認識パラメータ一覧
これらのパラメータは、認識器が実行中でない場合にのみ設定できます。
これはWhisperで利用可能なパラメータの完全なリストではありません。最も重要なもののみをここで公開しています。必要に応じて、このリストは更新されます。
認識パラメータの設定
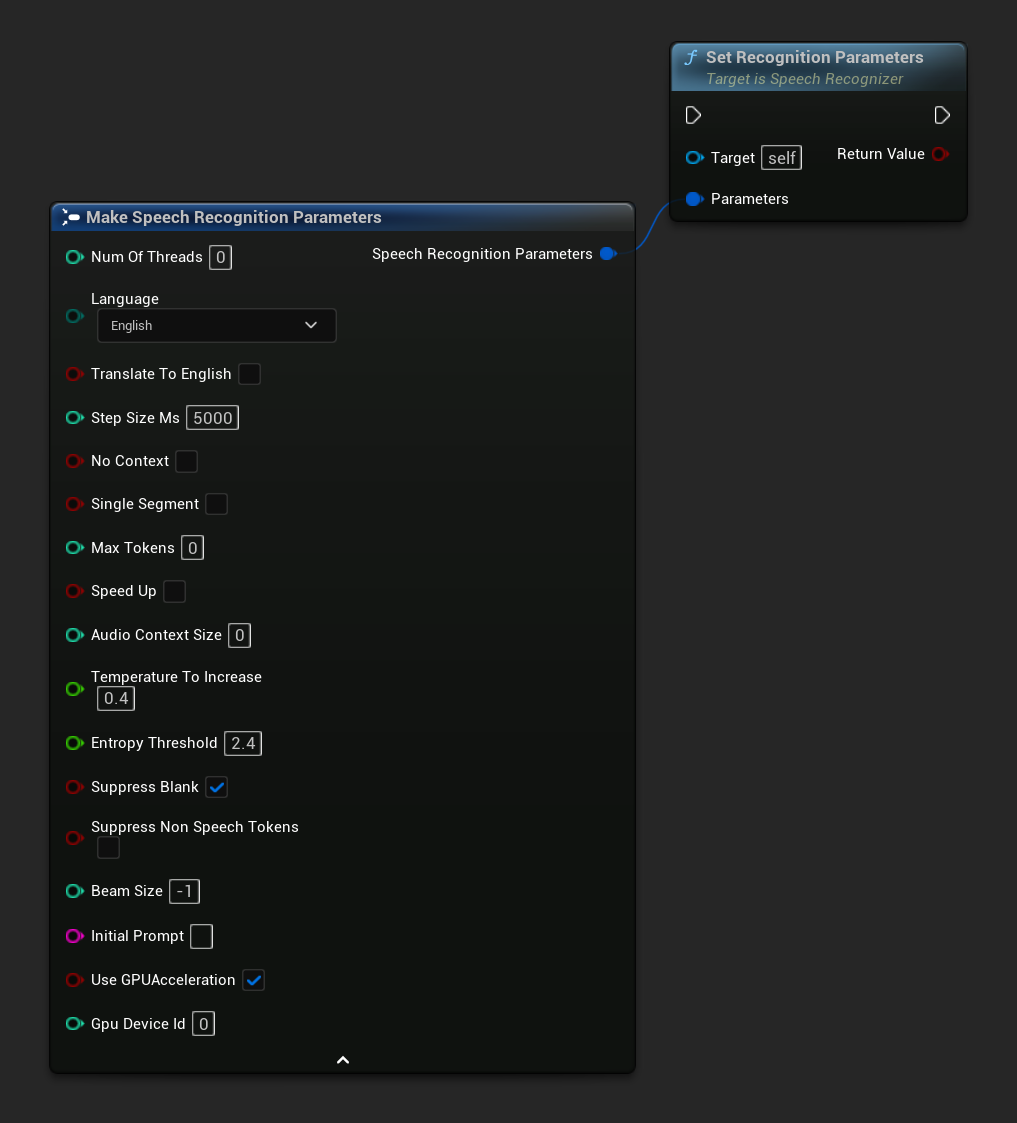
音声認識のパラメータを設定します。特定のパラメータのみを変更したい場合は、個別のセッター関数の使用を検討してください。
ストリーミングデフォルトの設定
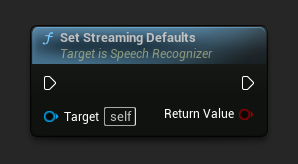
ストリーミング音声認識に適したデフォルトパラメータを設定します。
この関数は、以前に適用されたすべてのパラメータを上書きします。ストリーミングデフォルトを基本設定として使用する必要がある場合は、カスタムパラメータを設定する前にこの関数を呼び出してください。
非ストリーミングデフォルトの設定
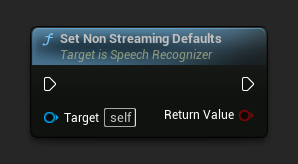
非ストリーミング音声認識に適したデフォルトパラメータを設定します。
この関数は、以前に適用されたすべてのパラメータを上書きします。非ストリーミングデフォルトを基本設定として使用する必要がある場合は、カスタムパラメータを設定する前にこの関数を呼び出してください。
スレッド数の設定
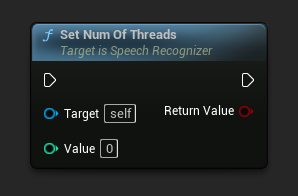
音声認識に使用するスレッド数を設定します。この値を0に設定すると、コア数が使用されます。
言語の設定
音声認識に使用する言語を設定します。エディタ設定で選択された言語モデルでサポートされている必要があります。
言語をAutoに設定すると、認識精度とパフォーマンスが低下します。
検出された言語の取得
最後の認識から検出された言語を取得します。言語を列挙値として返します。
注: この関数は認識が実行された後にのみ機能します。言語検出が失敗した場合、または実行されなかった場合はAutoを返します。これは、実際にどの言語が認識されたかを識別するためにAuto言語検出を使用する場合に特に便利です。
言語コードの取得

言語列挙値を言語コード文字列に変換します(例:En -> "en"、Fr -> "fr"、De -> "de")。
言語フルネームの取得
言語列挙値を完全な言語名に変換します(例:En -> "English"、Fr -> "French"、De -> "German")。
英語への翻訳の設定
![]()
認識された単語を英語に翻訳するかどうかを設定します。trueの場合、言語モデルは多言語対応である必要があります。
ステップサイズの設定
ミリ秒単位でステップサイズを設定します。認識のためにオーディオデータを送信する頻度を決定します。デフォルト値は5000ミリ秒(5秒)です。
コンテキストなしの設定
過去の文字起こし(存在する場合)をデコーダの初期プロンプトとして使用するかどうかを設定します。
単一セグメントの設定
単一セグメント出力を強制するかどうかを設定します(ストリーミングに便利です)。
最大トークンの設定
テキストセグメントあたりの最大トークン数を設定します。制限なしの場合は0を使用します。
高速化の設定
フェーズボコーダを使用して認識を2倍高速化するかどうかを設定します。出力の品質を向上させるにはfalseに設定します。
オーディオコンテキストサイズの設定
オーディオコンテキストのサイズを設定します。出力の品質を向上させるには0に設定します。
増加温度の設定
以下のいずれかのしきい値を満たさない場合にフォールバックする際に増加させる温度を設定します。
エントロピーしきい値の設定
エントロピーしきい値を設定します。圧縮率がこの値より高い場合、デコードは失敗したものと見なします。OpenAIの「compression_ratio_threshold」に類似しています。
空白抑制の設定
![]()
出力に空白が表示されるのを抑制するかどうかを設定します。
非音声トークン抑制の設定
出力に非音声トークンが表示されるのを抑制するかどうかを設定します。
ビームサイズの設定
ビームサーチでのビーム数を設定します。温度がゼロの場合にのみ適用されます。
初期プロンプトの設定
最初のウィンドウの初期プロンプトを設定します。これは、認識にコンテキストを提供して単語を正しく予測しやすくするために使用できます(例:カスタム語彙や固有名詞)。
効果的なプロンプト戦略の詳細については、Whisper Prompting Guideを参照してください。
GPUアクセラレーションの設定
音声認識にGPUアクセラレーションを使用するかどうかを設定します(現時点ではWindowsでのみ適用可能)。
GPUデバイスIDの設定
音声認識に使用するGPUデバイスIDを設定します。デフォルト値は0です。これは、複数のGPUを搭載したシステムで、どのGPUを認識プロセスに使用するかを指定する場合に便利です。指定されたGPUデバイスIDが無効な場合、最初に利用可能なGPUデバイスインデックスが代わりに使用されます。