Como usar o plugin
O plugin Runtime Text To Speech sintetiza texto em fala usando modelos de voz baixáveis. Esses modelos são gerenciados nas configurações do plugin dentro do editor, baixados e empacotados para uso em tempo de execução. Siga os passos abaixo para começar.
Lado do editor
Baixe os modelos de voz apropriados para o seu projeto conforme descrito aqui. Você pode baixar múltiplos modelos de voz ao mesmo tempo.
Lado do runtime
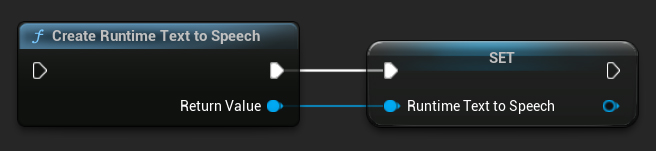
Crie o sintetizador usando a função CreateRuntimeTextToSpeech. Certifique-se de manter uma referência a ele (por exemplo, como uma variável separada em Blueprints ou UPROPERTY em C++) para evitar que seja coletado como lixo.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Sintetizando Fala
O plugin oferece dois modos de síntese de texto para fala:
- Texto para Fala Regular: Sintetiza o texto inteiro e retorna o áudio completo quando finalizado
- Texto para Fala em Streaming: Fornece chunks de áudio conforme são gerados, permitindo processamento em tempo real
Cada modo suporta dois métodos para selecionar modelos de voz:
- Por Nome: Selecione um modelo de voz pelo seu nome (recomendado para UE 5.4+)
- Por Objeto: Selecione um modelo de voz por referência direta (recomendado para UE 5.3 e anteriores)
Texto para Fala Regular
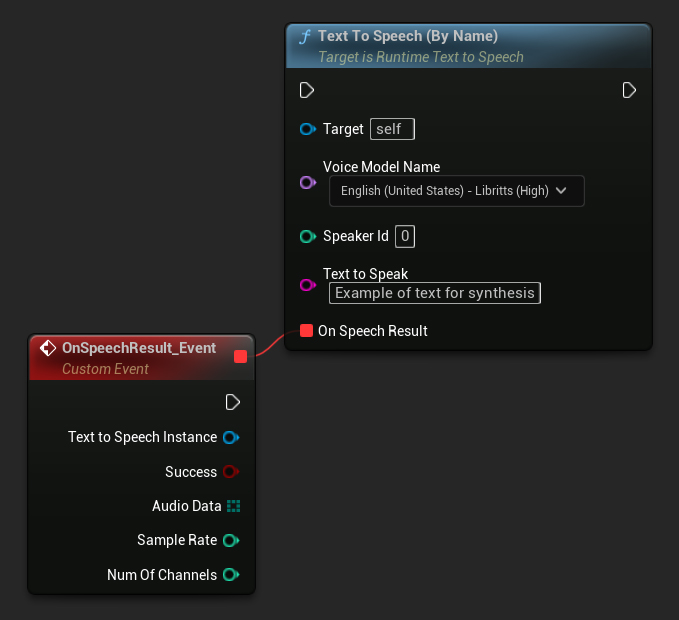
Por Nome
- Blueprint
- C++
A função Text To Speech (By Name) é mais conveniente em Blueprints a partir do UE 5.4. Ela permite que você selecione modelos de voz a partir de uma lista suspensa dos modelos baixados. Em versões do UE abaixo da 5.3, esta lista suspensa não aparece, então se você estiver usando uma versão mais antiga, precisará iterar manualmente sobre o array de modelos de voz retornado por GetDownloadedVoiceModels para selecionar o que você precisa.
Em C++, a seleção de modelos de voz pode ser um pouco mais complexa devido à falta de uma lista suspensa. Você pode usar a função GetDownloadedVoiceModelNames para recuperar os nomes dos modelos de voz baixados e selecionar o que você precisa. Posteriormente, você pode chamar a função TextToSpeechByName para sintetizar texto usando o nome do modelo de voz selecionado.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
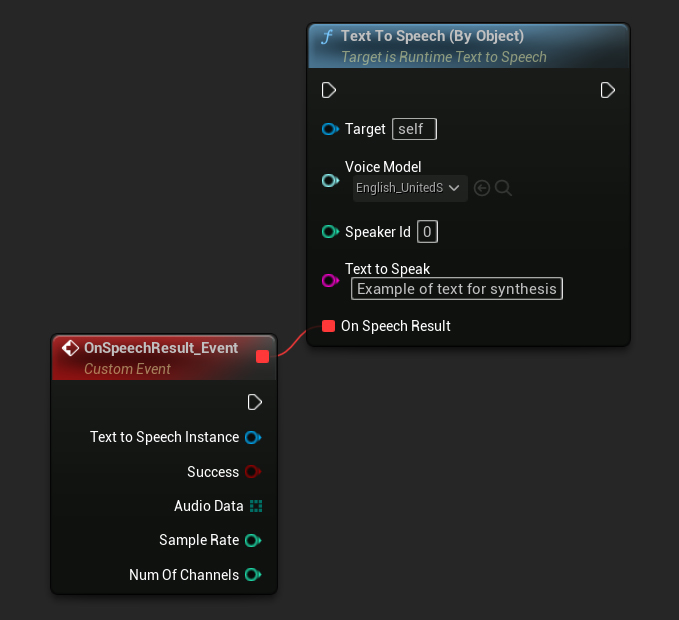
Por Objeto
- Blueprint
- C++
A função Text To Speech (By Object) funciona em todas as versões do Unreal Engine, mas apresenta os modelos de voz como uma lista suspensa de referências de assets, o que é menos intuitivo. Este método é adequado para UE 5.3 e anteriores, ou se o seu projeto exigir uma referência direta a um asset de modelo de voz por qualquer motivo.
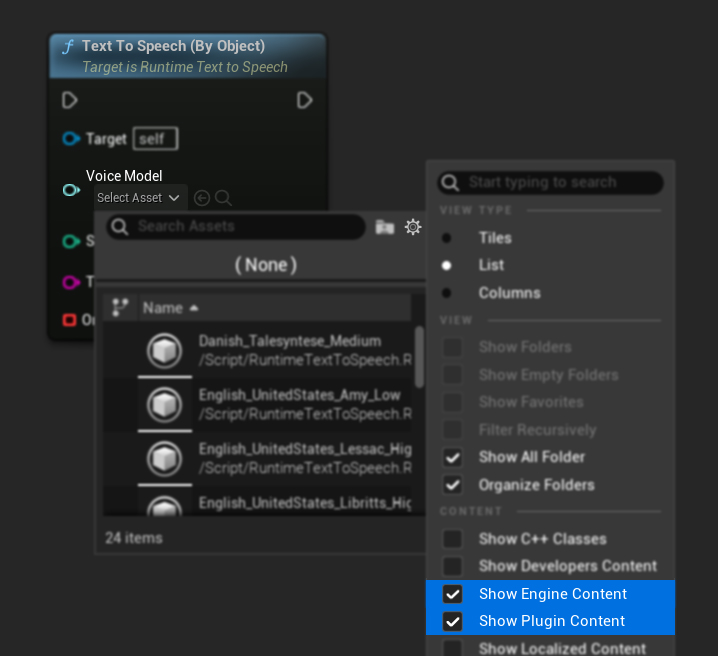
Se você baixou os modelos mas não consegue vê-los, abra a lista suspensa Voice Model, clique nas configurações (ícone de engrenagem) e habilite Show Plugin Content e Show Engine Content para tornar os modelos visíveis.
Em C++, a seleção de modelos de voz pode ser um pouco mais complexa devido à falta de uma lista suspensa. Você pode usar a função GetDownloadedVoiceModelNames para recuperar os nomes dos modelos de voz baixados e selecionar o que você precisa. Em seguida, você pode chamar a função GetVoiceModelFromName para obter o objeto do modelo de voz e passá-lo para a função TextToSpeechByObject para sintetizar o texto.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Text-to-Speech em Streaming
Para textos mais longos ou quando você deseja processar dados de áudio em tempo real à medida que são gerados, você pode usar as versões em streaming das funções Text-to-Speech:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNameem C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectem C++)
Essas funções fornecem dados de áudio em pedaços (chunks) conforme são gerados, permitindo o processamento imediato sem esperar pela síntese completa. Isso é útil para várias aplicações como reprodução de áudio em tempo real, visualização ao vivo ou qualquer cenário onde você precise processar dados de fala de forma incremental.
Streaming Por Nome
- Blueprint
- C++
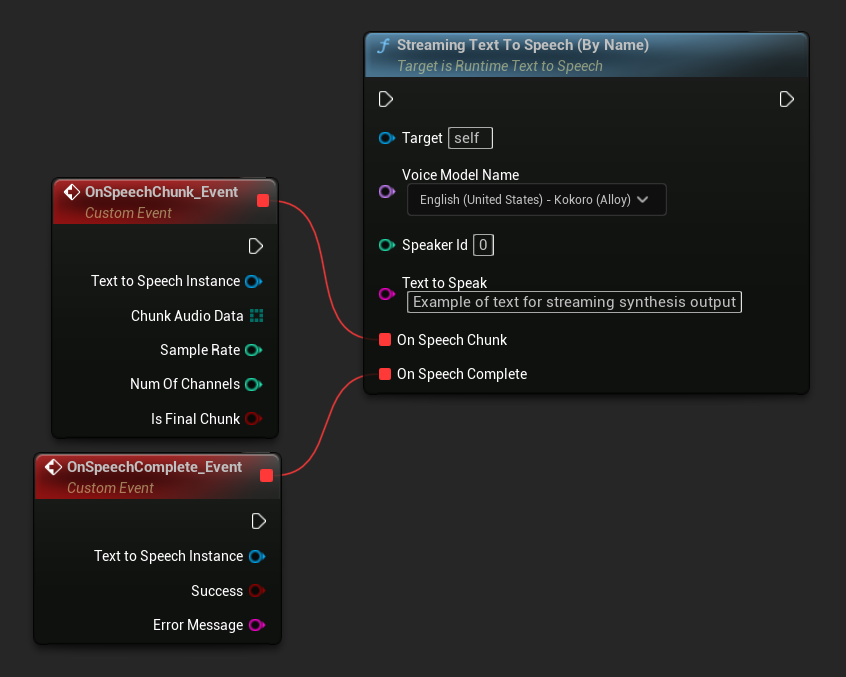
A função Streaming Text To Speech (By Name) funciona de forma similar à versão regular, mas fornece áudio em pedaços através do delegado On Speech Chunk.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming Por Objeto
- Blueprint
- C++
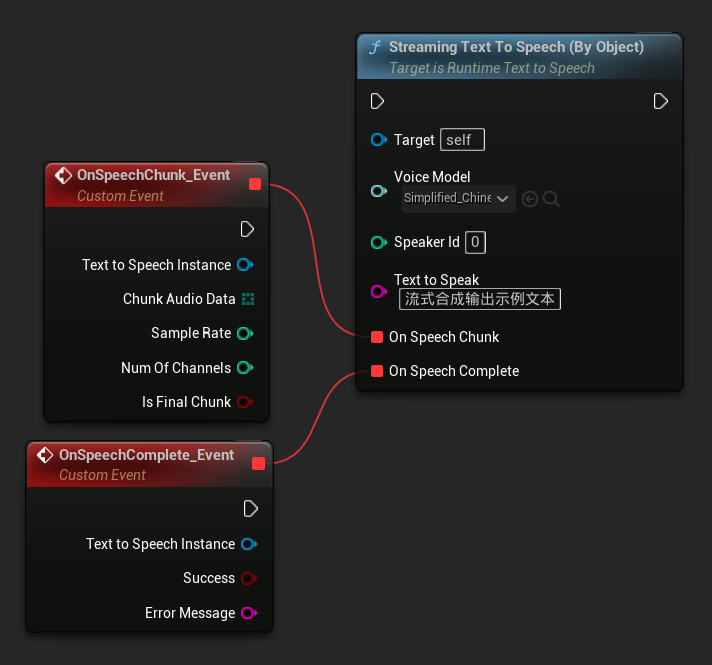
A função Streaming Text To Speech (By Object) fornece a mesma funcionalidade de streaming, mas recebe uma referência de objeto de modelo de voz.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Reprodução de Áudio
- Reprodução Regular
- Reprodução em Streaming
Para text-to-speech regular (não streaming), o delegado On Speech Result fornece o áudio sintetizado como dados PCM em formato float (como um array de bytes em Blueprints ou TArray<uint8> em C++), juntamente com a Sample Rate e Num Of Channels.
Para reprodução, é recomendado usar o plugin Runtime Audio Importer para converter os dados de áudio brutos em uma sound wave reproduzível.
- Blueprint
- C++
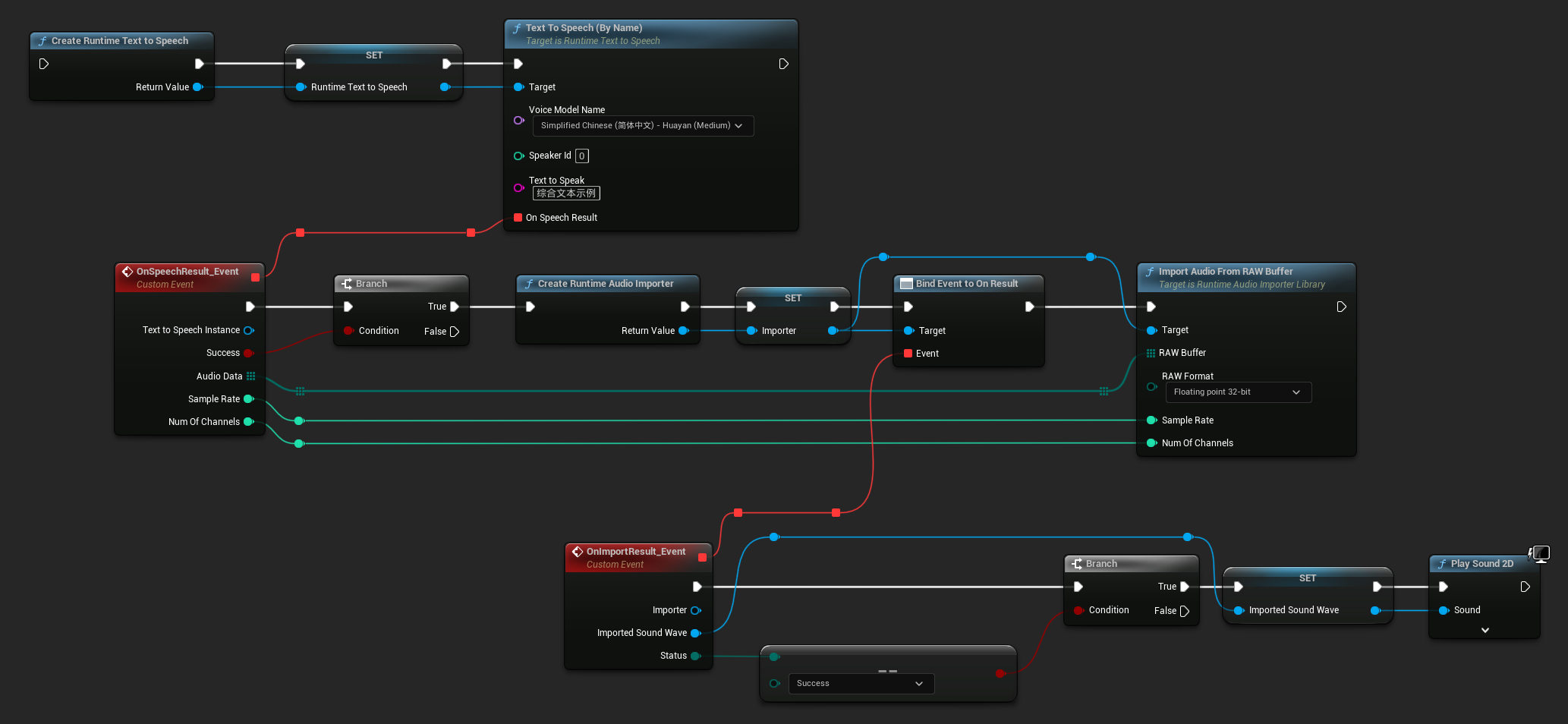
Aqui está um exemplo de como os nodes de Blueprint para sintetizar texto e reproduzir o áudio podem parecer (Nodes copiáveis):
Aqui está um exemplo de como sintetizar texto e reproduzir o áudio em C++:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Para text-to-speech em streaming, você receberá dados de áudio em chunks como dados PCM em formato float (como um array de bytes em Blueprints ou TArray<uint8> em C++), juntamente com a Taxa de Amostragem e o Número de Canais. Cada chunk pode ser processado imediatamente assim que estiver disponível.
Para reprodução em tempo real, é recomendado usar o plugin Runtime Audio Importer com a Streaming Sound Wave, que é especificamente projetada para reprodução de áudio em streaming ou processamento em tempo real.
- Blueprint
- C++
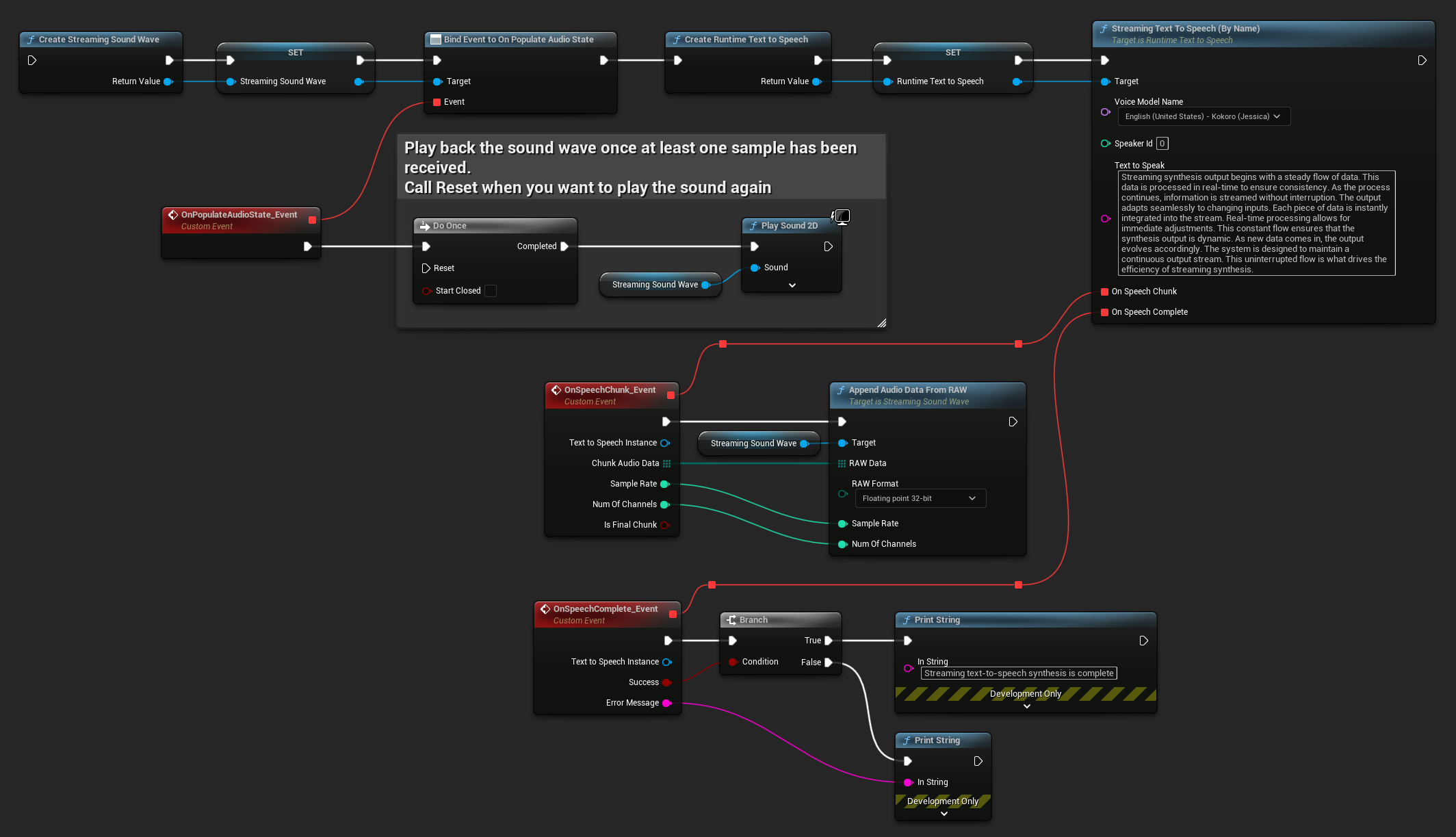
Aqui está um exemplo de como os nodes de Blueprint para text-to-speech em streaming e reprodução do áudio podem parecer (Nodes copiáveis):
Aqui está um exemplo de como implementar text-to-speech em streaming com reprodução em tempo real em C++:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Cancelando Text-to-Speech
Você pode cancelar uma operação de síntese de texto-para-voz em andamento a qualquer momento chamando a função CancelSpeechSynthesis na sua instância do sintetizador:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Quando uma síntese é cancelada:
- O processo de síntese será interrompido o mais rápido possível
- Quaisquer callbacks em andamento serão terminados
- O delegate de conclusão será chamado com
bSuccess = falsee uma mensagem de erro indicando que a síntese foi cancelada - Quaisquer recursos alocados para a síntese serão devidamente limpos
Isso é particularmente útil para textos longos ou quando você precisa interromper a reprodução para iniciar uma nova síntese.
Seleção de Speaker
Ambas as funções Text To Speech aceitam um parâmetro opcional de ID do speaker, o que é útil ao trabalhar com modelos de voz que suportam múltiplos speakers. Você pode usar as funções GetSpeakerCountFromVoiceModel ou GetSpeakerCountFromModelName para verificar se múltiplos speakers são suportados pelo seu modelo de voz escolhido. Se múltiplos speakers estiverem disponíveis, simplesmente especifique o ID do speaker desejado ao chamar as funções Text To Speech. Alguns modelos de voz oferecem uma variedade extensa - por exemplo, o English LibriTTS inclui mais de 900 speakers diferentes para escolher.
O plugin Runtime Audio Importer também fornece recursos adicionais como exportar dados de áudio para um arquivo, passá-los para SoundCue, MetaSound e mais. Para mais detalhes, confira a documentação do Runtime Audio Importer.