So verwenden Sie das Plugin
Das Runtime Text To Speech Plugin synthetisiert Text in Sprache unter Verwendung von herunterladbaren Sprachmodellen. Diese Modelle werden in den Plugineinstellungen innerhalb des Editors verwaltet, heruntergeladen und für die Laufzeitnutzung verpackt. Befolgen Sie die folgenden Schritte, um zu beginnen.
Editor-Seite
Laden Sie die entsprechenden Sprachmodelle für Ihr Projekt herunter, wie hier beschrieben. Sie können mehrere Sprachmodelle gleichzeitig herunterladen.
Laufzeit-Seite
Erstellen Sie den Synthesizer mit der Funktion CreateRuntimeTextToSpeech. Stellen Sie sicher, dass Sie eine Referenz darauf beibehalten (z.B. als separate Variable in Blueprints oder UPROPERTY in C++), um zu verhindern, dass er vom Garbage Collector entfernt wird.
- Blueprint
- C++
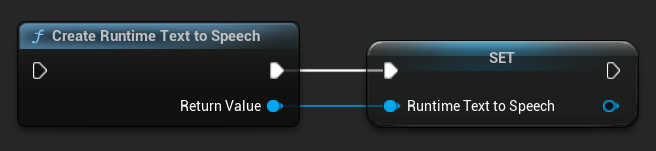
// Create the Runtime Text To Speech synthesizer in C++
URuntimeTextToSpeech* Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
// Ensure the synthesizer is referenced correctly to prevent garbage collection (e.g. as a UPROPERTY)
Sprachsynthese
Das Plugin bietet zwei Modi für die Text-zu-Sprache-Synthese:
- Reguläre Text-zu-Sprache-Synthese: Synthetisiert den gesamten Text und gibt die vollständige Audioausgabe zurück, wenn sie fertig ist
- Streaming Text-zu-Sprache-Synthese: Liefert Audioblöcke, sobald sie generiert werden, und ermöglicht so eine Echtzeitverarbeitung
Jeder Modus unterstützt zwei Methoden zur Auswahl von Sprachmodellen:
- Nach Name: Wählen Sie ein Sprachmodell anhand seines Namens aus (empfohlen für UE 5.4+)
- Nach Objekt: Wählen Sie ein Sprachmodell durch direkten Verweis aus (empfohlen für UE 5.3 und früher)
Reguläre Text-zu-Sprache-Synthese
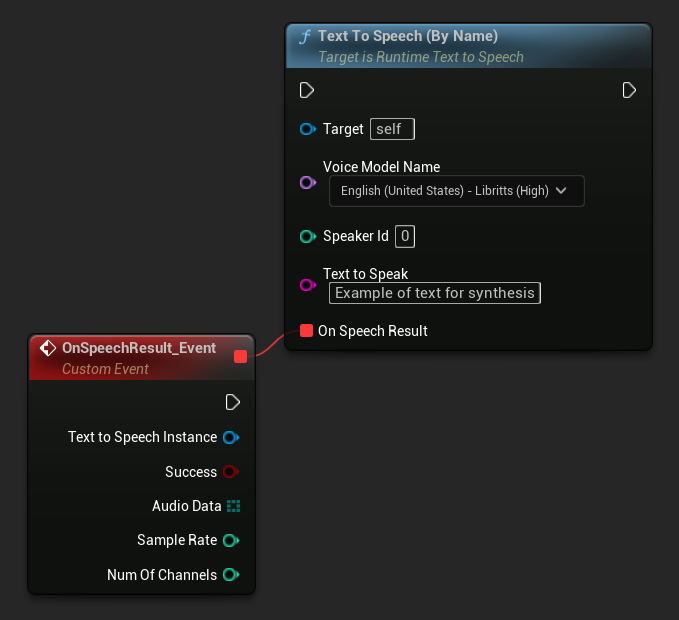
Nach Name
- Blueprint
- C++
Die Funktion Text To Speech (By Name) ist in Blueprints ab UE 5.4 bequemer. Sie ermöglicht es Ihnen, Sprachmodelle aus einer Dropdown-Liste der heruntergeladenen Modelle auszuwählen. In UE-Versionen unter 5.3 erscheint diese Dropdown-Liste nicht. Wenn Sie also eine ältere Version verwenden, müssen Sie manuell über das Array der von GetDownloadedVoiceModels zurückgegebenen Sprachmodelle iterieren, um das gewünschte auszuwählen.
In C++ kann die Auswahl von Sprachmodellen aufgrund des Fehlens einer Dropdown-Liste etwas komplexer sein. Sie können die Funktion GetDownloadedVoiceModelNames verwenden, um die Namen der heruntergeladenen Sprachmodelle abzurufen und das gewünschte auszuwählen. Anschließend können Sie die Funktion TextToSpeechByName aufrufen, um Text mit dem ausgewählten Sprachmodellnamen zu synthetisieren.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, just as an example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
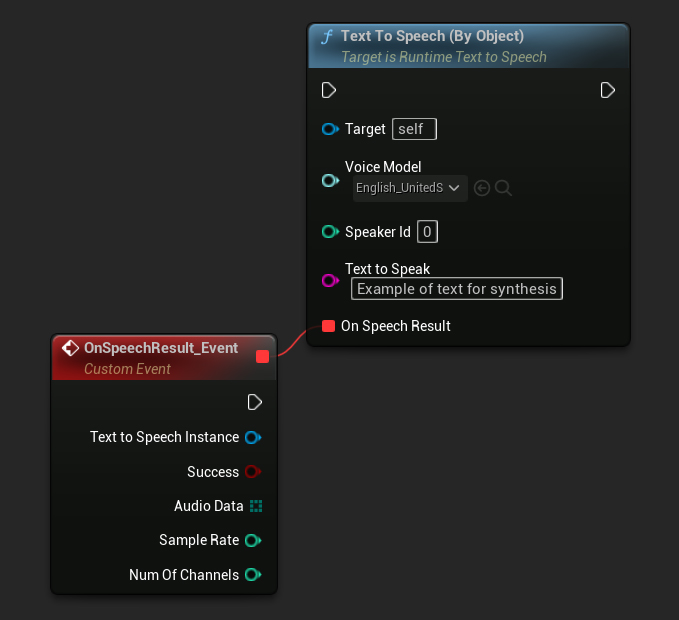
Nach Objekt
- Blueprint
- C++
Die Text To Speech (By Object)-Funktion funktioniert in allen Versionen der Unreal Engine, stellt die Sprachmodelle jedoch als Dropdown-Liste von Asset-Referenzen dar, was weniger intuitiv ist. Diese Methode eignet sich für UE 5.3 und früher oder wenn Ihr Projekt aus irgendeinem Grund eine direkte Referenz auf ein Sprachmodell-Asset erfordert.
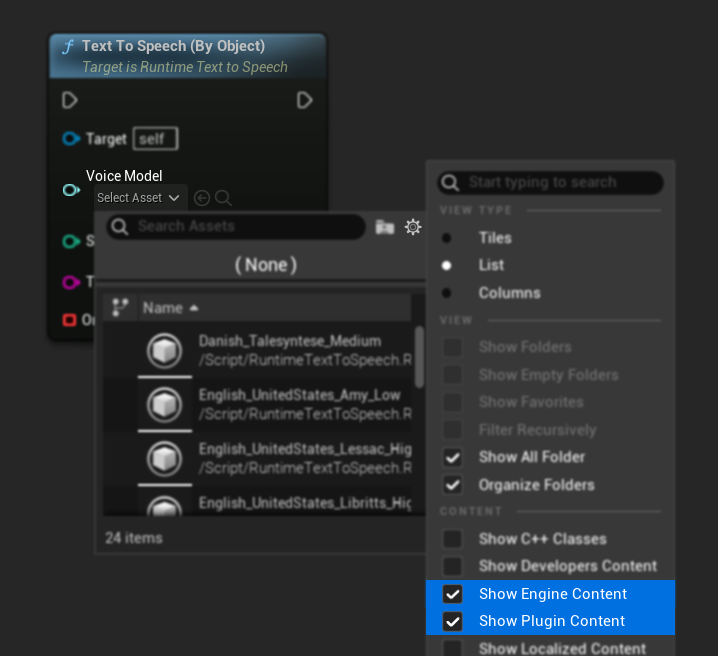
Wenn Sie die Modelle heruntergeladen haben, sie aber nicht sehen können, öffnen Sie das Dropdown-Menü Voice Model, klicken Sie auf die Einstellungen (Zahnradsymbol) und aktivieren Sie sowohl Show Plugin Content als auch Show Engine Content, um die Modelle sichtbar zu machen.
In C++ kann die Auswahl der Sprachmodelle aufgrund des Fehlens einer Dropdown-Liste etwas komplexer sein. Sie können die Funktion GetDownloadedVoiceModelNames verwenden, um die Namen der heruntergeladenen Sprachmodelle abzurufen und das gewünschte auszuwählen. Anschließend können Sie die Funktion GetVoiceModelFromName aufrufen, um das Sprachmodell-Objekt zu erhalten und es an die Funktion TextToSpeechByObject zu übergeben, um Text zu synthetisieren.
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->TextToSpeechByObject(VoiceModel, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumChannels)
{
UE_LOG(LogTemp, Log, TEXT("TextToSpeech result: %s, AudioData size: %d, SampleRate: %d, NumChannels: %d"), bSuccess ? TEXT("Success") : TEXT("Failed"), AudioData.Num(), SampleRate, NumChannels);
}));
return;
}
Streaming Text-to-Speech
Für längere Texte oder wenn Sie Audiodaten in Echtzeit verarbeiten möchten, während sie generiert werden, können Sie die Streaming-Versionen der Text-to-Speech-Funktionen verwenden:
Streaming Text To Speech (By Name)(StreamingTextToSpeechByNamein C++)Streaming Text To Speech (By Object)(StreamingTextToSpeechByObjectin C++)
Diese Funktionen liefern Audiodaten in Chunks, während sie generiert werden, was eine sofortige Verarbeitung ermöglicht, ohne auf den Abschluss der gesamten Synthese warten zu müssen. Dies ist nützlich für verschiedene Anwendungen wie Echtzeit-Audiowiedergabe, Live-Visualisierung oder jedes Szenario, in dem Sie Sprachdaten inkrementell verarbeiten müssen.
Streaming By Name
- Blueprint
- C++
Die Streaming Text To Speech (By Name)-Funktion funktioniert ähnlich wie die reguläre Version, liefert jedoch Audio in Chunks über den On Speech Chunk-Delegate.
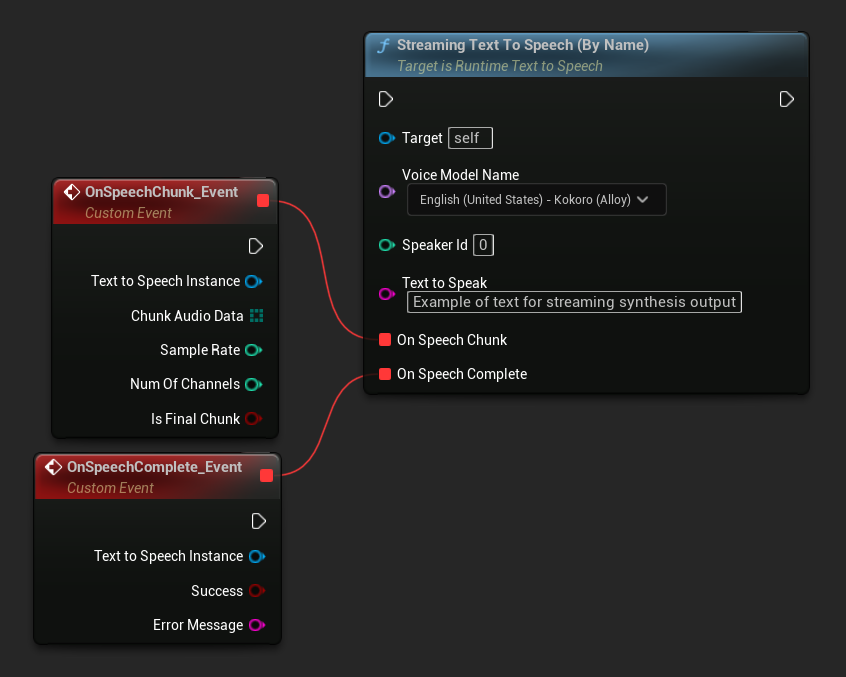
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Streaming Nach Objekt
- Blueprint
- C++
Die Funktion Streaming Text To Speech (By Object) bietet die gleiche Streaming-Funktionalität, benötigt jedoch eine Objektreferenz auf ein Sprachmodell.
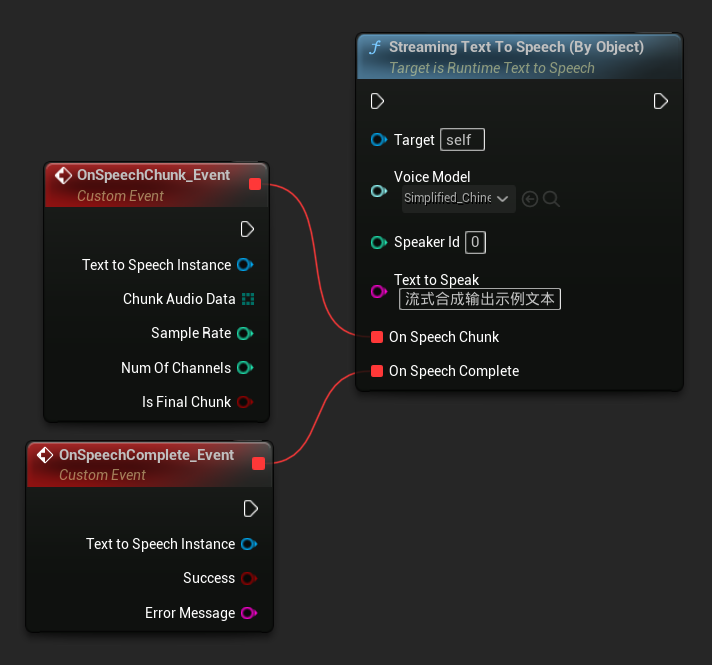
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
TSoftObjectPtr<URuntimeTTSModel> VoiceModel;
if (!URuntimeTTSLibrary::GetVoiceModelFromName(VoiceName, VoiceModel))
{
UE_LOG(LogTemp, Error, TEXT("Failed to get voice model from name: %s"), *VoiceName.ToString());
return;
}
Synthesizer->StreamingTextToSpeechByObject(
VoiceModel,
0,
TEXT("This is a long text that will be synthesized in chunks."),
FOnTTSStreamingChunkDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
// Process each chunk of audio data as it becomes available
UE_LOG(LogTemp, Log, TEXT("Received chunk %d with %d bytes of audio data. Sample rate: %d, Channels: %d, Is Final: %s"),
ChunkIndex, ChunkAudioData.Num(), SampleRate, NumOfChannels, bIsFinalChunk ? TEXT("Yes") : TEXT("No"));
// You can start processing/playing this chunk immediately
}),
FOnTTSStreamingCompleteDelegateFast::CreateLambda([](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
// Called when the entire synthesis is complete or if it fails
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming synthesis completed successfully"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
Audio-Wiedergabe
- Reguläre Wiedergabe
- Streaming Playback
Für reguläre (nicht-streaming) Text-to-Speech bietet der On Speech Result-Delegate das synthetisierte Audio als PCM-Daten im Float-Format (als Byte-Array in Blueprints oder TArray<uint8> in C++), zusammen mit der Sample Rate und Num Of Channels.
Für die Wiedergabe wird empfohlen, das Runtime Audio Importer-Plugin zu verwenden, um Roh-Audiodaten in eine abspielbare Soundwelle umzuwandeln.
- Blueprint
- C++
Hier ist ein Beispiel, wie die Blueprint-Nodes für die Text-Synthese und das Abspielen des Audios aussehen könnten (Kopierbare Nodes):
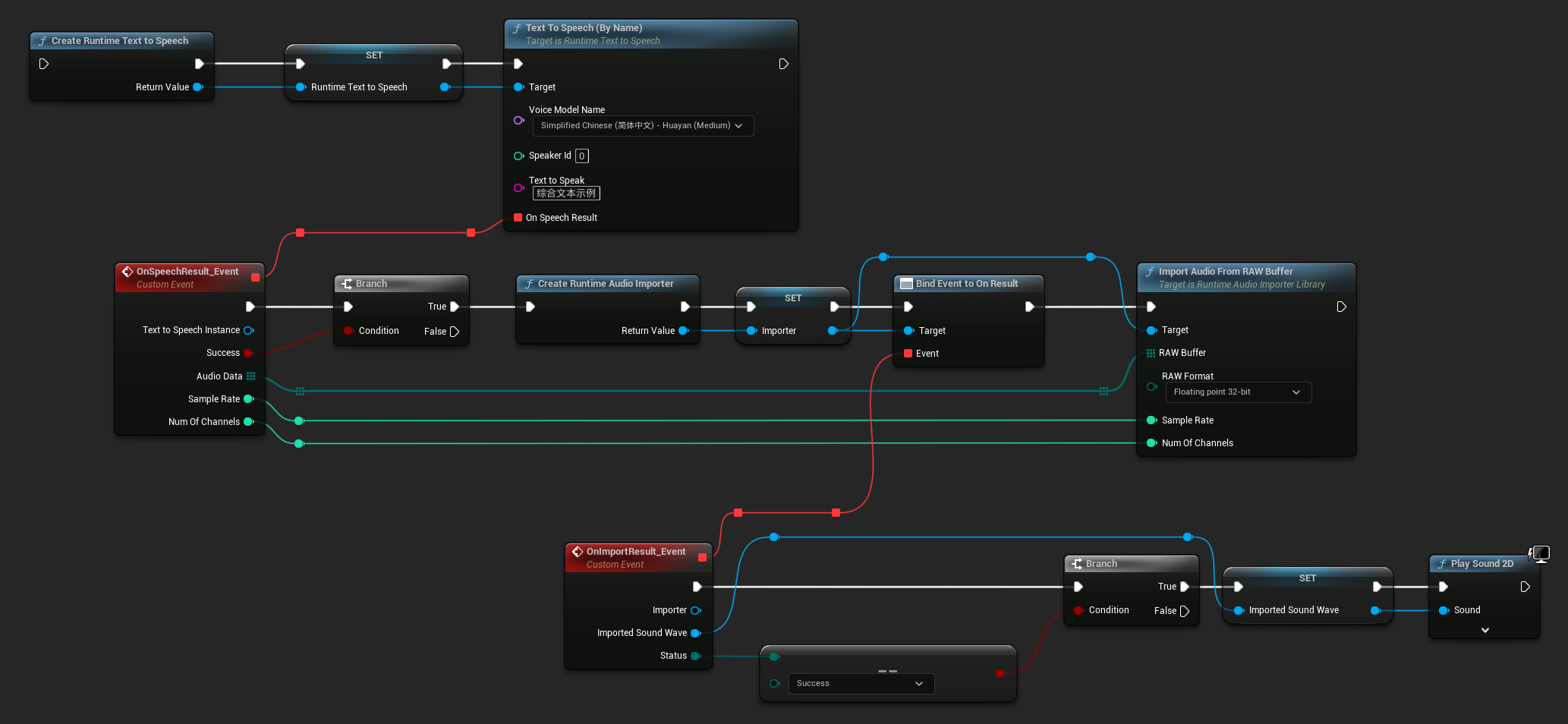
Hier ist ein Beispiel, wie man Text synthetisiert und das Audio in C++ abspielt:
// Assuming "Synthesizer" is a valid and referenced URuntimeTextToSpeech object (ensure it is not eligible for garbage collection during the callback)
// Ensure "this" is a valid and referenced UObject (must not be eligible for garbage collection during the callback)
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Text example 123"), FOnTTSResultDelegateFast::CreateLambda([this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const TArray<uint8>& AudioData, int32 SampleRate, int32 NumOfChannels)
{
if (!bSuccess)
{
UE_LOG(LogTemp, Error, TEXT("TextToSpeech failed"));
return;
}
// Create the Runtime Audio Importer to process the audio data
URuntimeAudioImporterLibrary* RuntimeAudioImporter = URuntimeAudioImporterLibrary::CreateRuntimeAudioImporter();
// Prevent the RuntimeAudioImporter from being garbage collected by adding it to the root (you can also use a UPROPERTY, TStrongObjectPtr, etc.)
RuntimeAudioImporter->AddToRoot();
RuntimeAudioImporter->OnResultNative.AddWeakLambda(RuntimeAudioImporter, [this](URuntimeAudioImporterLibrary* Importer, UImportedSoundWave* ImportedSoundWave, ERuntimeImportStatus Status)
{
// Once done, remove it from the root to allow garbage collection
Importer->RemoveFromRoot();
if (Status != ERuntimeImportStatus::SuccessfulImport)
{
UE_LOG(LogTemp, Error, TEXT("Failed to import audio, status: %s"), *UEnum::GetValueAsString(Status));
return;
}
// Play the imported sound wave (ensure a reference is kept to prevent garbage collection)
UGameplayStatics::PlaySound2D(GetWorld(), ImportedSoundWave);
});
RuntimeAudioImporter->ImportAudioFromRAWBuffer(AudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}));
return;
}
Für Streaming-Text-to-Speech erhalten Sie Audiodaten in Chunks als PCM-Daten im Float-Format (als Byte-Array in Blueprints oder TArray<uint8> in C++), zusammen mit der Sample Rate und Num Of Channels. Jeder Chunk kann sofort verarbeitet werden, sobald er verfügbar ist.
Für die Echtzeitwiedergabe wird empfohlen, die Streaming Sound Wave des Runtime Audio Importer Plugins zu verwenden, die speziell für Streaming-Audiowiedergabe oder Echtzeitverarbeitung entwickelt wurde.
- Blueprint
- C++
Hier ist ein Beispiel, wie die Blueprint-Nodes für Streaming-Text-to-Speech und das Abspielen des Audios aussehen könnten (Kopierbare Nodes):
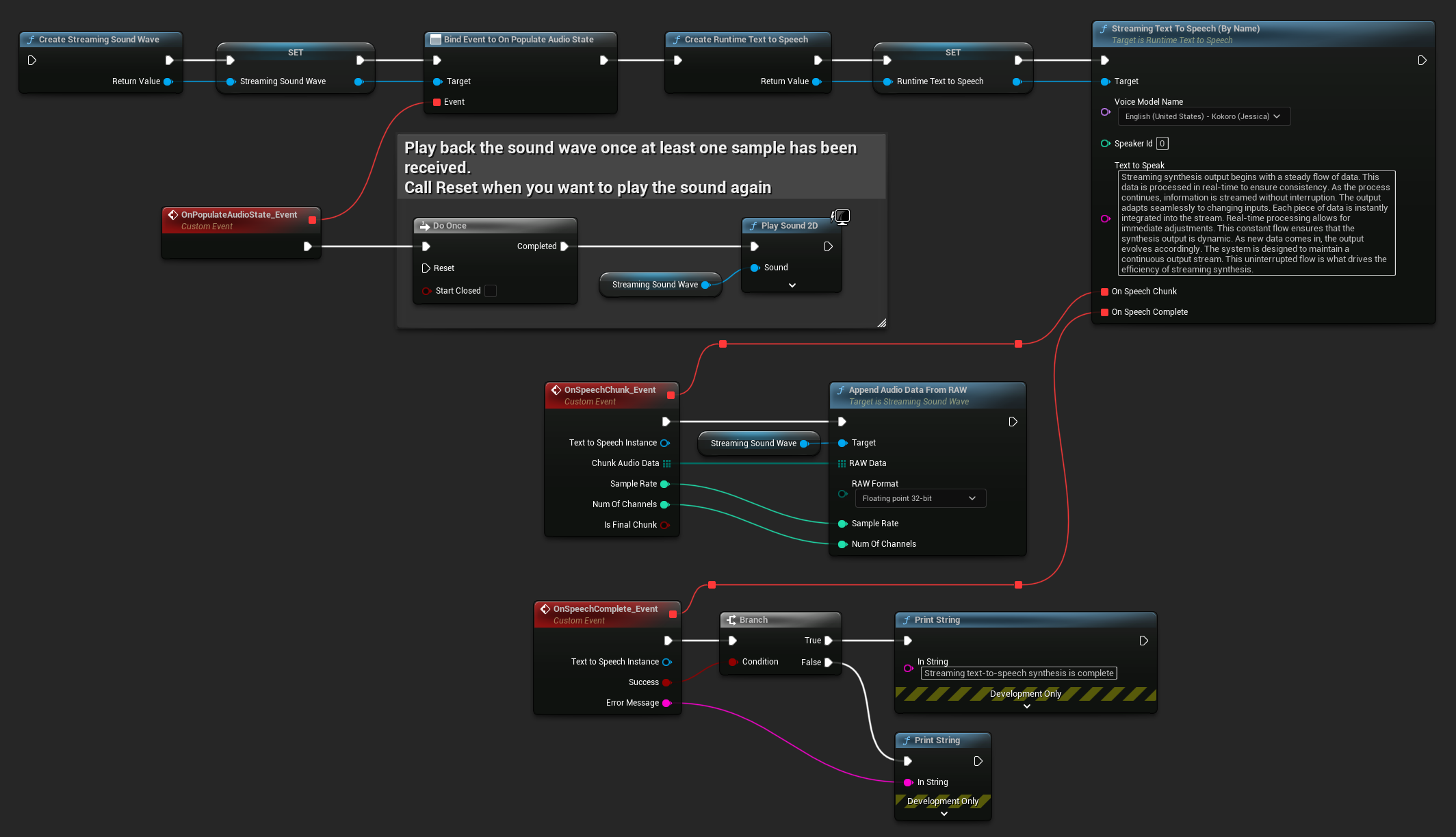
Hier ist ein Beispiel, wie Sie Streaming-Text-to-Speech mit Echtzeitwiedergabe in C++ implementieren können:
UPROPERTY()
URuntimeTextToSpeech* Synthesizer;
UPROPERTY()
UStreamingSoundWave* StreamingSoundWave;
UPROPERTY()
bool bIsPlaying = false;
void StartStreamingTTS()
{
// Create synthesizer if not already created
if (!Synthesizer)
{
Synthesizer = URuntimeTextToSpeech::CreateRuntimeTextToSpeech();
}
// Create a sound wave for streaming if not already created
if (!StreamingSoundWave)
{
StreamingSoundWave = UStreamingSoundWave::CreateStreamingSoundWave();
StreamingSoundWave->OnPopulateAudioStateNative.AddWeakLambda(this, [this]()
{
if (!bIsPlaying)
{
bIsPlaying = true;
UGameplayStatics::PlaySound2D(GetWorld(), StreamingSoundWave);
}
});
}
TArray<FName> DownloadedVoiceNames = URuntimeTTSLibrary::GetDownloadedVoiceModelNames();
// If there are downloaded voice models, use the first one to synthesize text, for example
if (DownloadedVoiceNames.Num() > 0)
{
const FName& VoiceName = DownloadedVoiceNames[0]; // Select the first available voice model
Synthesizer->StreamingTextToSpeechByName(
VoiceName,
0,
TEXT("Streaming synthesis output begins with a steady flow of data. This data is processed in real-time to ensure consistency. As the process continues, information is streamed without interruption. The output adapts seamlessly to changing inputs. Each piece of data is instantly integrated into the stream. Real-time processing allows for immediate adjustments. This constant flow ensures that the synthesis output is dynamic. As new data comes in, the output evolves accordingly. The system is designed to maintain a continuous output stream. This uninterrupted flow is what drives the efficiency of streaming synthesis."),
FOnTTSStreamingChunkDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, const TArray<uint8>& ChunkAudioData, int32 SampleRate, int32 NumOfChannels, bool bIsFinalChunk)
{
StreamingSoundWave->AppendAudioDataFromRAW(ChunkAudioData, ERuntimeRAWAudioFormat::Float32, SampleRate, NumOfChannels);
}),
FOnTTSStreamingCompleteDelegateFast::CreateWeakLambda(this, [this](URuntimeTextToSpeech* TextToSpeechInstance, bool bSuccess, const FString& ErrorMessage)
{
if (bSuccess)
{
UE_LOG(LogTemp, Log, TEXT("Streaming text-to-speech synthesis is complete"));
}
else
{
UE_LOG(LogTemp, Error, TEXT("Streaming synthesis failed: %s"), *ErrorMessage);
}
})
);
}
}
Text-to-Speech abbrechen
Sie können einen laufenden Text-to-Speech-Synthesevorgang jederzeit abbrechen, indem Sie die Funktion CancelSpeechSynthesis auf Ihrer Synthesizer-Instanz aufrufen:
- Blueprint
- C++
// Assuming "Synthesizer" is a valid URuntimeTextToSpeech instance
// Start a long synthesis operation
Synthesizer->TextToSpeechByName(VoiceName, 0, TEXT("Very long text..."), ...);
// Later, if you need to cancel it:
bool bWasCancelled = Synthesizer->CancelSpeechSynthesis();
if (bWasCancelled)
{
UE_LOG(LogTemp, Log, TEXT("Successfully cancelled ongoing synthesis"));
}
else
{
UE_LOG(LogTemp, Log, TEXT("No synthesis was in progress to cancel"));
}
Wenn eine Synthese abgebrochen wird:
- Der Syntheseprozess wird so schnell wie möglich gestoppt
- Alle laufenden Callbacks werden beendet
- Der Abschluss-Delegat wird mit
bSuccess = falseund einer Fehlermeldung aufgerufen, die anzeigt, dass die Synthese abgebrochen wurde - Alle für die Synthese zugewiesenen Ressourcen werden ordnungsgemäß bereinigt
Dies ist besonders nützlich für lange Texte oder wenn Sie die Wiedergabe unterbrechen müssen, um eine neue Synthese zu starten.
Sprecherauswahl
Beide Text To Speech-Funktionen akzeptieren einen optionalen Sprecher-ID-Parameter, der nützlich ist, wenn Sie mit Sprachmodellen arbeiten, die mehrere Sprecher unterstützen. Sie können die Funktionen GetSpeakerCountFromVoiceModel oder GetSpeakerCountFromModelName verwenden, um zu überprüfen, ob Ihr gewähltes Sprachmodell mehrere Sprecher unterstützt. Wenn mehrere Sprecher verfügbar sind, geben Sie einfach Ihre gewünschte Sprecher-ID beim Aufruf der Text To Speech-Funktionen an. Einige Sprachmodelle bieten eine große Auswahl – zum Beispiel enthält English LibriTTS über 900 verschiedene Sprecher zur Auswahl.
Das Runtime Audio Importer-Plugin bietet auch zusätzliche Funktionen wie das Exportieren von Audiodaten in eine Datei, das Übergeben an SoundCue, MetaSound und mehr. Weitere Details finden Sie in der Runtime Audio Importer-Dokumentation.