ユーティリティ
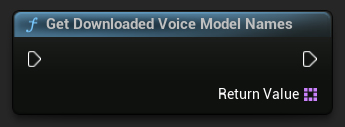
ダウンロード済み音声モデル名の取得
ダウンロード済みのすべての音声モデル名を取得します
- Blueprint
- C++
TArray<FName> DownloadedVoiceModelNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
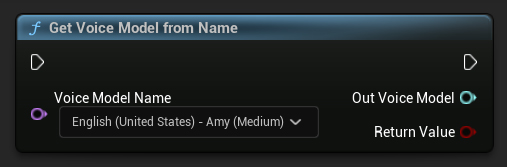
名前から音声モデルを取得
名前から音声モデルオブジェクトを取得します
- Blueprint
- C++
FName VoiceModelName = TEXT("English (United States) - Ryan (High)"); // Assuming this is a valid voice model name
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (URuntimeTTSLibrary::GetVoiceModelFromName(VoiceModelName, VoiceModel))
{
// VoiceModel is now a valid voice model object
}
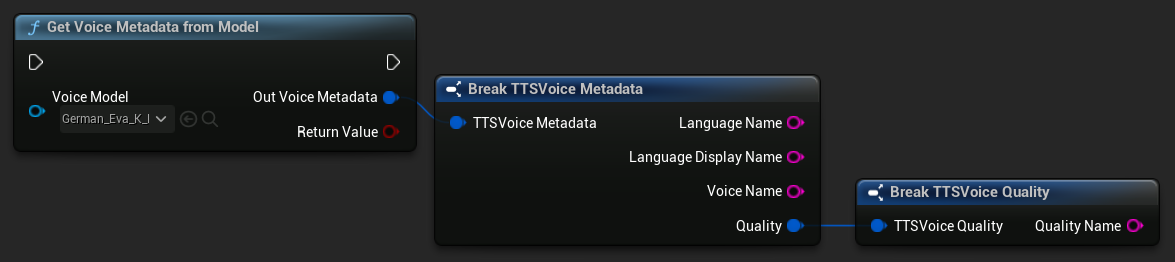
ボイスモデルからメタデータを取得
特定のボイスモデルのメタデータを取得します
- Blueprint
- C++
URuntimeTTSModel* VoiceModel; // Assuming this is a valid voice model object
FTTSVoiceMetadata VoiceMetadata;
if (URuntimeTTSLibrary::GetVoiceMetadataFromModel(VoiceModel, VoiceMetadata))
{
// VoiceMetadata is now populated with the metadata of the voice model
}
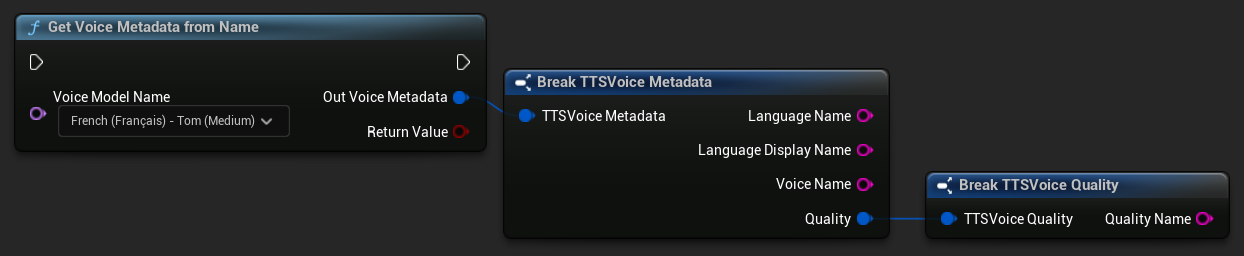
名前から音声メタデータを取得
音声モデルのメタデータを名前から取得
- Blueprint
- C++
FName VoiceModelName = TEXT("English (United States) - Ryan (High)");
FTTSVoiceMetadata VoiceMetadata;
if (URuntimeTTSLibrary::GetVoiceMetadataFromName(VoiceModelName, VoiceMetadata))
{
// VoiceMetadata is now populated with the metadata of the voice model
}
メタデータから音声モデル名を取得
音声メタデータを対応するモデル名に変換
- Blueprint
- C++
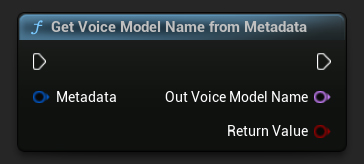
FTTSVoiceMetadata VoiceMetadata; // Assuming this is a populated voice metadata struct
FName VoiceModelName;
if (URuntimeTTSLibrary::GetVoiceModelNameFromMetadata(VoiceMetadata, VoiceModelName))
{
// VoiceModelName is now populated with the name of the voice model
}
ボイスモデルから話者数を取得
ボイスモデルで利用可能な話者の数を取得します
- Blueprint
- C++
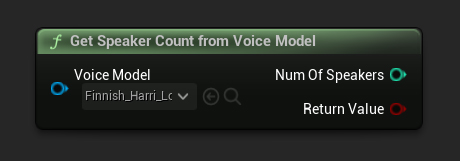
URuntimeTTSModel* VoiceModel; // Assuming this is a valid voice model object
int32 NumOfSpeakers;
if (URuntimeTTSLibrary::GetSpeakerCountFromVoiceModel(VoiceModel, NumOfSpeakers))
{
// NumOfSpeakers is now populated with the number of speakers in the voice model
}
モデル名から話者数を取得
音声モデルの名前を使用して利用可能な話者の数を取得します
- Blueprint
- C++
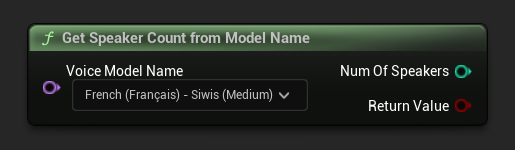
FName VoiceModelName = TEXT("English (United States) - Ryan (High)");
int32 NumOfSpeakers;
if (URuntimeTTSLibrary::GetSpeakerCountFromModelName(VoiceModelName, NumOfSpeakers))
{
// NumOfSpeakers is now populated with the number of speakers in the voice model
}