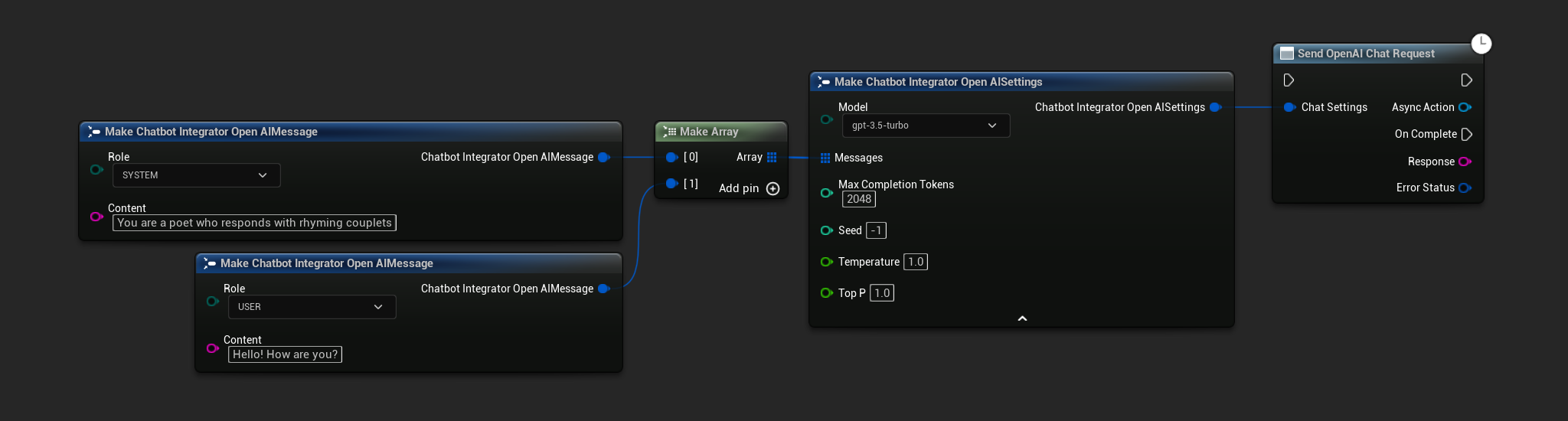
// Example of sending a non-streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage(
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage(
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion response: %s, Error: %d: %s"),
*Response, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
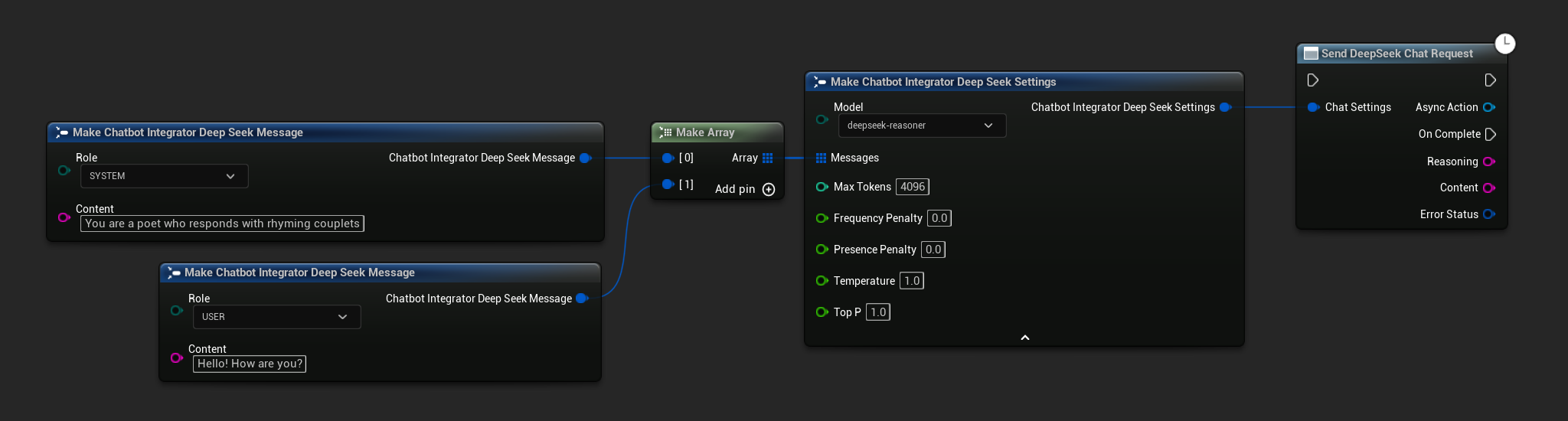
// Example of sending a non-streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage(
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage(
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorDeepSeek::SendChatRequestNative(
Settings,
FOnDeepSeekChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Reasoning, const FString& Content, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Chat completion reasoning: %s, Content: %s, Error: %d: %s"),
*Reasoning, *Content, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
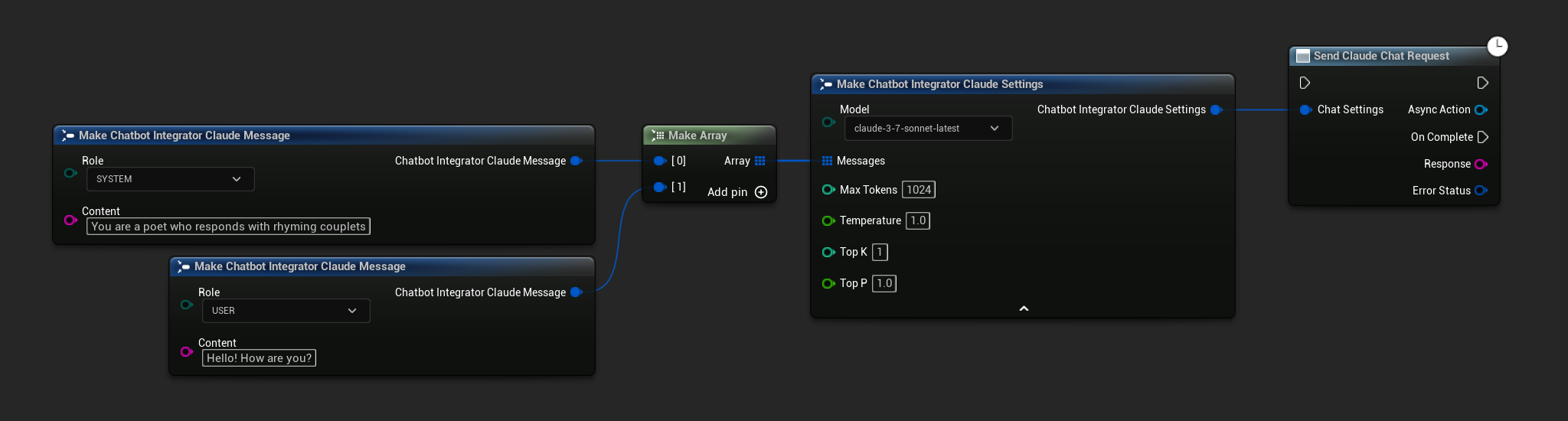
// Example of sending a non-streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage(
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage(
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& Response, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat completion response: %s, IsFinalChunk: %d, Error: %d: %s"),
*Response, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Streaming Chat Requests
Receive response chunks in real-time for a more dynamic interaction.
- OpenAI
- DeepSeek
- Claude
- Blueprint
- C++
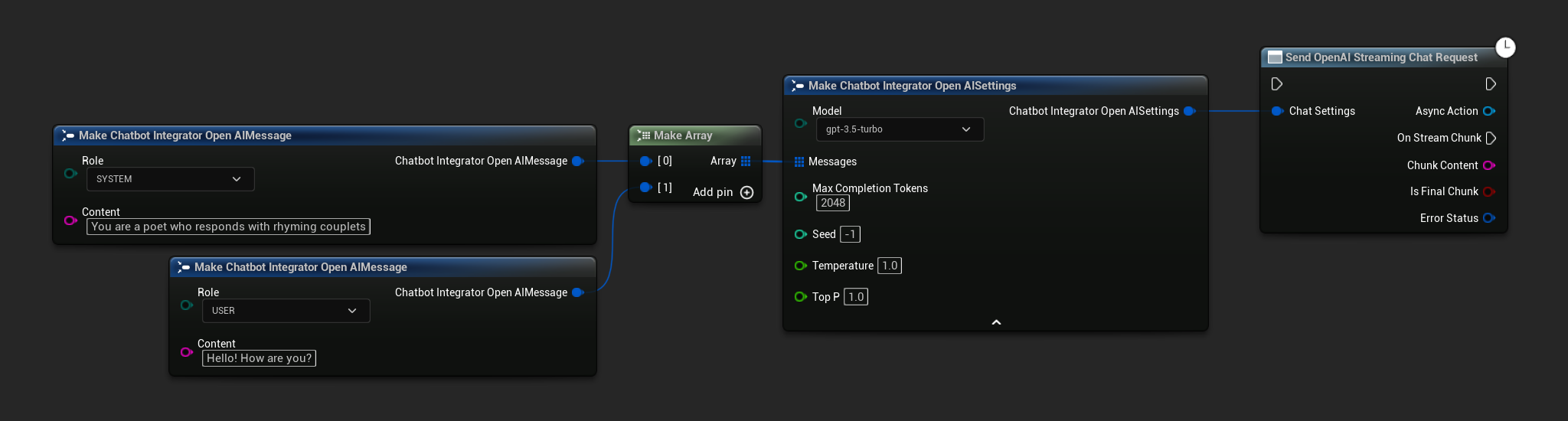
// Example of sending a streaming chat request to OpenAI
FChatbotIntegrator_OpenAISettings Settings;
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage(
EChatbotIntegrator_OpenAIRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_OpenAIMessage(
EChatbotIntegrator_OpenAIRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorOpenAIStream::SendStreamingChatRequestNative(
Settings,
FOnOpenAIChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& Response, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat completion response: %s, IsFinalChunk: %d, Error: %d: %s"),
*Response, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
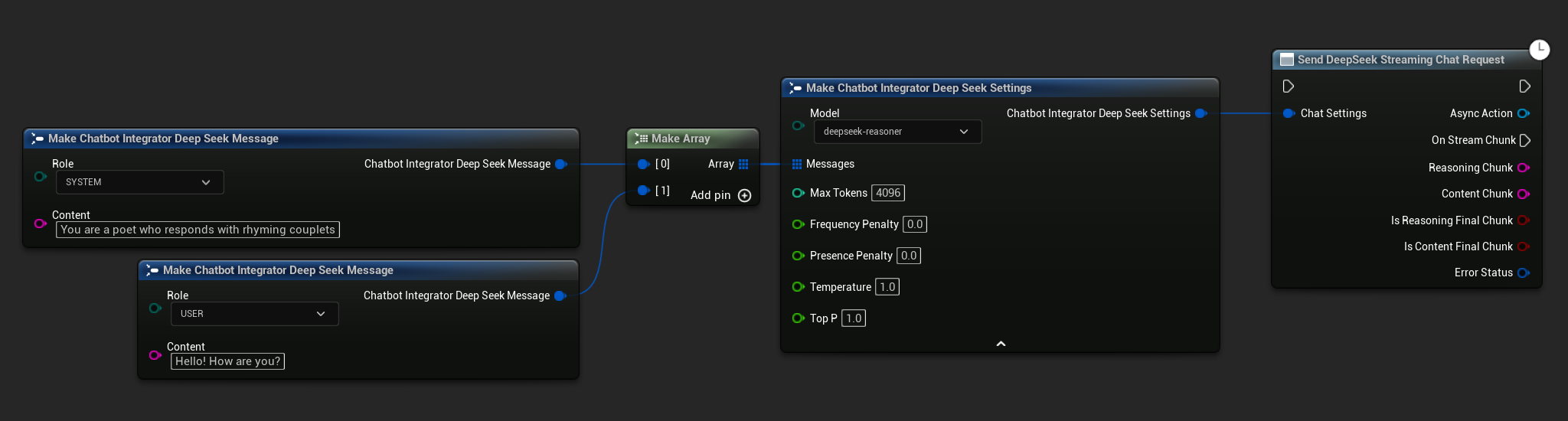
// Example of sending a streaming chat request to DeepSeek
FChatbotIntegrator_DeepSeekSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage(
EChatbotIntegrator_DeepSeekRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_DeepSeekMessage(
EChatbotIntegrator_DeepSeekRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorDeepSeekStream::SendStreamingChatRequestNative(
Settings,
FOnDeepSeekChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& ReasoningChunk, const FString& ContentChunk,
bool IsReasoningFinalChunk, bool IsContentFinalChunk,
const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat completion reasoning chunk: %s, Content chunk: %s, IsReasoningFinalChunk: %d, IsContentFinalChunk: %d, Error: %d: %s"),
*ReasoningChunk, *ContentChunk, IsReasoningFinalChunk, IsContentFinalChunk,
ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
- Blueprint
- C++
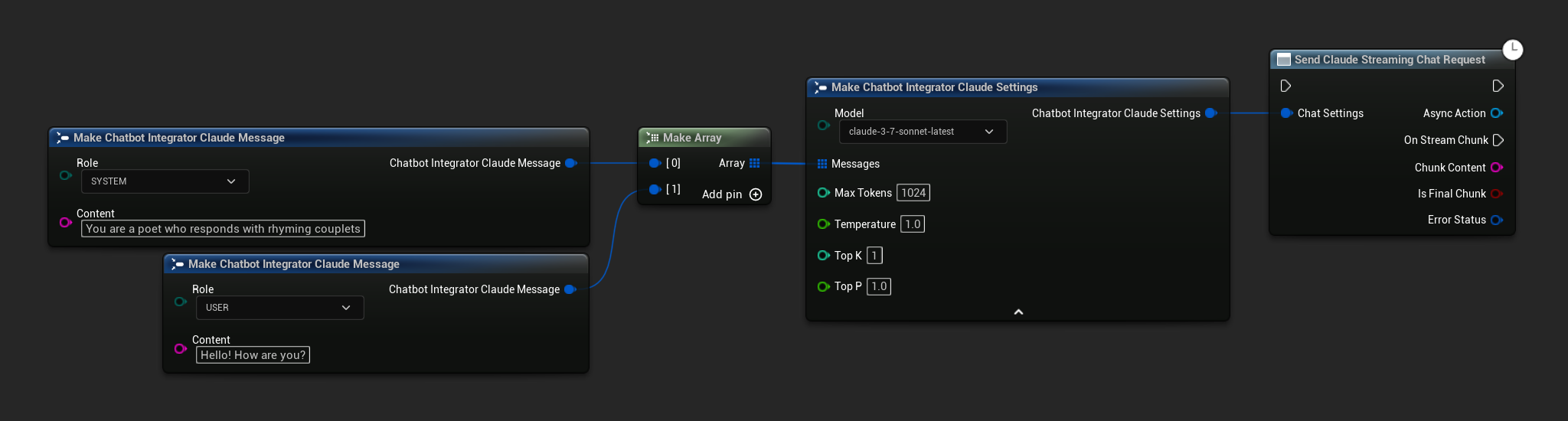
// Example of sending a streaming chat request to Claude
FChatbotIntegrator_ClaudeSettings Settings;
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage(
EChatbotIntegrator_ClaudeRole::SYSTEM,
TEXT("You are a helpful assistant.")
));
Settings.Messages.Add(FChatbotIntegrator_ClaudeMessage(
EChatbotIntegrator_ClaudeRole::USER,
TEXT("What is the capital of France?")
));
UAIChatbotIntegratorClaudeStream::SendStreamingChatRequestNative(
Settings,
FOnClaudeChatCompletionStreamNative::CreateWeakLambda(
this,
[this](const FString& Response, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
UE_LOG(LogTemp, Log, TEXT("Streaming chat completion response: %s, IsFinalChunk: %d, Error: %d: %s"),
*Response, IsFinalChunk, ErrorStatus.bIsError, *ErrorStatus.ErrorMessage);
}
)
);
Text-to-Speech (TTS) Functionality
Convert text to high-quality speech audio using leading TTS providers. The plugin returns raw audio data (TArray<uint8>) that you can process according to your project's needs.
While the examples below demonstrate audio processing for playback using the Runtime Audio Importer plugin (see audio importing documentation), the Runtime AI Chatbot Integrator is designed to be flexible. The plugin simply returns the raw audio data, giving you complete freedom in how you process it for your specific use case, which might include audio playback, saving to file, further audio processing, transmitting to other systems, custom visualizations, and more.
Non-Streaming TTS Requests
Non-streaming TTS requests return the complete audio data in a single response after the entire text has been processed. This approach is suitable for shorter texts where waiting for the complete audio isn't problematic.
- OpenAI TTS
- ElevenLabs TTS
- Blueprint
- C++

// Example of sending a TTS request to OpenAI
FChatbotIntegrator_OpenAITTSSettings TTSSettings;
TTSSettings.Input = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.Voice = EChatbotIntegrator_OpenAITTSVoice::NOVA;
TTSSettings.Speed = 1.0f;
TTSSettings.ResponseFormat = EChatbotIntegrator_OpenAITTSFormat::MP3;
UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
// Example: Import the audio data as a sound wave
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Audio data can be imported using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio with sound wave %s"), *ImportedSoundWave->GetName());
// Here you can handle ImportedSoundWave playback, like "UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);"
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio"));
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
- Blueprint
- C++
// Example of sending a TTS request to ElevenLabs
FChatbotIntegrator_ElevenLabsTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Hello, this is a test of text-to-speech functionality.");
TTSSettings.VoiceID = TEXT("your-voice-id"); // Replace with actual voice ID
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_44100_128;
UAIChatbotIntegratorElevenLabsTTS::SendTTSRequestNative(
TTSSettings,
FOnElevenLabsTTSResponseNative::CreateWeakLambda(
this,
[this](const TArray<uint8>& AudioData, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
// Example: Import the audio data as a sound wave
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
// Audio data can be imported using Runtime Audio Importer plugin
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(this, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
if (Status == ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Warning, TEXT("Successfully imported audio with sound wave %s"), *ImportedSoundWave->GetName());
// Here you can handle ImportedSoundWave playback, like "UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);"
}
else
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio"));
}
Importer->RemoveFromRoot();
});
RuntimeAudioImporter->ImportAudioFromBuffer(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *ErrorStatus.ErrorMessage);
}
}
)
);
Streaming TTS Requests
Streaming TTS delivers audio chunks as they're generated, allowing you to process data incrementally rather than waiting for the entire audio to be synthesized. This significantly reduces the perceived latency for longer texts and enables real-time applications.
- OpenAI Streaming TTS
- ElevenLabs Streaming TTS
- Blueprint
- C++
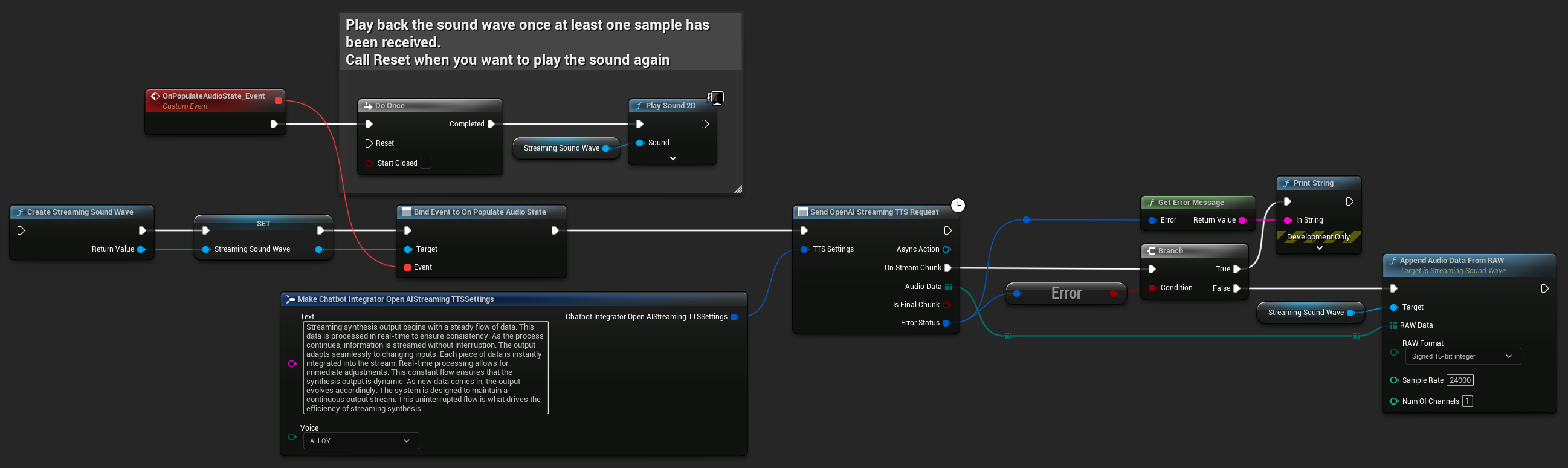
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_OpenAIStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis.");
TTSSettings.Voice = EChatbotIntegrator_OpenAIStreamingTTSVoice::ALLOY;
UAIChatbotIntegratorOpenAIStreamTTS::SendStreamingTTSRequestNative(TTSSettings, FOnOpenAIStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
// Example: Stream audio data into a sound wave
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromRAW(AudioData, ERuntimeRAWAudioFormat::Int16, 24000, 1);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *ErrorStatus.ErrorMessage);
}
}));
}
- Blueprint
- C++
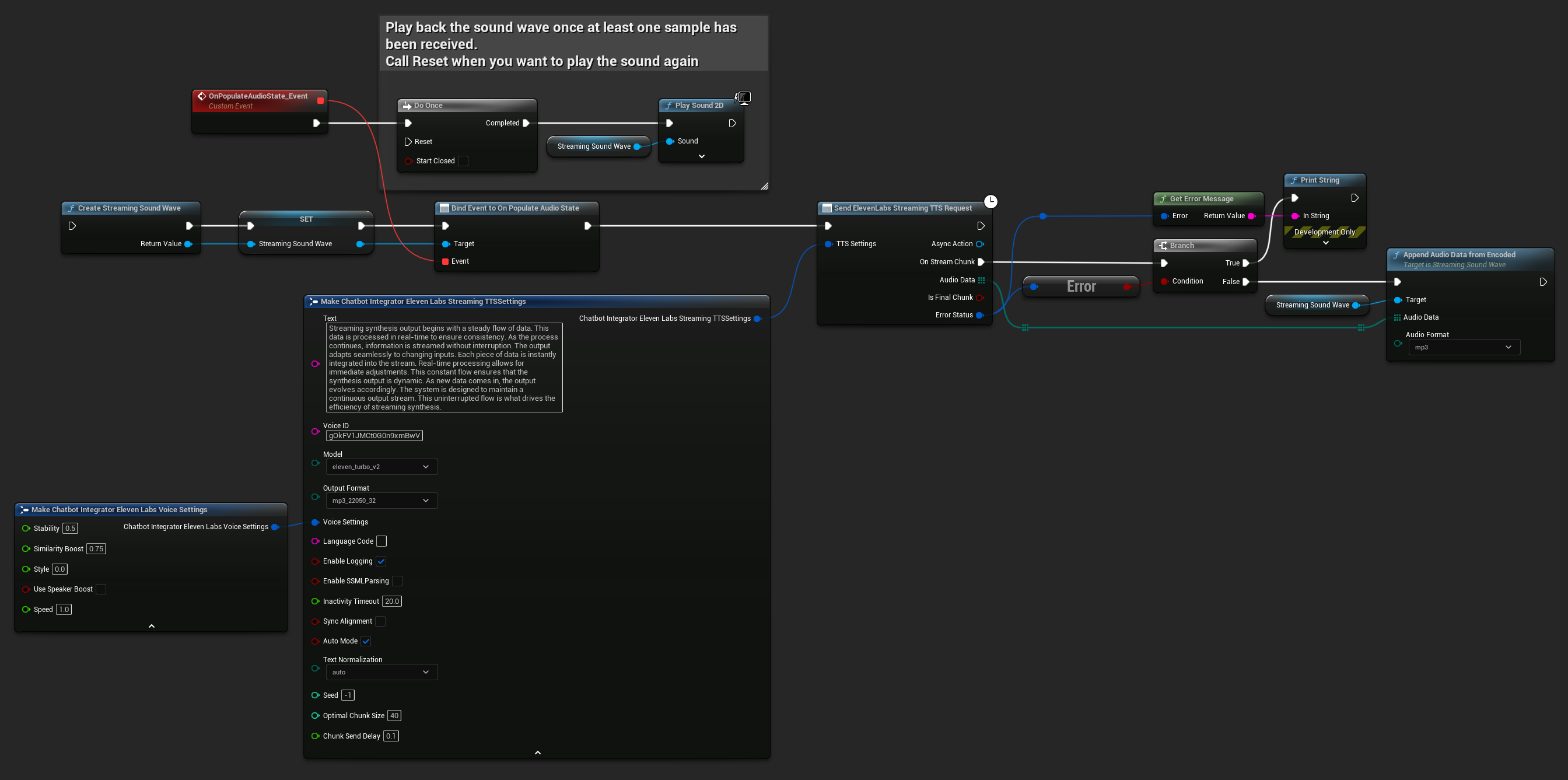
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
UFUNCTION(BlueprintCallable)
void StartStreamingTTS()
{
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
FChatbotIntegrator_ElevenLabsStreamingTTSSettings TTSSettings;
TTSSettings.Text = TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis.");
TTSSettings.Model = EChatbotIntegrator_ElevenLabsTTSModel::ELEVEN_TURBO_V2_5;
TTSSettings.OutputFormat = EChatbotIntegrator_ElevenLabsTTSFormat::MP3_22050_32;
TTSSettings.VoiceID = TEXT("YOUR_VOICE_ID");
UAIChatbotIntegratorElevenLabsStreamTTS::SendStreamingTTSRequestNative(GetWorld(), TTSSettings, FOnElevenLabsStreamingTTSNative::CreateWeakLambda(this, [this](const TArray<uint8>& AudioData, bool IsFinalChunk, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (!ErrorStatus.bIsError)
{
// Process the audio data using Runtime Audio Importer plugin
// Example: Stream audio data into a sound wave
UE_LOG(LogTemp, Log, TEXT("Received TTS audio data: %d bytes"), AudioData.Num());
StreamingSoundWave->AppendAudioDataFromEncoded(AudioData, ERuntimeAudioFormat::Mp3);
}
else
{
UE_LOG(LogTemp, Error, TEXT("TTS request failed: %s"), *ErrorStatus.ErrorMessage);
}
}));
}
Error Handling
When sending any requests, it's crucial to handle potential errors by checking the ErrorStatus in your callback. The ErrorStatus provides information about any issues that might occur during the request.
- Blueprint
- C++
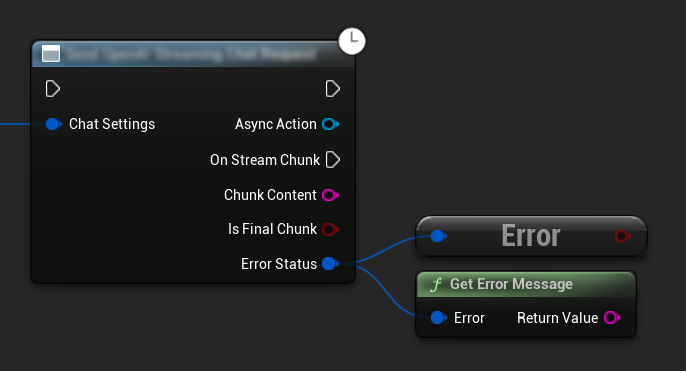
// Example of error handling in a request
UAIChatbotIntegratorOpenAI::SendChatRequestNative(
Settings,
FOnOpenAIChatCompletionResponseNative::CreateWeakLambda(
this,
[this](const FString& Response, const FChatbotIntegratorErrorStatus& ErrorStatus)
{
if (ErrorStatus.bIsError)
{
// Handle the error
UE_LOG(LogTemp, Error, TEXT("Chat request failed: %s"), *ErrorStatus.ErrorMessage);
}
else
{
// Process the successful response
UE_LOG(LogTemp, Log, TEXT("Received response: %s"), *Response);
}
}
)
);
Cancelling Requests
The plugin allows you to cancel both text-to-text and TTS requests while they are in progress. This can be useful when you want to interrupt a long-running request or change the conversation flow dynamically.
- Blueprint
- C++
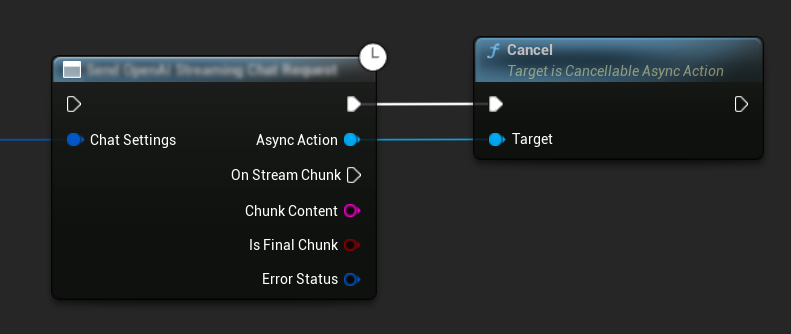
// Example of cancelling requests
UAIChatbotIntegratorOpenAI* ChatRequest = UAIChatbotIntegratorOpenAI::SendChatRequestNative(
ChatSettings,
ChatResponseCallback
);
// Cancel the chat request at any time
ChatRequest->Cancel();
// TTS requests can be cancelled similarly
UAIChatbotIntegratorOpenAITTS* TTSRequest = UAIChatbotIntegratorOpenAITTS::SendTTSRequestNative(
TTSSettings,
TTSResponseCallback
);
// Cancel the TTS request
TTSRequest->Cancel();
Best Practices
- Always handle potential errors by checking the
ErrorStatusin your callback - Be mindful of API rate limits and costs
- Use streaming mode for long-form or interactive conversations
- Consider cancelling requests that are no longer needed to manage resources efficiently
- Use streaming TTS for longer texts to reduce perceived latency
- For audio processing, Runtime Audio Importer plugin offers a convenient solution, but you can implement custom processing based on your project needs
Troubleshooting
- Verify your API credentials are correct
- Check your internet connection
- Ensure any audio processing libraries you use (such as Runtime Audio Importer) are properly installed when working with TTS features
- Verify you're using the correct audio format when processing TTS response data
- For streaming TTS, make sure you're handling audio chunks correctly