How to use the plugin
The Runtime Speech Recognizer plugin is designed to recognize words from incoming audio data. It uses a slightly modified version of whisper.cpp to work with the engine. To use the plugin, follow these steps:
Editor side
- Select the appropriate language models for your project as described here.
Runtime side
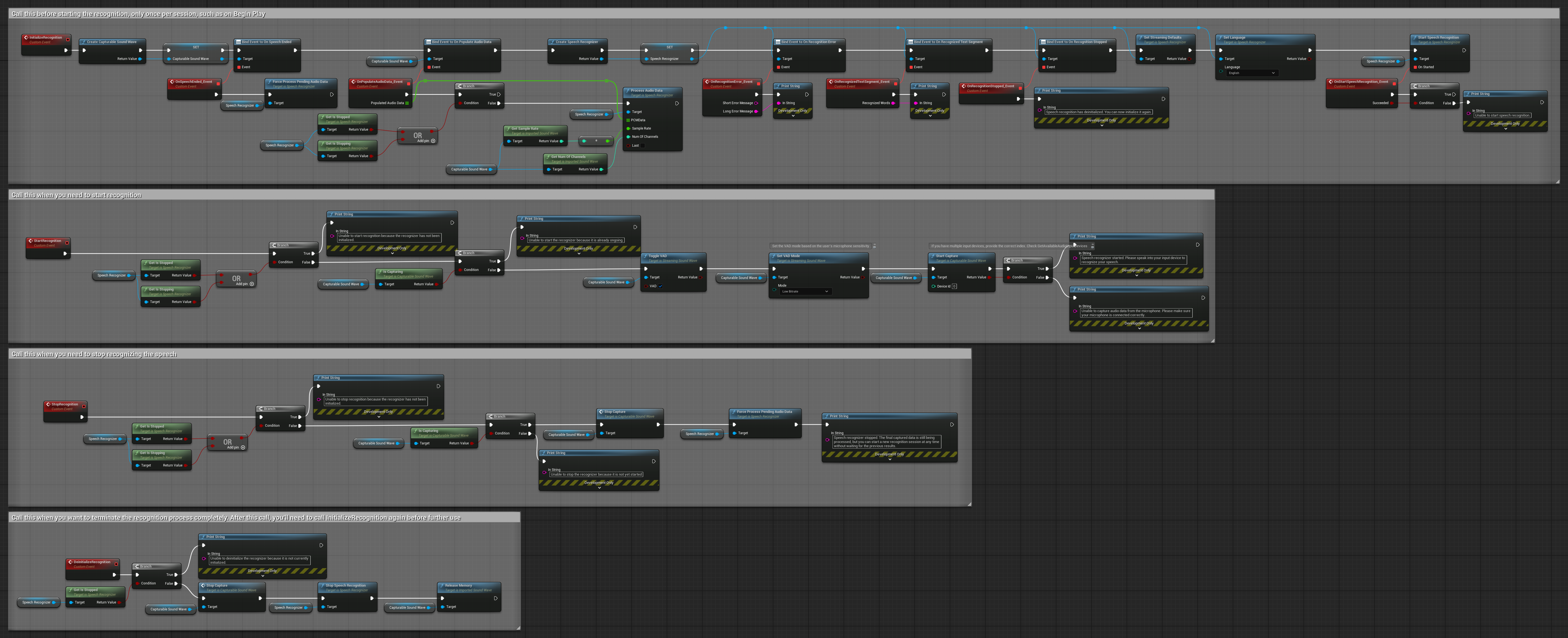
- Create a Speech Recognizer and set the necessary parameters (CreateSpeechRecognizer, for parameters see here).
- Bind to the needed delegates (OnRecognitionFinished, OnRecognizedTextSegment and OnRecognitionError).
- Start the speech recognition (StartSpeechRecognition).
- Process audio data and wait for results from the delegates (ProcessAudioData).
- Stop the speech recognizer when needed (e.g., after the OnRecognitionFinished broadcast).
The plugin supports incoming audio in the floating point 32-bit interleaved PCM format. While it works well with the Runtime Audio Importer, it doesn't directly depend on it.
Recognition parameters
The plugin supports both streaming and non-streaming audio data recognition. To adjust recognition parameters for your specific use case, call SetStreamingDefaults or SetNonStreamingDefaults. Additionally, you have the flexibility to manually set individual parameters such as the number of threads, step size, whether to translate incoming language to English, and whether to use past transcription. Refer to the Recognition Parameter List for a complete list of available parameters.
Improving performance
Please refer to the How to improve performance section for tips on how to optimize the performance of the plugin.
Voice Activity Detection (VAD)
When processing audio input, especially in streaming scenarios, it's recommended to use Voice Activity Detection (VAD) to filter out empty or noise-only audio segments before they reach the recognizer. This filtering can be enabled on the capturable sound wave side using the Runtime Audio Importer plugin, which helps prevent the language models from hallucinating - attempting to find patterns in noise and generating incorrect transcriptions.
For optimal speech recognition results, we recommend using the Silero VAD provider which offers superior noise tolerance and more accurate speech detection. The Silero VAD is available as an extension to the Runtime Audio Importer plugin. For detailed instructions on VAD configuration, refer to the Voice Activity Detection documentation.
The copyable nodes in the examples below use the default VAD provider for compatibility reasons. To enhance recognition accuracy, you can easily switch to Silero VAD by:
- Installing the Silero VAD extension as described in the Silero VAD Extension section
- After enabling VAD with the Toggle VAD node, add a Set VAD Provider node and select "Silero" from the dropdown
In the demo project included with the plugin, VAD is enabled by default. You can find more information about the demo implementation at Demo Project.
Examples
These examples illustrate how to use the Runtime Speech Recognizer plugin with both streaming and non-streaming audio input, using the Runtime Audio Importer to obtain audio data as an example. Please note that separate downloading of the RuntimeAudioImporter is required to access the same set of audio importing features showcased in the examples (e.g. capturable sound wave and ImportAudioFromFile). These examples are solely intended to illustrate the core concept and do not include error handling.
Streaming audio input examples
Note: In UE 5.3 and other versions, you might encounter missing nodes after copying Blueprints. This can occur due to differences in node serialization between engine versions. Always verify that all nodes are properly connected in your implementation.
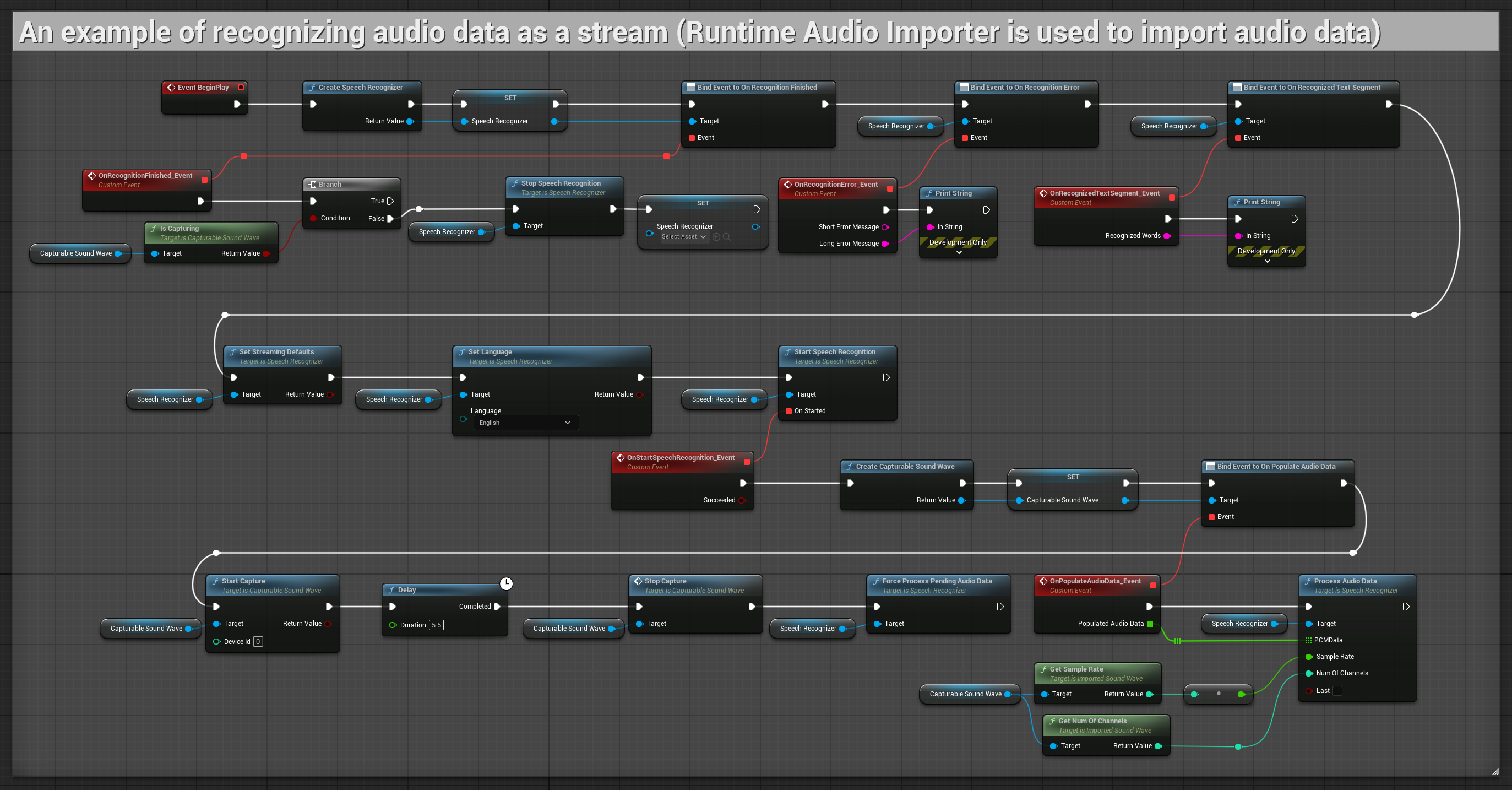
1. Basic streaming recognition
This example demonstrates the basic setup for capturing audio data from the microphone as a stream using the Capturable sound wave and passing it to the speech recognizer. It records speech for about 5 seconds and then processes the recognition, making it suitable for quick tests and simple implementations. Copyable nodes.
Key features of this setup:
- Fixed 5-second recording duration
- Simple one-shot recognition
- Minimal setup requirements
- Perfect for testing and prototyping
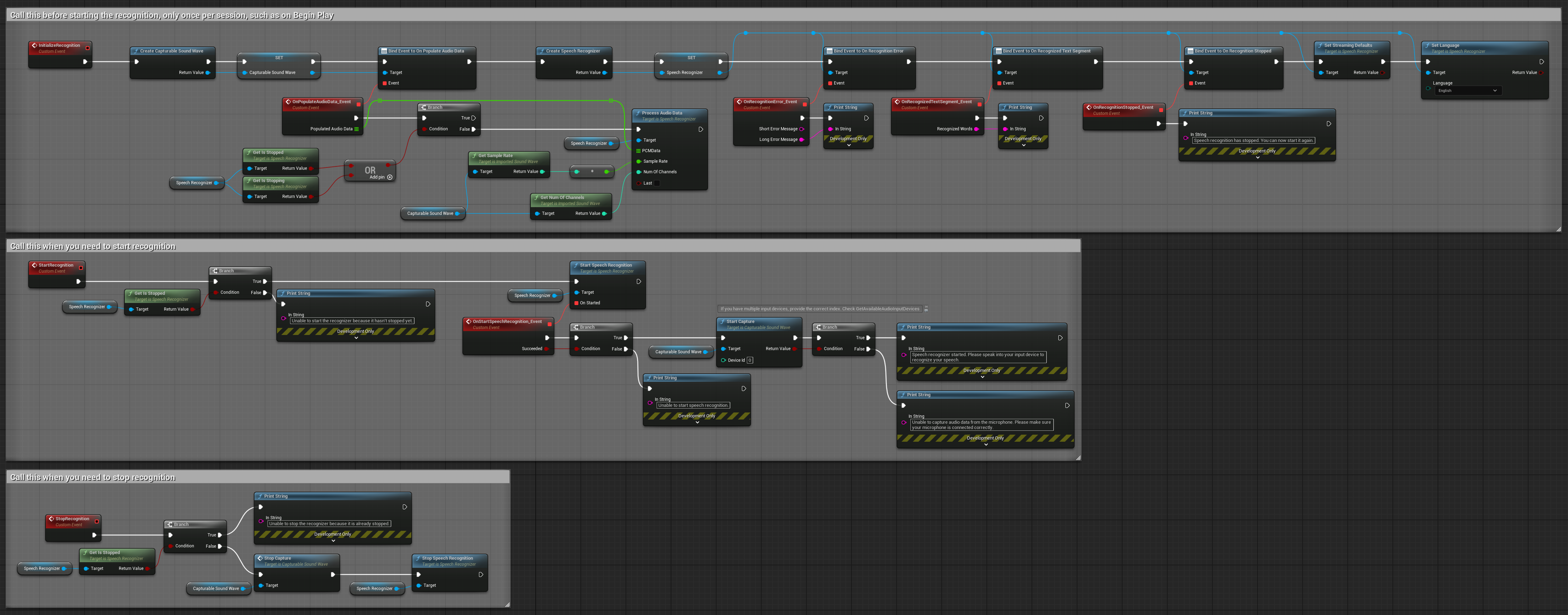
2. Controlled streaming recognition
This example extends the basic streaming setup by adding manual control over the recognition process. It allows you to start and stop the recognition at will, making it suitable for scenarios where you need precise control over when the recognition occurs. Copyable nodes.
Key features of this setup:
- Manual start/stop control
- Continuous recognition capability
- Flexible recording duration
- Suitable for interactive applications
3. Voice-activated command recognition
This example is optimized for command recognition scenarios. It combines streaming recognition with Voice Activity Detection (VAD) to automatically process speech when the user stops talking. The recognizer starts processing accumulated speech only when silence is detected, making it ideal for command-based interfaces. Copyable nodes.
Key features of this setup:
- Manual start/stop control
- Voice Activity Detection (VAD) enabled to detect speech segments
- Automatic recognition triggering when silence is detected
- Optimal for short command recognition
- Reduced processing overhead by only recognizing actual speech
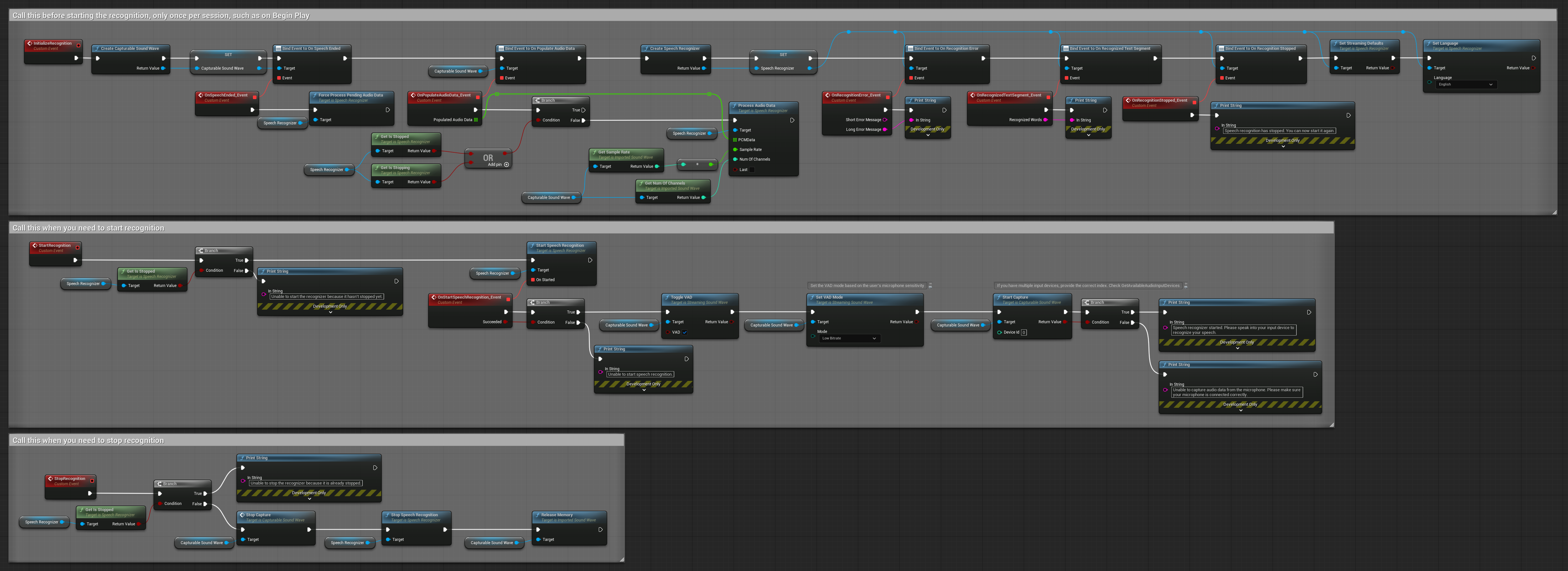
4. Auto-initializing voice recognition with final buffer processing
This example is another variation of the voice-activated recognition approach with different lifecycle handling. It automatically starts the recognizer during initialization and stops it during deinitialization. A key feature is that it processes the last accumulated audio buffer before stopping the recognizer, ensuring no speech data is lost when the user wants to end the recognition process. This setup is particularly useful for applications where you need to capture complete user utterances even when stopping mid-speech. Copyable nodes.
Key features of this setup:
- Auto-starts recognizer on initialization
- Auto-stops recognizer on deinitialization
- Processes final audio buffer before stopping completely
- Uses Voice Activity Detection (VAD) for efficient recognition
- Ensures no speech data is lost when stopping
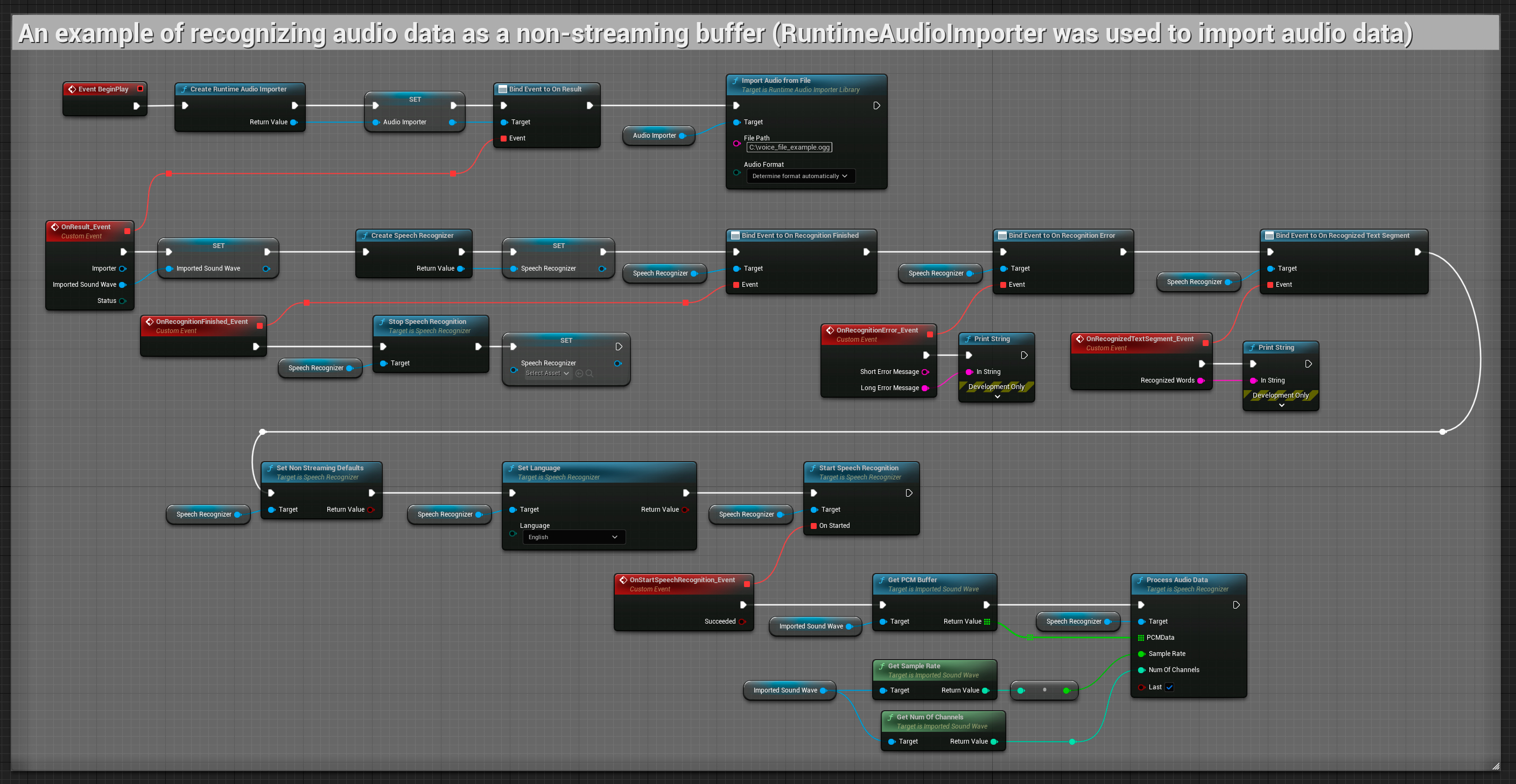
Non-streaming audio input
This example imports audio data to the Imported sound wave and recognizes the full audio data once it has been imported. Copyable nodes.