Comment utiliser le plugin
Le plugin Runtime Text To Speech synthétise du texte en parole en utilisant des modèles vocaux téléchargeables. Ces modèles sont gérés dans les paramètres du plugin au sein de l'éditeur, téléchargés, et empaquetés pour une utilisation au runtime. Suivez les étapes ci-dessous pour commencer.
Côté éditeur
Téléchargez les modèles vocaux appropriés pour votre projet comme décrit ici. Vous pouvez télécharger plusieurs modèles vocaux en même temps.
Côté runtime
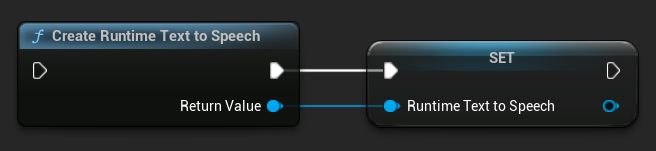
Créez le synthétiseur en utilisant la fonction CreateRuntimeTextToSpeech. Assurez-vous de maintenir une référence vers celui-ci (par exemple, en tant que variable séparée dans Blueprints ou UPROPERTY en C++) pour éviter qu'il ne soit garbage collecté.
- Blueprint
- C++
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Synthèse vocale
Le plugin offre deux modes de synthèse vocale :
- Synthèse vocale standard : Synthétise l'intégralité du texte et retourne l'audio complet une fois terminé
- Synthèse vocale en streaming : Fournit des segments audio au fur et à mesure de leur génération, permettant un traitement en temps réel
Chaque mode prend en charge deux méthodes pour sélectionner les modèles vocaux :
- Par nom : Sélectionne un modèle vocal par son nom (recommandé pour UE 5.4+)
- Par objet : Sélectionne un modèle vocal par référence directe (recommandé pour UE 5.3 et versions antérieures)
Synthèse vocale standard
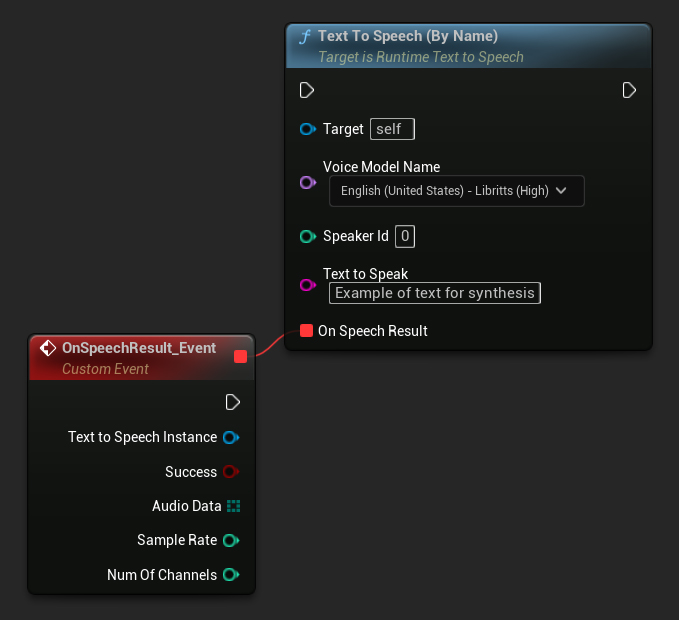
Par nom
- Blueprint
- C++
La fonction Text To Speech (By Name) est plus pratique dans les Blueprints à partir d'UE 5.4. Elle vous permet de sélectionner les modèles vocaux dans une liste déroulante des modèles téléchargés. Dans les versions UE inférieures à 5.3, cette liste déroulante n'apparaît pas, donc si vous utilisez une version plus ancienne, vous devrez parcourir manuellement le tableau des modèles vocaux retourné par GetDownloadedVoiceModels pour sélectionner celui dont vous avez besoin.
En C++, la sélection des modèles vocaux peut être légèrement plus complexe en raison de l'absence de liste déroulante. Vous pouvez utiliser la fonction GetDownloadedVoiceModelNames pour récupérer les noms des modèles vocaux téléchargés et sélectionner celui dont vous avez besoin. Ensuite, vous pouvez appeler la fonction TextToSpeechByName pour synthétiser du texte en utilisant le nom du modèle vocal sélectionné.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
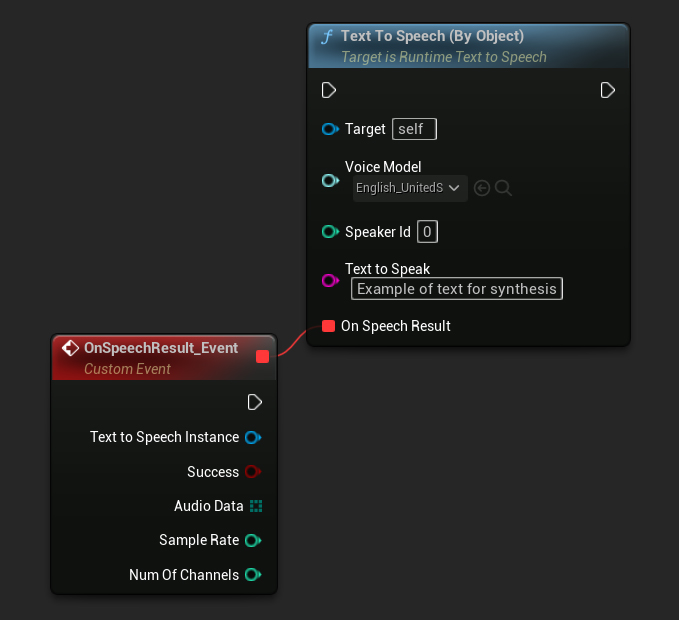
Par Objet
- Blueprint
- C++
La fonction Text To Speech (By Object) fonctionne sur toutes les versions d'Unreal Engine mais présente les modèles vocaux sous forme de liste déroulante de références d'assets, ce qui est moins intuitif. Cette méthode est adaptée pour UE 5.3 et versions antérieures, ou si votre projet nécessite une référence directe à un asset de modèle vocal pour une raison quelconque.
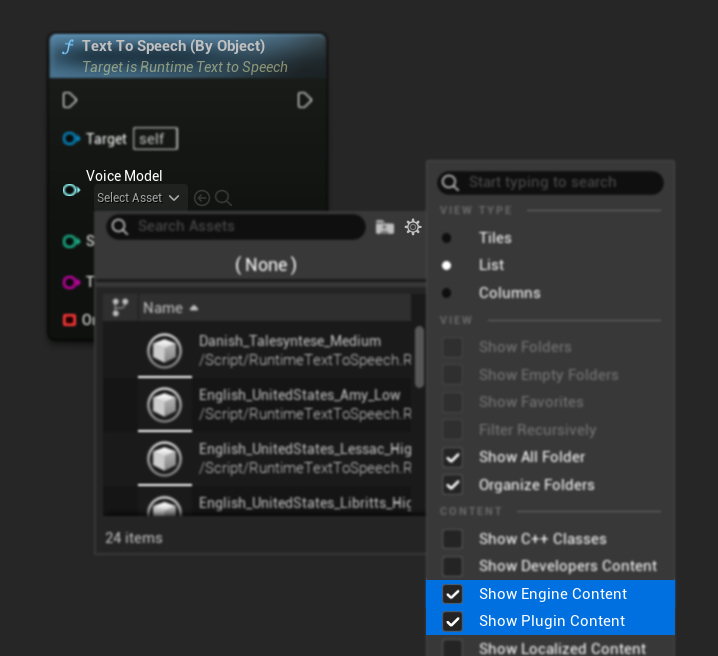
Si vous avez téléchargé les modèles mais ne pouvez pas les voir, ouvrez la liste déroulante Voice Model, cliquez sur les paramètres (icône d'engrenage), et activez à la fois Show Plugin Content et Show Engine Content pour rendre les modèles visibles.
En C++, la sélection des modèles vocaux peut être légèrement plus complexe en raison de l'absence de liste déroulante. Vous pouvez utiliser la fonction GetDownloadedVoiceModelNames pour récupérer les noms des modèles vocaux téléchargés et sélectionner celui dont vous avez besoin. Ensuite, vous pouvez appeler la fonction GetVoiceModelFromName pour obtenir l'objet du modèle vocal et le passer à la fonction TextToSpeechByObject pour synthétiser le texte.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Synthèse vocale en streaming
Pour les textes plus longs ou lorsque vous souhaitez traiter les données audio en temps réel au fur et à mesure de leur génération, vous pouvez utiliser les versions en streaming des fonctions de synthèse vocale :
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNameen C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjecten C++)
Ces fonctions fournissent les données audio par morceaux au fur et à mesure de leur génération, permettant un traitement immédiat sans attendre la fin de la synthèse complète. Ceci est utile pour diverses applications comme la lecture audio en temps réel, la visualisation en direct, ou tout scénario où vous devez traiter les données vocales de manière incrémentielle.
Streaming par nom
- Blueprint
- C++
La fonction Streaming Text To Speech (By Name) fonctionne de manière similaire à la version standard mais fournit l'audio par morceaux via le délégué On Speech Chunk.
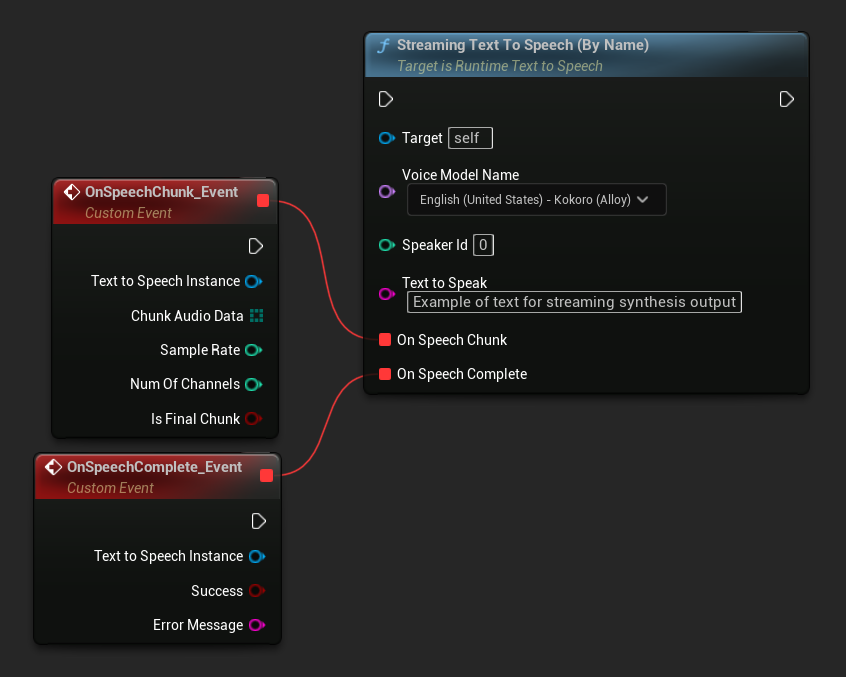
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming Par Objet
- Blueprint
- C++
La fonction Streaming Text To Speech (By Object) offre la même fonctionnalité de streaming mais prend une référence d'objet de modèle vocal.
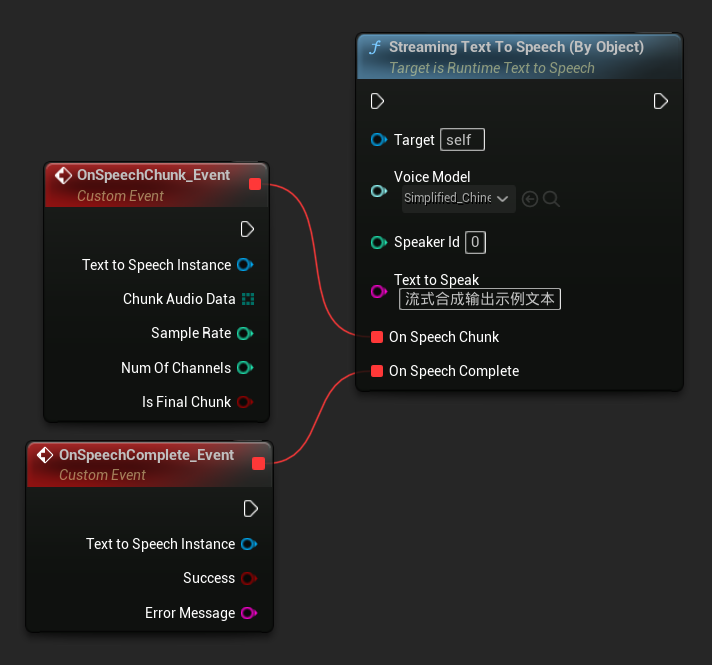
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Lecture audio
- Lecture régulière
- Lecture en Flux
Pour la synthèse vocale standard (non-streaming), le délégué On Speech Result fournit l'audio synthétisé sous forme de données PCM au format float (sous forme de tableau d'octets dans Blueprints ou TArray<uint8> en C++), ainsi que la Sample Rate et le Num Of Channels.
Pour la lecture, il est recommandé d'utiliser le plugin Runtime Audio Importer pour convertir les données audio brutes en une onde sonore jouable.
- Blueprint
- C++
Voici un exemple de ce à quoi pourraient ressembler les nœuds Blueprint pour synthétiser du texte et lire l'audio (Nœuds copiables) :
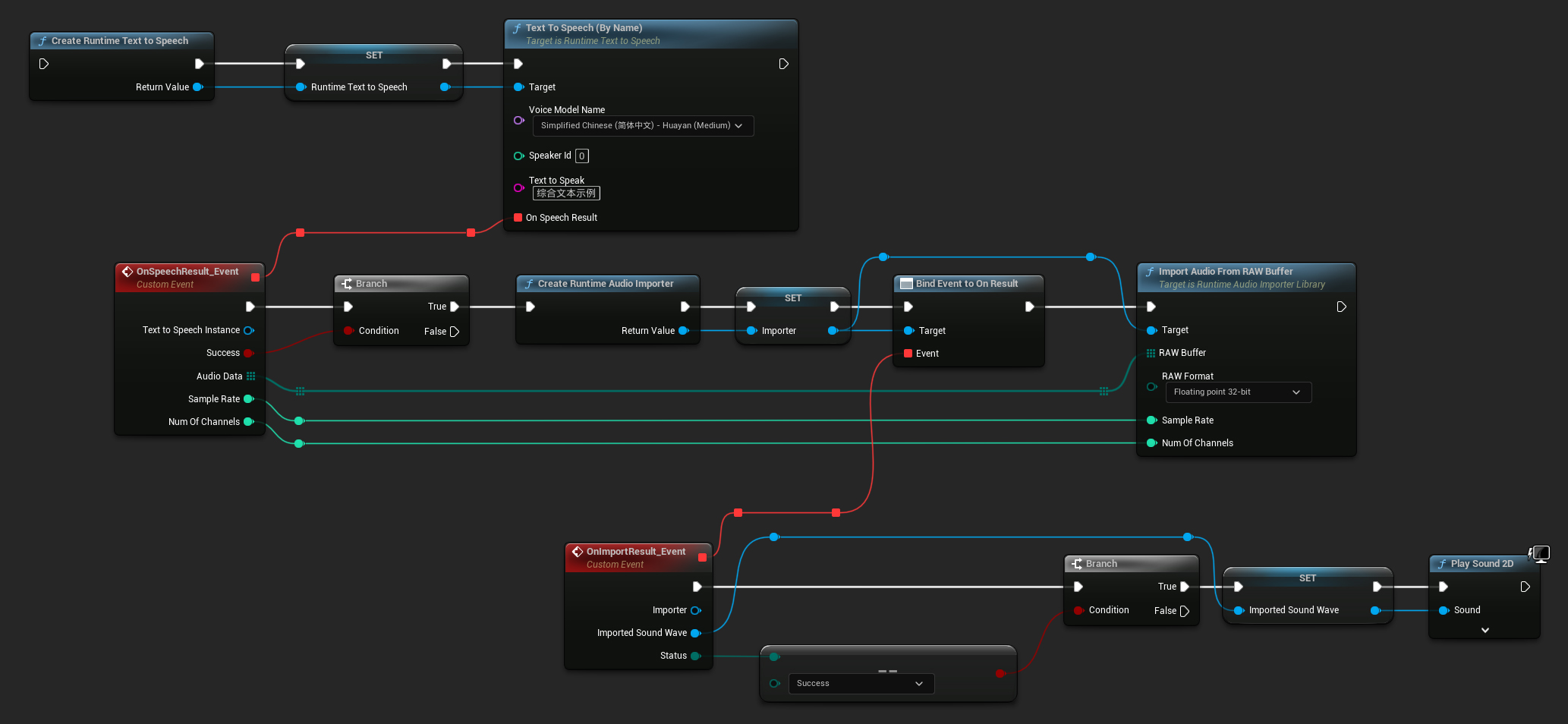
Voici un exemple de comment synthétiser du texte et lire l'audio en C++ :
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Pour la synthèse vocale en flux, vous recevrez les données audio par morceaux sous forme de données PCM au format float (sous forme de tableau d'octets dans Blueprints ou TArray<uint8> en C++), ainsi que la Fréquence d'échantillonnage et le Nombre de canaux. Chaque morceau peut être traité immédiatement dès qu'il est disponible.
Pour la lecture en temps réel, il est recommandé d'utiliser le plugin Runtime Audio Importer et sa Onde Sonore en Flux, qui est spécialement conçu pour la lecture audio en flux ou le traitement en temps réel.
- Blueprint
- C++
Voici un exemple de ce à quoi pourraient ressembler les nœuds Blueprint pour la synthèse vocale en flux et la lecture audio (Nœuds copiables) :
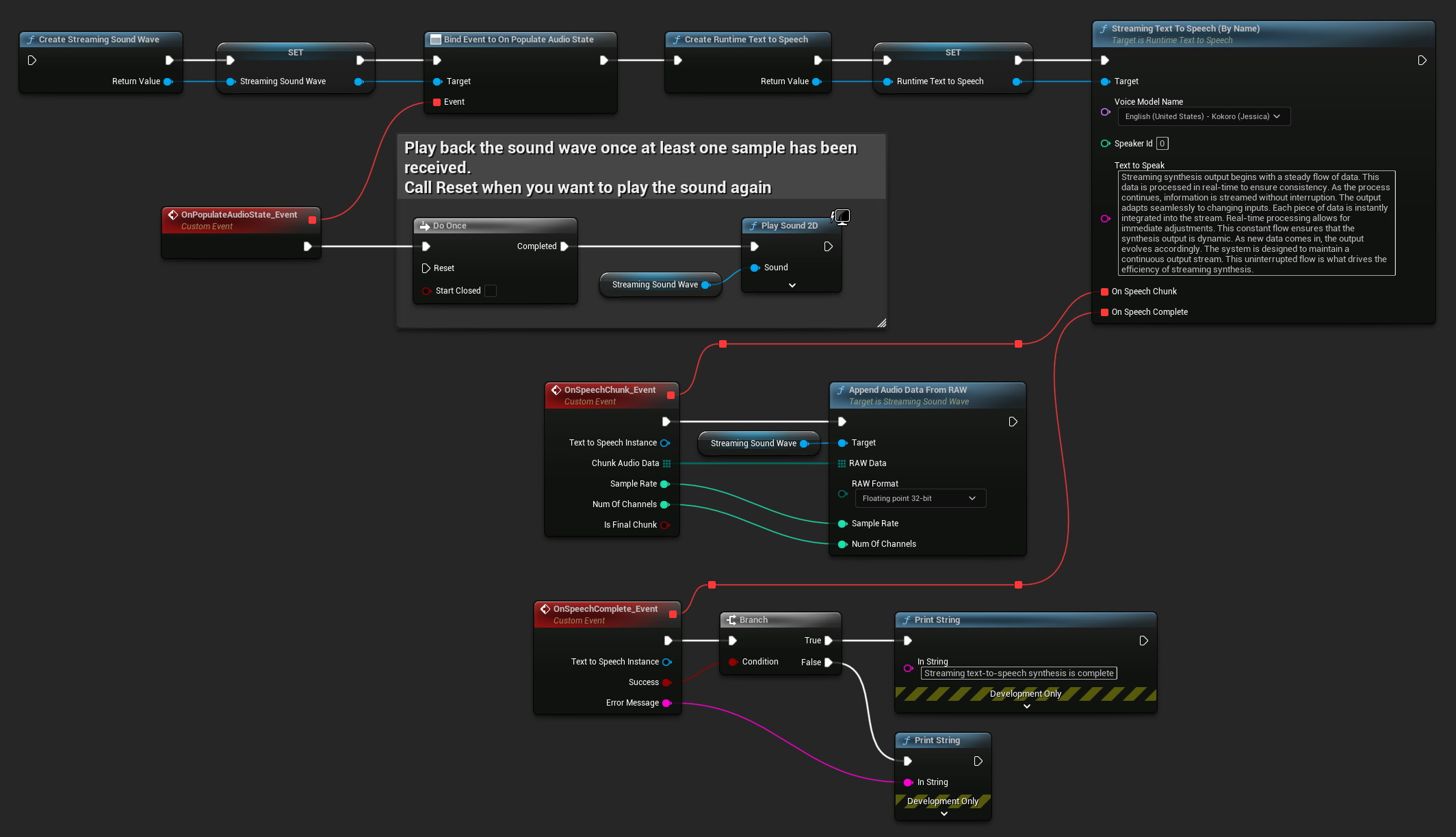
Voici un exemple de comment implémenter la synthèse vocale en flux avec lecture en temps réel en C++ :
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Annulation de la synthèse vocale
Vous pouvez annuler une opération de synthèse vocale en cours à tout moment en appelant la fonction CancelSpeechSynthesis sur votre instance de synthétiseur :
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Lorsqu'une synthèse est annulée :
- Le processus de synthèse s'arrêtera dès que possible
- Tous les rappels en cours seront interrompus
- Le délégué de complétion sera appelé avec
bSuccess = falseet un message d'erreur indiquant que la synthèse a été annulée - Toutes les ressources allouées pour la synthèse seront correctement libérées
Cela est particulièrement utile pour les textes longs ou lorsque vous devez interrompre la lecture pour démarrer une nouvelle synthèse.
Sélection du Locuteur
Les deux fonctions Text To Speech acceptent un paramètre optionnel d'ID de locuteur, ce qui est utile lorsque vous travaillez avec des modèles vocaux qui prennent en charge plusieurs locuteurs. Vous pouvez utiliser les fonctions GetSpeakerCountFromVoiceModel ou GetSpeakerCountFromModelName pour vérifier si plusieurs locuteurs sont pris en charge par votre modèle vocal choisi. Si plusieurs locuteurs sont disponibles, spécifiez simplement l'ID de locuteur souhaité lors de l'appel des fonctions Text To Speech. Certains modèles vocaux offrent une grande variété - par exemple, English LibriTTS inclut plus de 900 locuteurs différents parmi lesquels choisir.
Le plugin Runtime Audio Importer fournit également des fonctionnalités supplémentaires telles que l'exportation des données audio vers un fichier, leur passage à un SoundCue, MetaSound, et plus encore. Pour plus de détails, consultez la documentation de Runtime Audio Importer.