プラグインの使用方法
Runtime Speech Recognizer プラグインは、入力されるオーディオデータから単語を認識するように設計されています。エンジンで動作するために、whisper.cpp の若干修正されたバージョンを使用しています。プラグインを使用するには、以下の手順に従ってください:
エディター側
- ここで説明されているように、プロジェクトに適した言語モデルを選択します。
ランタイム側
- Speech Recognizer を作成し、必要なパラメータを設定します(CreateSpeechRecognizer、パラメータについてはこちらを参照)。
- 必要なデリゲートにバインドします(OnRecognitionFinished、OnRecognizedTextSegment、OnRecognitionError)。
- 音声認識を開始します(StartSpeechRecognition)。
- オーディオデータを処理し、デリゲートからの結果を待機します(ProcessAudioData)。
- 必要に応じて(例:OnRecognitionFinished のブロードキャスト後)、音声認識を停止します。
このプラグインは、浮動小数点 32 ビット インターリーブ PCM フォーマットの入力オーディオをサポートしています。Runtime Audio Importer と連携して動作しますが、直接依存しているわけではありません。
認識パラメータ
このプラグインは、ストリーミングおよび非ストリーミングのオーディオデータ認識の両方をサポートしています。特定のユースケースに合わせて認識パラメータを調整するには、SetStreamingDefaults または SetNonStreamingDefaults を呼び出します。さらに、スレッド数、ステップサイズ、入力言語を英語に翻訳するかどうか、過去の書き起こしを使用するかどうかなど、個々のパラメータを手動で設定する柔軟性があります。利用可能なパラメータの完全なリストについては、認識パラメータリストを参照してください。
パフォーマンスの向上
プラグインのパフォーマンスを最適化する方法については、パフォーマンスを向上させる方法のセクションを参照してください。
音声活動検出 (VAD)
オーディオ入力を処理する際、特にストリーミングシナリオでは、認識エンジンに到達する前に空またはノイズのみのオーディオセグメントをフィルタリングするために、音声活動検出 (VAD) を使用することを推奨します。このフィルタリングは、Runtime Audio Importer プラグインを使用してキャプチャ可能なサウンドウェーブ側で有効にすることができ、言語モデルがノイズ内でパターンを見つけようとして誤った書き起こしを生成する「幻覚」を防ぐのに役立ちます。
最適な音声認識結果を得るためには、優れたノイズ耐性とより正確な音声検出を提供する Silero VAD プロバイダーの使用を推奨します。Silero VAD は、Runtime Audio Importer プラグインの拡張機能として利用できます。VAD の設定に関する詳細な手順については、音声活動検出のドキュメントを参照してください。
以下の例で使用されているコピー可能なノードは互換性の理由からデフォルトのVADプロバイダーを使用しています。認識精度を向上させるには、以下の手順で簡単にSilero VADに切り替えることができます:
- Silero VAD Extensionセクションで説明されているようにSilero VAD拡張をインストール
- Toggle VADノードでVADを有効にした後、Set VAD Providerノードを追加し、ドロップダウンから「Silero」を選択
プラグインに含まれるデモプロジェクトでは、VADはデフォルトで有効になっています。デモの実装に関する詳細はDemo Projectでご覧いただけます。
例
プラグインのContent -> Demoフォルダには優れたプロジェクトデモが含まれており、実装の例として使用できます。
これらの例は、Runtime Audio Importerを使用してオーディオデータを取得する例として、ストリーミングおよび非ストリーミングのオーディオ入力でRuntime Speech Recognizerプラグインを使用する方法を示しています。例で紹介されている同じオーディオインポート機能(例:キャプチャ可能なサウンドウェーブやImportAudioFromFile)にアクセスするには、RuntimeAudioImporterの別途ダウンロードが必要であることに注意してください。これらの例は核心的な概念を示すことを目的としており、エラーハンドリングは含まれていません。
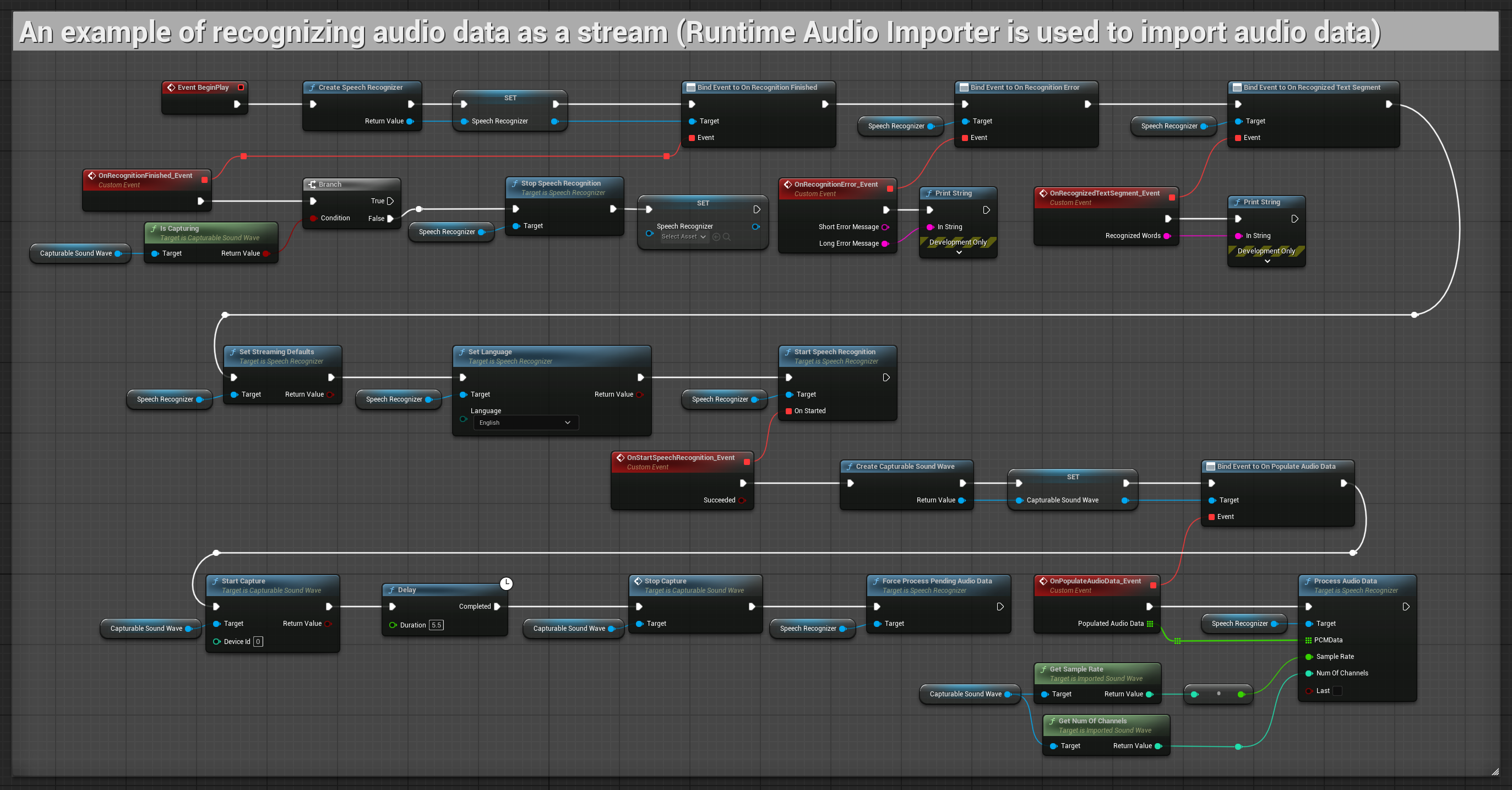
ストリーミングオーディオ入力の例
注記: UE 5.3およびその他のバージョンでは、ブループリントをコピーした後にノードが欠落している場合があります。これはエンジンバージョン間でのノードのシリアライゼーションの違いによって発生することがあります。実装ではすべてのノードが適切に接続されていることを常に確認してください。
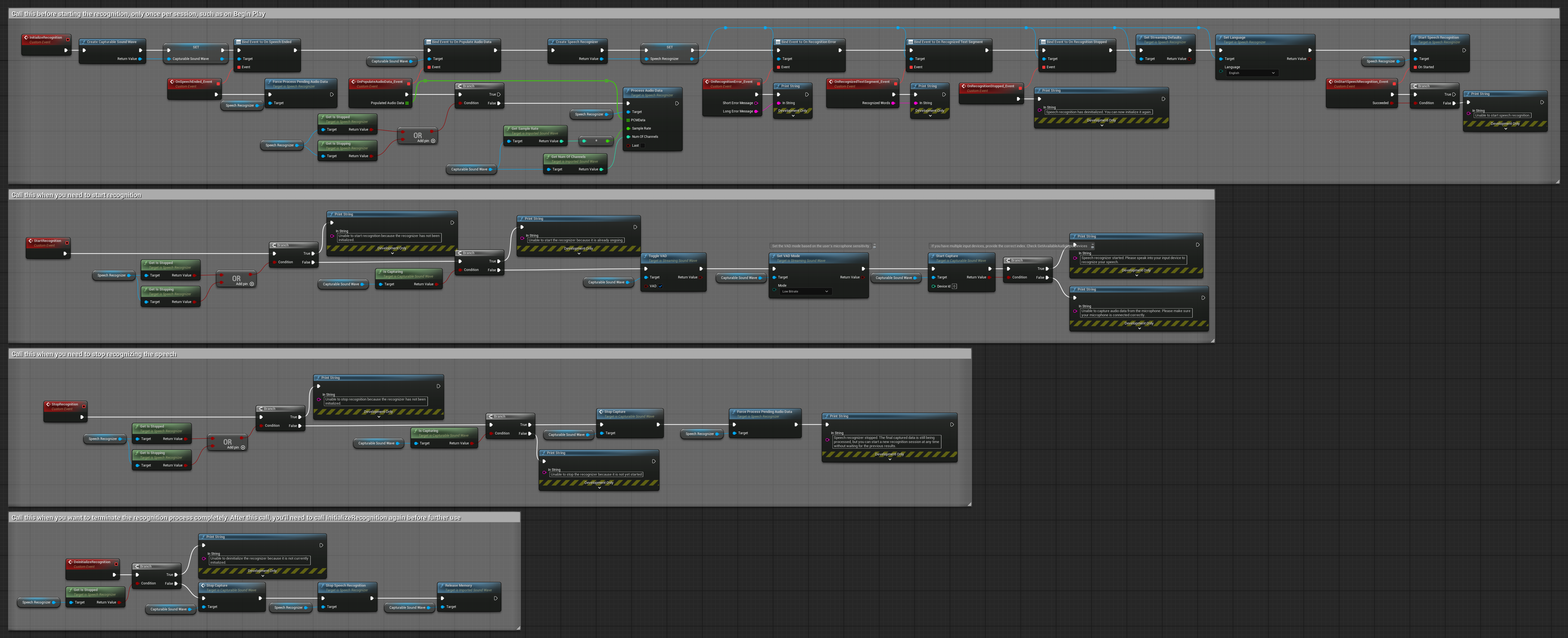
1. 基本的なストリーミング認識
この例は、マイクからオーディオデータをキャプチャ可能なサウンドウェーブを使用してストリームとしてキャプチャし、それを音声認識器に渡すための基本的なセットアップを示しています。約5秒間音声を録音し、その後認識を処理するため、簡単なテストやシンプルな実装に適しています。 コピー可能なノード.
このセットアップの主な特徴:
- 固定の5秒録音時間
- シンプルなワンショット認識
- 最小限のセットアップ要件
- テストやプロトタイピングに最適
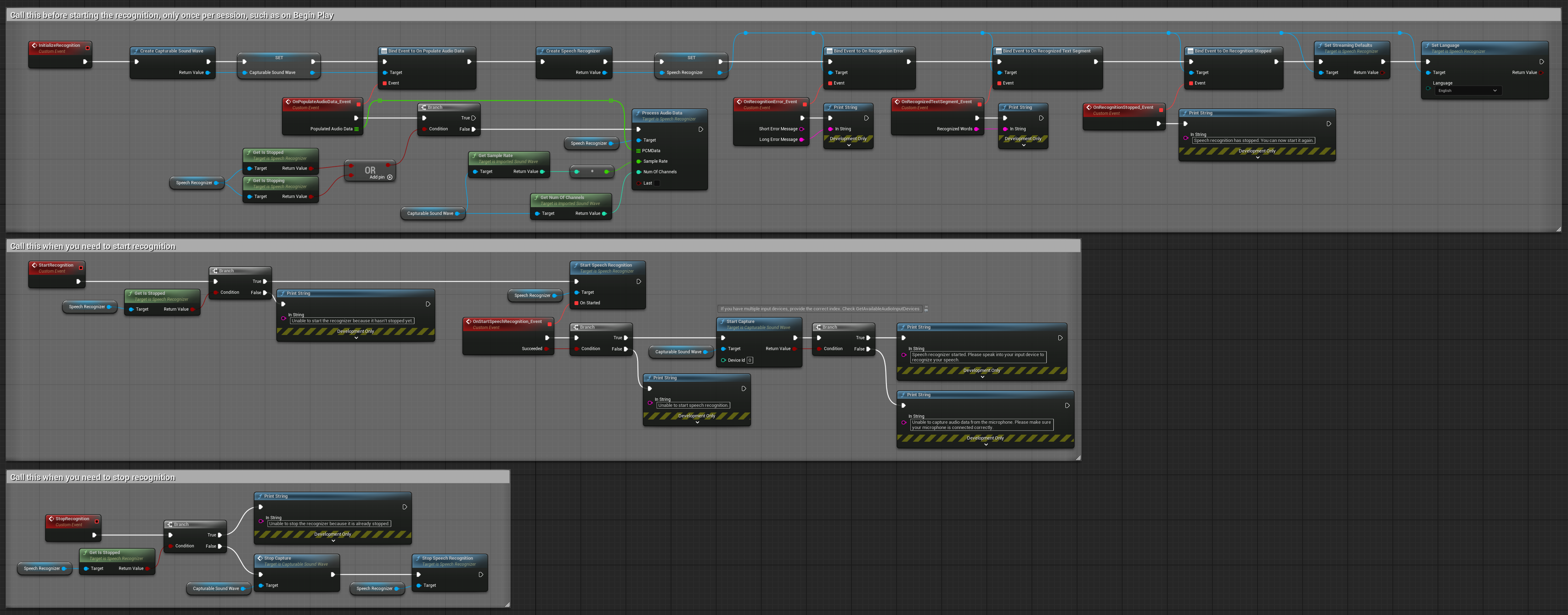
2. 制御されたストリーミング認識
この例は、基本的なストリーミングセットアップを拡張し、認識プロセスに対する手動制御を追加しています。認識を任意のタイミングで開始および停止できるため、認識が行われるタイミングを正確に制御する必要があるシナリオに適しています。コピー可能なノード.
このセットアップの主な特徴:
- 手動での開始/停止制御
- 連続認識機能
- 柔軟な録音時間
- インタラクティブアプリケーションに適しています
3. 音声アクティベートコマンド認識
この例はコマンド認識シナリオに最適化されています。ストリーミング認識とVoice Activity Detection (VAD)を組み合わせ、ユーザーが話し終えたときに自動的に音声を処理します。認識機能は沈黙が検出されたときに蓄積された音声の処理を開始するため、コマンドベースのインターフェースに理想的です。コピー可能なノード。
このセットアップの主な特徴:
- 手動での開始/停止制御
- 音声セグメントを検出するためのVoice Activity Detection (VAD)が有効
- 沈黙が検出されたときに自動的に認識をトリガー
- 短いコマンド認識に最適
- 実際の音声のみを認識することで処理オーバーヘッドを削減
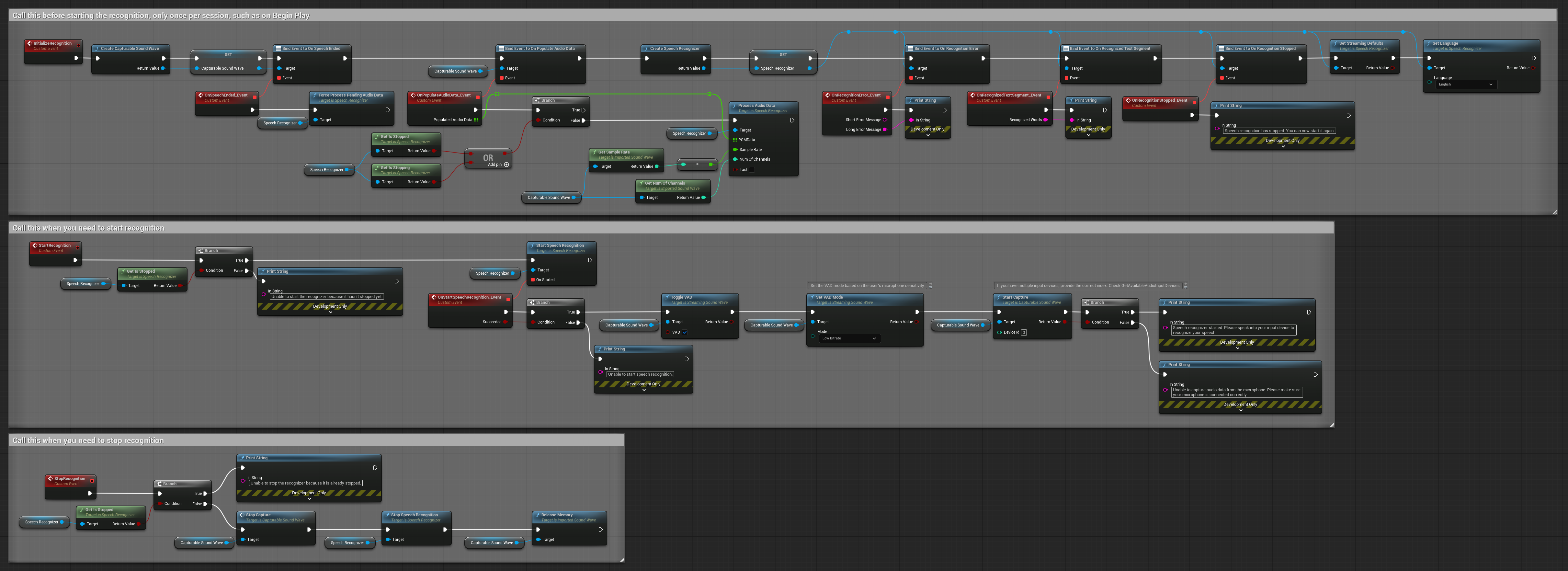
4. 最終バッファ処理付き自動初期化音声認識
この例は、異なるライフサイクル処理を持つ音声アクティベート認識アプローチの別バリエーションです。初期化中に認識機能を自動的に開始し、非初期化中に停止します。重要な特徴は、認識機能を停止する前に最後に蓄積されたオーディオバッファを処理することで、認識プロセスを終了する際に音声データが失われないことを保証することです。このセットアップは、ユーザーが発話の途中で停止した場合でも完全な発話をキャプチャする必要があるアプリケーションに特に有用です。コピー可能なノード。
このセットアップの主な特徴:
- 初期化時に認識機能を自動開始
- 非初期化時に認識機能を自動停止
- 完全に停止する前に最終オーディオバッファを処理
- 効率的な認識のためにVoice Activity Detection (VAD)を使用
- 停止時に音声データが失われないことを保証
非ストリーミングオーディオ入力
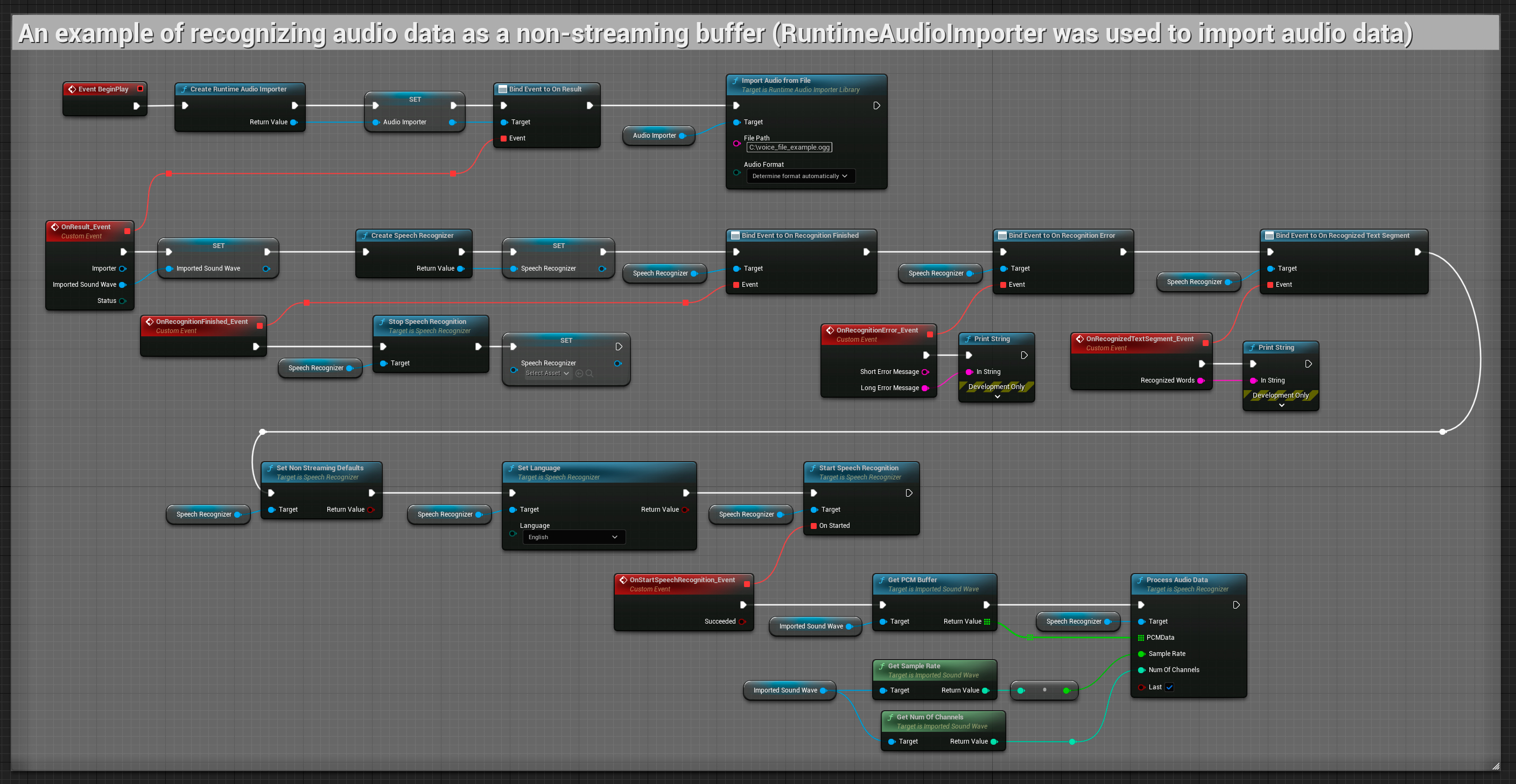
この例では、オーディオデータをImported sound waveにインポートし、インポートが完了したら完全なオーディオデータを一度に認識します。コピー可能なノード。