플러그인 사용 방법
Runtime Text To Speech 플러그인은 다운로드 가능한 음성 모델을 사용하여 텍스트를 음성으로 합성합니다. 이러한 모델들은 에디터 내 플러그인 설정에서 관리, 다운로드되며, 런타임 사용을 위해 패키징됩니다. 시작하려면 아래 단계를 따르세요.
에디터 측
여기에 설명된 대로 프로젝트에 적합한 음성 모델을 다운로드하세요. 여러 음성 모델을 동시에 다운로드할 수 있습니다.
런타임 측
CreateRuntimeTextToSpeech 함수를 사용하여 신디사이저를 생성하세요. 가비지 컬렉션되는 것을 방지하기 위해 참조를 유지해야 합니다(예: Blueprints에서 별도의 변수로 또는 C++에서 UPROPERTY로).
- Blueprint
- C++
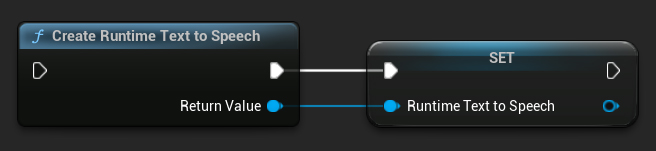
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
음성 합성
이 플러그인은 두 가지 텍스트-음성 변환 모드를 제공합니다:
- 일반 텍스트-음성 변환: 전체 텍스트를 합성하고 완료 시 전체 오디오를 반환합니다
- 스트리밍 텍스트-음성 변환: 생성되는 대로 오디오 청크를 제공하여 실시간 처리를 가능하게 합니다
각 모드는 음성 모델 선택을 위한 두 가지 방법을 지원합니다:
- 이름으로 선택: 음성 모델 이름으로 선택 (UE 5.4+ 권장)
- 오브젝트로 선택: 직접 참조로 음성 모델 선택 (UE 5.3 및 이전 버전 권장)
일반 텍스트-음성 변환
이름으로 선택
- Blueprint
- C++
Text To Speech (By Name) 함수는 UE 5.4부터 Blueprints에서 더 편리합니다. 다운로드된 모델 목록에서 음성 모델을 드롭다운 목록으로 선택할 수 있습니다. UE 5.3 이하 버전에서는 이 드롭다운이 나타나지 않으므로, 이전 버전을 사용하는 경우 GetDownloadedVoiceModels에서 반환된 음성 모델 배열을 수동으로 반복하여 필요한 모델을 선택해야 합니다.
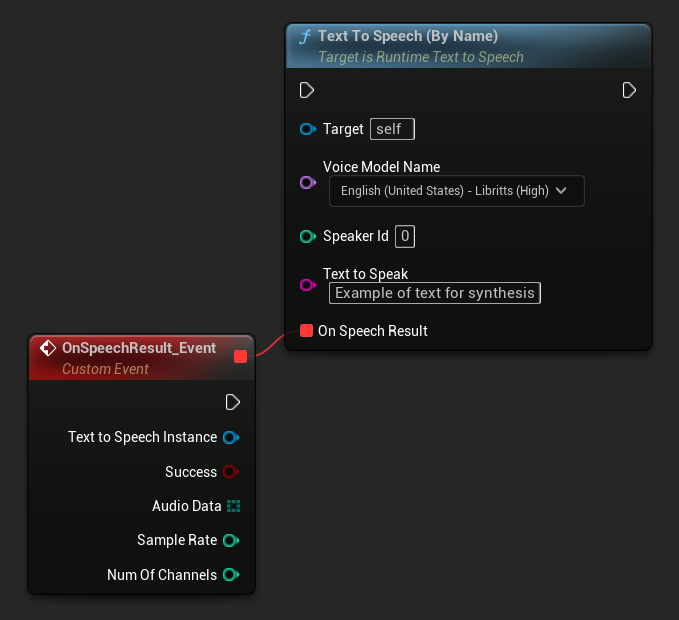
C++에서는 드롭다운 목록이 없어 음성 모델 선택이 약간 더 복잡할 수 있습니다. GetDownloadedVoiceModelNames 함수를 사용하여 다운로드된 음성 모델 이름을 검색하고 필요한 모델을 선택할 수 있습니다. 이후 TextToSpeechByName 함수를 호출하여 선택한 음성 모델 이름으로 텍스트를 합성할 수 있습니다.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
By Object
- Blueprint
- C++
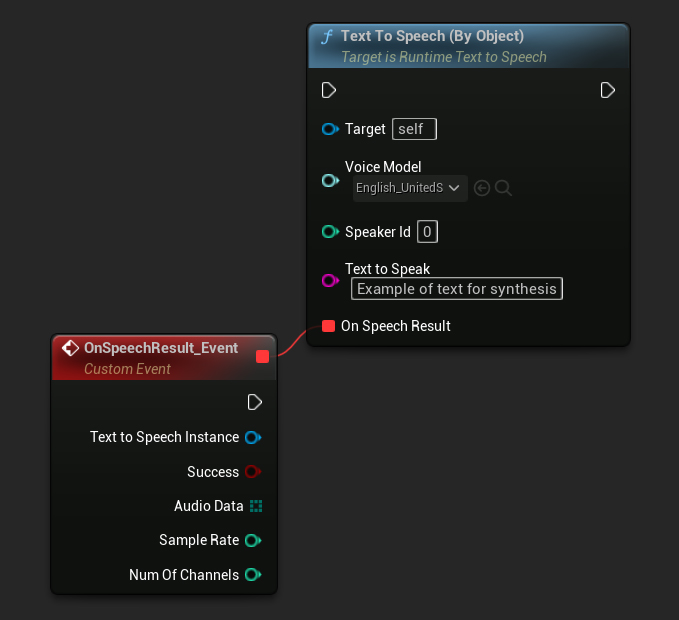
Text To Speech (By Object) 함수는 모든 버전의 Unreal Engine에서 작동하지만 보이스 모델을 에셋 참조의 드롭다운 목록으로 표시하여 덜 직관적입니다. 이 방법은 UE 5.3 및 이전 버전에 적합하거나, 프로젝트에서 어떤 이유로든 보이스 모델 에셋에 대한 직접 참조가 필요한 경우에 적합합니다.
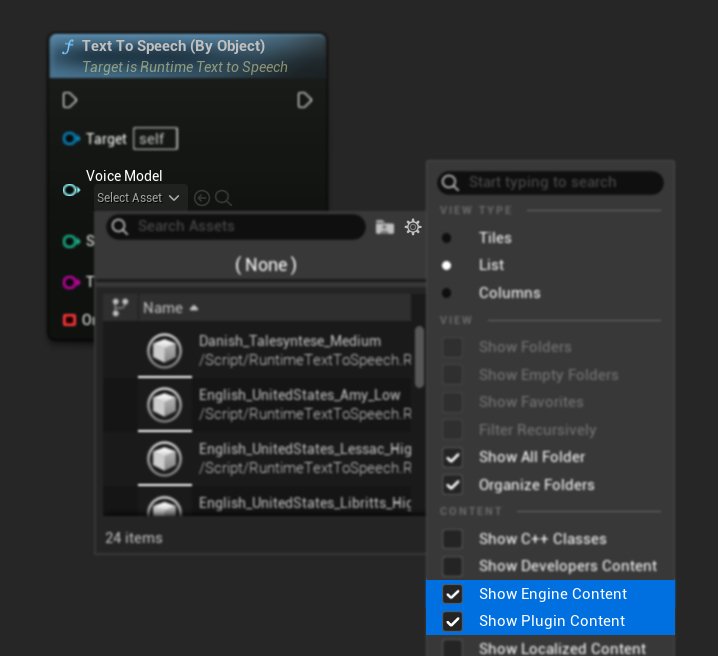
모델을 다운로드했지만 보이지 않는 경우, Voice Model 드롭다운을 열고 설정(기어 아이콘)을 클릭한 후 Show Plugin Content와 Show Engine Content를 모두 활성화하여 모델을 표시하도록 합니다.
C++에서는 드롭다운 목록이 없기 때문에 보이스 모델 선택이 약간 더 복잡할 수 있습니다. GetDownloadedVoiceModelNames 함수를 사용하여 다운로드된 보이스 모델의 이름을 검색하고 필요한 모델을 선택할 수 있습니다. 그런 다음 GetVoiceModelFromName 함수를 사용하여 보이스 모델 객체를 가져와 TextToSpeechByObject 함수에 전달하여 텍스트를 합성할 수 있습니다.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
스트리밍 텍스트-음성 변환
긴 텍스트의 경우 또는 오디오 데이터가 생성되는 대로 실시간으로 처리하고 싶을 때는 스트리밍 버전의 Text-to-Speech 함수를 사용할 수 있습니다:
Streaming Text To Speech (By Name)(C++에서는StreamingTextToSpeechByName)Streaming Text To Speech (By Object)(C++에서는StreamingTextToSpeechByObject)
이 함수들은 생성되는 대로 오디오 데이터를 청크 단위로 제공하여, 전체 합성이 완료될 때까지 기다리지 않고 즉시 처리를 가능하게 합니다. 이는 실시간 오디오 재생, 라이브 시각화 또는 음성 데이터를 점진적으로 처리해야 하는 다양한 시나리오에 유용합니다.
이름으로 스트리밍
- Blueprint
- C++
Streaming Text To Speech (By Name) 함수는 일반 버전과 유사하게 작동하지만 On Speech Chunk 델리게이트를 통해 오디오를 청크 단위로 제공합니다.
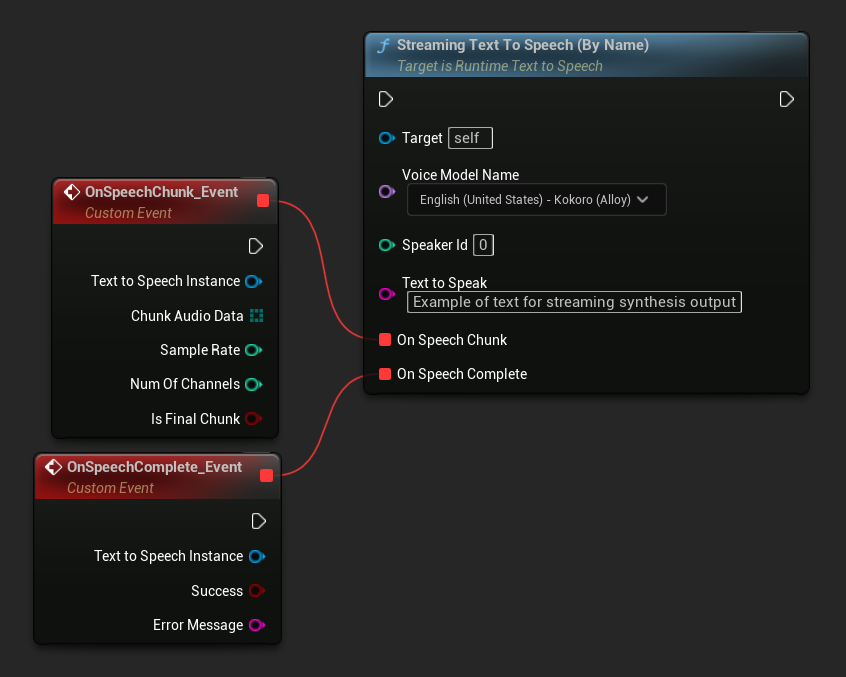
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
오브젝트별 스트리밍
- Blueprint
- C++
Streaming Text To Speech (By Object) 함수는 동일한 스트리밍 기능을 제공하지만 음성 모델 오브젝트 레퍼런스를 사용합니다.
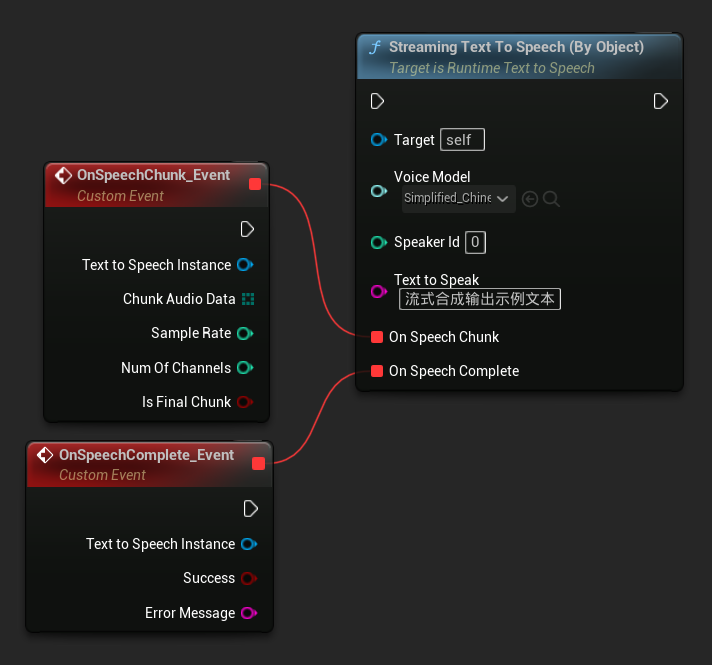
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
오디오 재생
- Regular Playback
- 스트리밍 재생
일반적인 (비-스트리밍) text-to-speech의 경우, On Speech Result delegate가 합성된 오디오를 PCM 데이터로 float 형식으로 제공합니다 (Blueprint에서는 바이트 배열로, C++에서는 TArray<uint8>로). 또한 Sample Rate와 Num Of Channels도 함께 제공됩니다.
재생을 위해서는 Runtime Audio Importer 플러그인을 사용하여 raw 오디오 데이터를 재생 가능한 사운드 웨이브로 변환하는 것을 권장합니다.
- Blueprint
- C++
다음은 텍스트를 합성하고 오디오를 재생하는 Blueprint 노드의 예시입니다 (복사 가능한 노드):
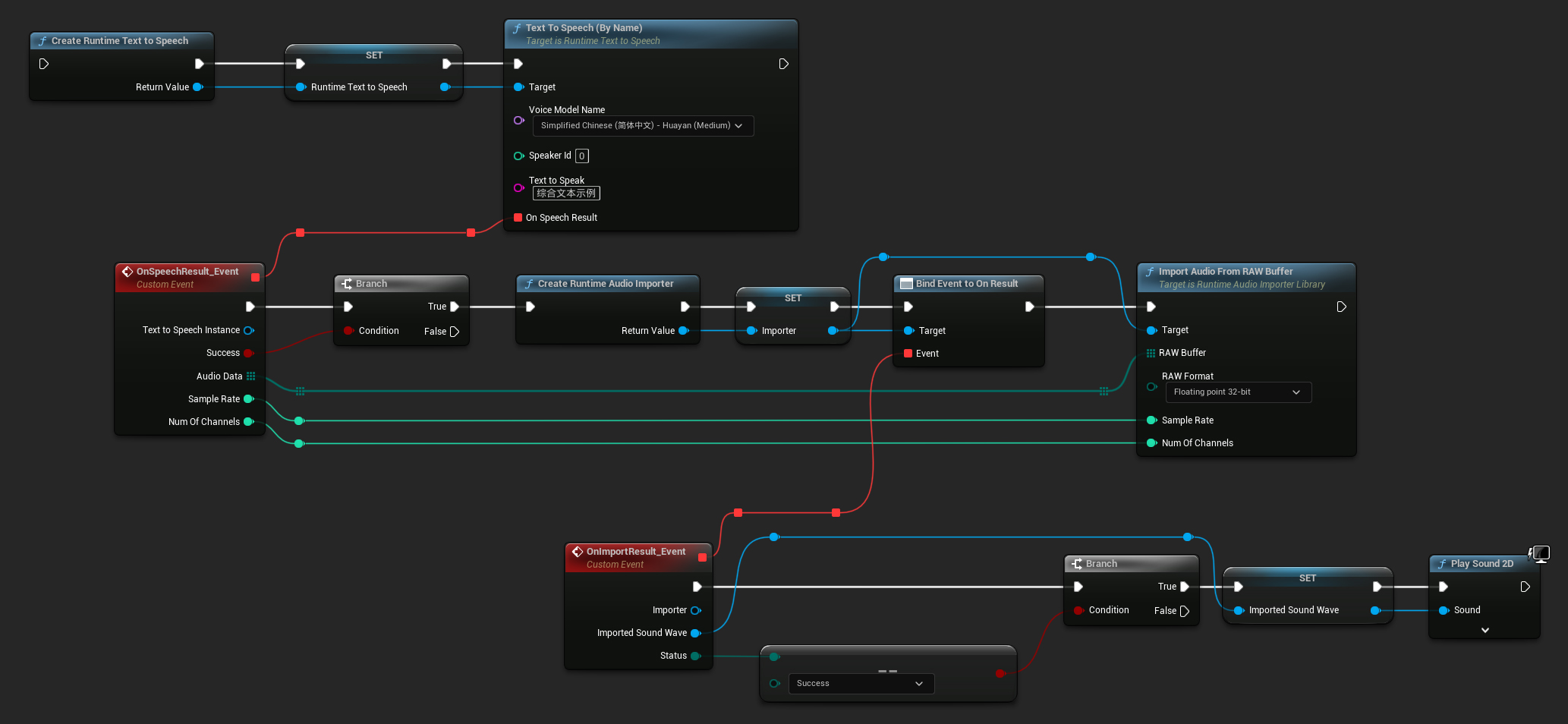
다음은 C++에서 텍스트를 합성하고 오디오를 재생하는 방법의 예시입니다:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
스트리밍 텍스트 음성 변환의 경우, PCM 데이터를 float 형식으로(Blueprints에서는 바이트 배열, C++에서는 TArray<uint8>로) 청크 단위로 받게 되며, Sample Rate와 Num Of Channels 정보도 함께 제공됩니다. 각 청크는 사용 가능해지는 즉시 바로 처리할 수 있습니다.
실시간 재생을 위해서는 스트리밍 오디오 재생이나 실시간 처리를 위해 특별히 설계된 Runtime Audio Importer 플러그인의 Streaming Sound Wave 사용을 권장합니다.
- Blueprint
- C++
다음은 스트리밍 텍스트 음성 변환 및 오디오 재생을 위한 Blueprint 노드의 예시입니다 (복사 가능한 노드):
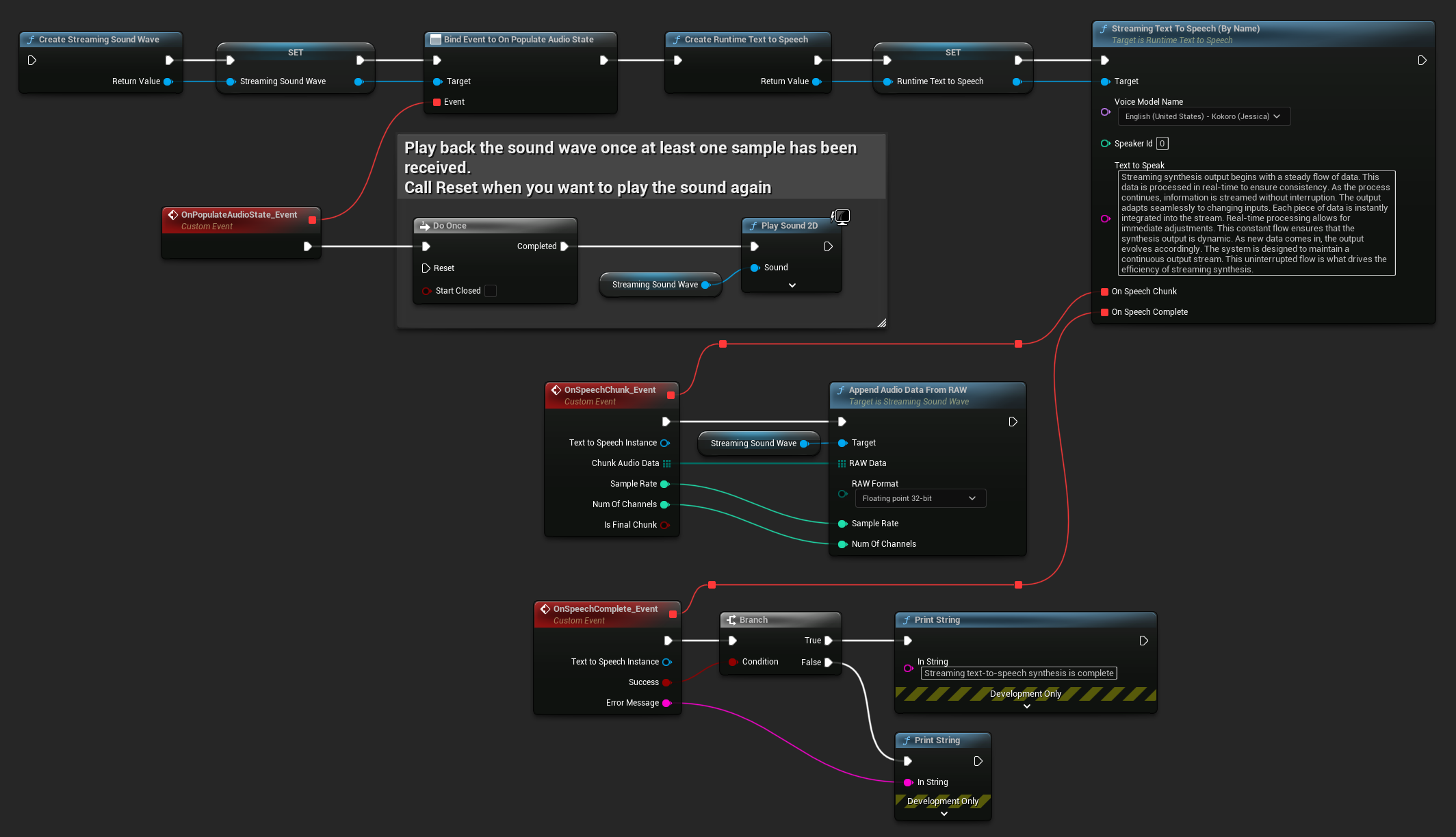
다음은 C++에서 실시간 재생과 함께 스트리밍 텍스트 음성 변환을 구현하는 방법의 예시입니다:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
텍스트 음성 변환 취소하기
진행 중인 텍스트 음성 변합성 작업은 언제든지 synthesizer 인스턴스에서 CancelSpeechSynthesis 함수를 호출하여 취소할 수 있습니다:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
합성이 취소될 때:
- 합성 프로세스는 가능한 한 빨리 중단됩니다
- 진행 중인 콜백은 종료됩니다
- 완료 델리게이트는
bSuccess = false와 함께 합성이 취소되었음을 나타내는 오류 메시지와 함께 호출됩니다 - 합성을 위해 할당된 모든 리소스는 적절하게 정리됩니다
이는 긴 텍스트나 재생을 중단하고 새로운 합성을 시작해야 할 때 특히 유용합니다.
Speaker 선택
두 Text To Speech 함수는 선택적 speaker ID 매개변수를 허용하며, 이는 여러 speaker를 지원하는 음성 모델로 작업할 때 유용합니다. 선택한 음성 모델이 여러 speaker를 지원하는지 확인하려면 GetSpeakerCountFromVoiceModel 또는 GetSpeakerCountFromModelName 함수를 사용할 수 있습니다. 여러 speaker를 사용할 수 있는 경우, Text To Speech 함수를 호출할 때 원하는 speaker ID를 지정하기만 하면 됩니다. 일부 음성 모델은 광범위한 다양성을 제공합니다 - 예를 들어, English LibriTTS는 선택할 수 있는 900명 이상의 다른 speaker를 포함합니다.
Runtime Audio Importer 플러그인은 또한 오디오 데이터를 파일로 내보내기, SoundCue 및 MetaSound 등으로 전달하기와 같은 추가 기능을 제공합니다. 자세한 내용은 Runtime Audio Importer 문서를 확인하세요.