Comment utiliser le plugin
Le plugin Runtime Speech Recognizer est conçu pour reconnaître les mots à partir des données audio entrantes. Il utilise une version légèrement modifiée de whisper.cpp pour fonctionner avec le moteur. Pour utiliser le plugin, suivez ces étapes :
Côté éditeur
- Sélectionnez les modèles de langue appropriés pour votre projet comme décrit ici.
Côté runtime
- Créez un Speech Recognizer et définissez les paramètres nécessaires (CreateSpeechRecognizer, pour les paramètres voir ici).
- Liez-vous aux délégués nécessaires (OnRecognitionFinished, OnRecognizedTextSegment et OnRecognitionError).
- Démarrez la reconnaissance vocale (StartSpeechRecognition).
- Traitez les données audio et attendez les résultats des délégués (ProcessAudioData).
- Arrêtez le Speech Recognizer lorsque nécessaire (par exemple, après la diffusion de OnRecognitionFinished).
Le plugin prend en charge les données audio entrantes au format PCM entrelacé 32 bits en virgule flottante. Bien qu'il fonctionne bien avec le Runtime Audio Importer, il n'en dépend pas directement.
Paramètres de reconnaissance
Le plugin prend en charge la reconnaissance des données audio en streaming et non streaming. Pour ajuster les paramètres de reconnaissance selon votre cas d'utilisation spécifique, appelez SetStreamingDefaults ou SetNonStreamingDefaults. De plus, vous avez la flexibilité de définir manuellement des paramètres individuels tels que le nombre de threads, la taille du pas, s'il faut traduire la langue entrante en anglais, et s'il faut utiliser la transcription passée. Reportez-vous à la Liste des paramètres de reconnaissance pour une liste complète des paramètres disponibles.
Améliorer les performances
Veuillez vous référer à la section Comment améliorer les performances pour des conseils sur la façon d'optimiser les performances du plugin.
Détection d'activité vocale (VAD)
Lors du traitement de l'entrée audio, en particulier dans les scénarios de streaming, il est recommandé d'utiliser la Détection d'activité vocale (VAD) pour filtrer les segments audio vides ou contenant uniquement du bruit avant qu'ils n'atteignent le reconnaisseur. Ce filtrage peut être activé côté onde sonore capturable en utilisant le plugin Runtime Audio Importer, ce qui aide à empêcher les modèles de langue de faire des hallucinations - tenter de trouver des motifs dans le bruit et générer des transcriptions incorrectes.
Pour des résultats de reconnaissance vocale optimaux, nous recommandons d'utiliser le fournisseur Silero VAD qui offre une tolérance au bruit supérieure et une détection de la parole plus précise. Le Silero VAD est disponible en tant qu'extension du plugin Runtime Audio Importer. Pour des instructions détaillées sur la configuration de la VAD, reportez-vous à la documentation sur la Détection d'activité vocale.
Les nœuds copiables dans les exemples ci-dessous utilisent le fournisseur VAD par défaut pour des raisons de compatibilité. Pour améliorer la précision de la reconnaissance, vous pouvez facilement passer à Silero VAD en :
- Installant l'extension Silero VAD comme décrit dans la section Extension Silero VAD
- Après avoir activé le VAD avec le nœud Toggle VAD, ajoutez un nœud Set VAD Provider et sélectionnez "Silero" dans le menu déroulant
Dans le projet de démonstration inclus avec le plugin, le VAD est activé par défaut. Vous pouvez trouver plus d'informations sur l'implémentation de la démo à Projet de démonstration.
Exemples
Ces exemples illustrent comment utiliser le plugin Runtime Speech Recognizer avec une entrée audio en streaming et non-streaming, en utilisant le Runtime Audio Importer pour obtenir des données audio à titre d'exemple. Veuillez noter qu'un téléchargement séparé du RuntimeAudioImporter est nécessaire pour accéder au même ensemble de fonctionnalités d'importation audio présentées dans les exemples (par exemple, l'onde sonore capturable et ImportAudioFromFile). Ces exemples sont uniquement destinés à illustrer le concept de base et n'incluent pas la gestion des erreurs.
Exemples d'entrée audio en streaming
Note : Dans UE 5.3 et d'autres versions, vous pourriez rencontrer des nœuds manquants après avoir copié des Blueprints. Cela peut se produire en raison de différences dans la sérialisation des nœuds entre les versions du moteur. Vérifiez toujours que tous les nœuds sont correctement connectés dans votre implémentation.
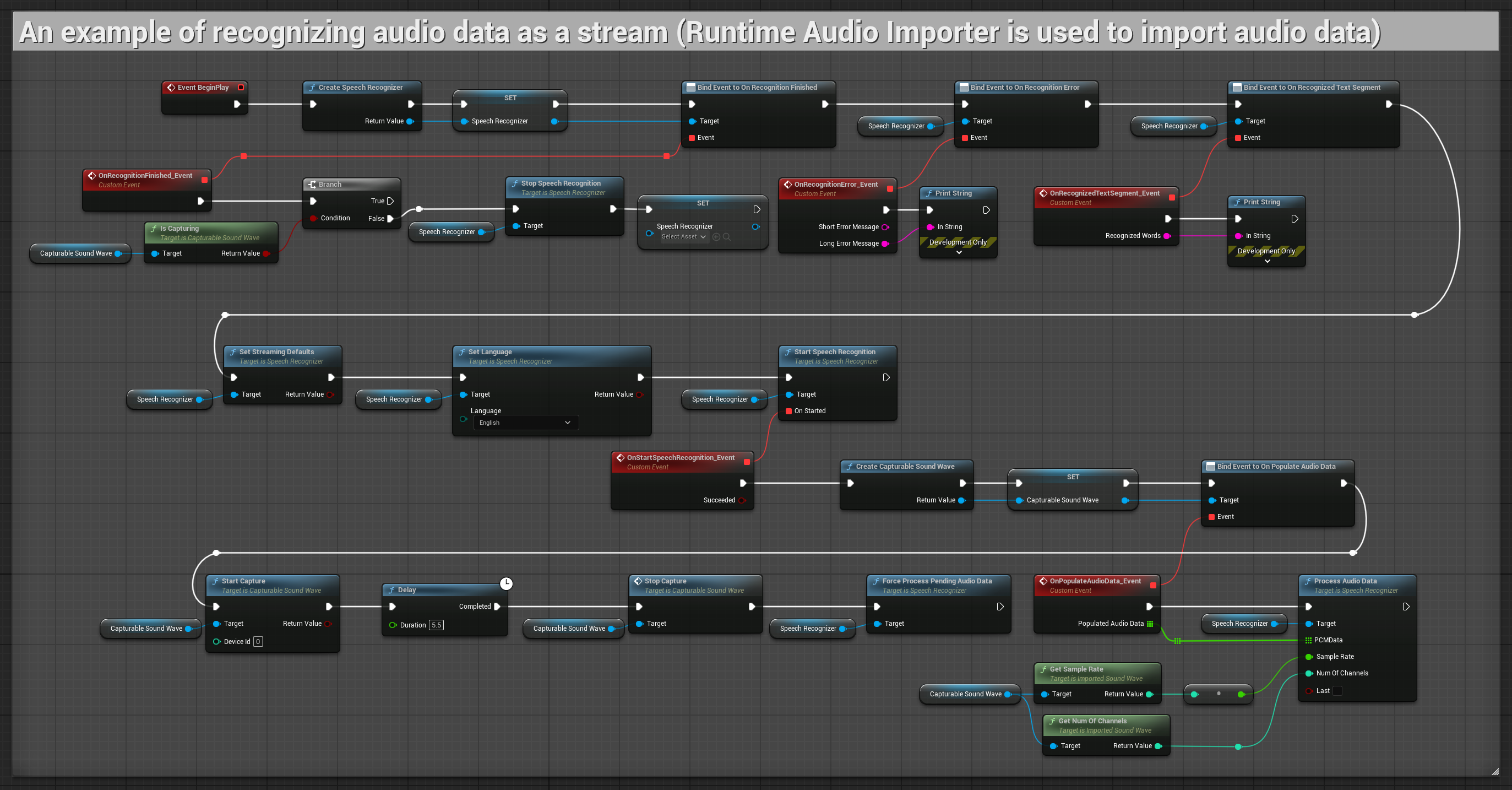
1. Reconnaissance en streaming de base
Cet exemple démontre la configuration de base pour capturer les données audio du microphone sous forme de flux en utilisant l'onde sonore capturable et les transmettre au module de reconnaissance vocale. Il enregistre la parole pendant environ 5 secondes puis traite la reconnaissance, ce qui le rend adapté pour des tests rapides et des implémentations simples. Nœuds copiables.
Caractéristiques clés de cette configuration :
- Durée d'enregistrement fixe de 5 secondes
- Reconnaissance simple en une fois
- Configuration minimale requise
- Parfait pour les tests et le prototypage
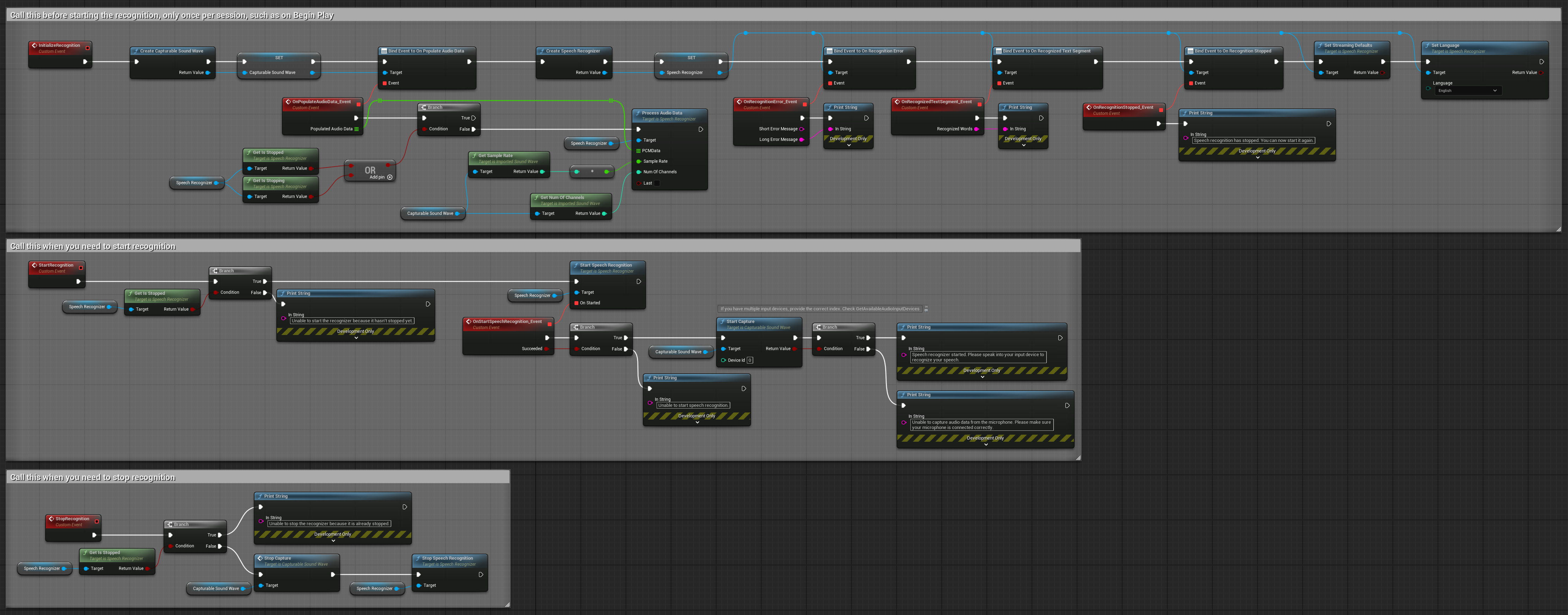
2. Reconnaissance en streaming contrôlée
Cet exemple étend la configuration de streaming de base en ajoutant un contrôle manuel du processus de reconnaissance. Il vous permet de démarrer et d'arrêter la reconnaissance à volonté, ce qui le rend adapté aux scénarios où vous avez besoin d'un contrôle précis du moment où la reconnaissance se produit. Nœuds copiables.
Caractéristiques clés de cette configuration :
- Contrôle manuel de démarrage/arrêt
- Capacité de reconnaissance continue
- Durée d'enregistrement flexible
- Adapté aux applications interactives
3. Reconnaissance de commande activée par la voix
Cet exemple est optimisé pour les scénarios de reconnaissance de commande. Il combine la reconnaissance en streaming avec la Détection d'Activité Vocale (VAD) pour traiter automatiquement la parole lorsque l'utilisateur arrête de parler. Le reconnaisseur commence à traiter la parole accumulée uniquement lorsqu'un silence est détecté, ce qui le rend idéal pour les interfaces basées sur des commandes. Nœuds copiables.
Caractéristiques clés de cette configuration :
- Contrôle manuel de démarrage/arrêt
- Détection d'Activité Vocale (VAD) activée pour détecter les segments de parole
- Déclenchement automatique de la reconnaissance lors de la détection d'un silence
- Optimal pour la reconnaissance de commandes courtes
- Surcharge de traitement réduite en ne reconnaissant que la parole réelle
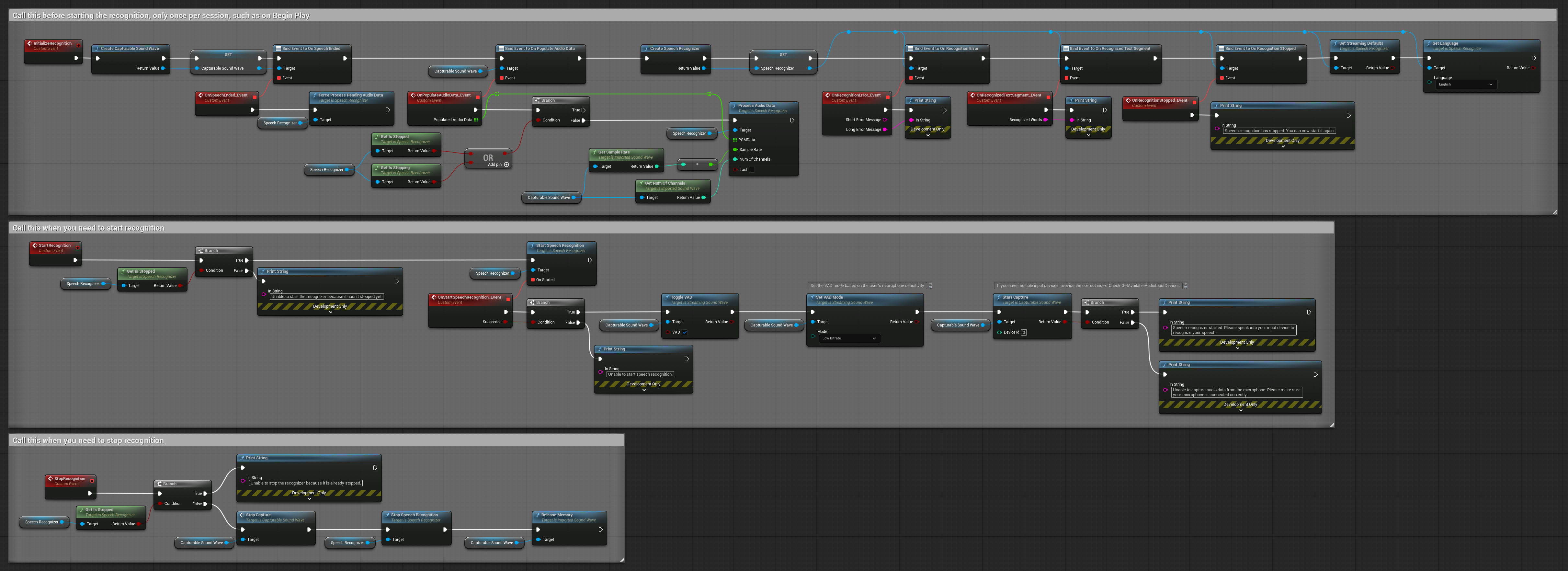
4. Reconnaissance vocale à initialisation automatique avec traitement du tampon final
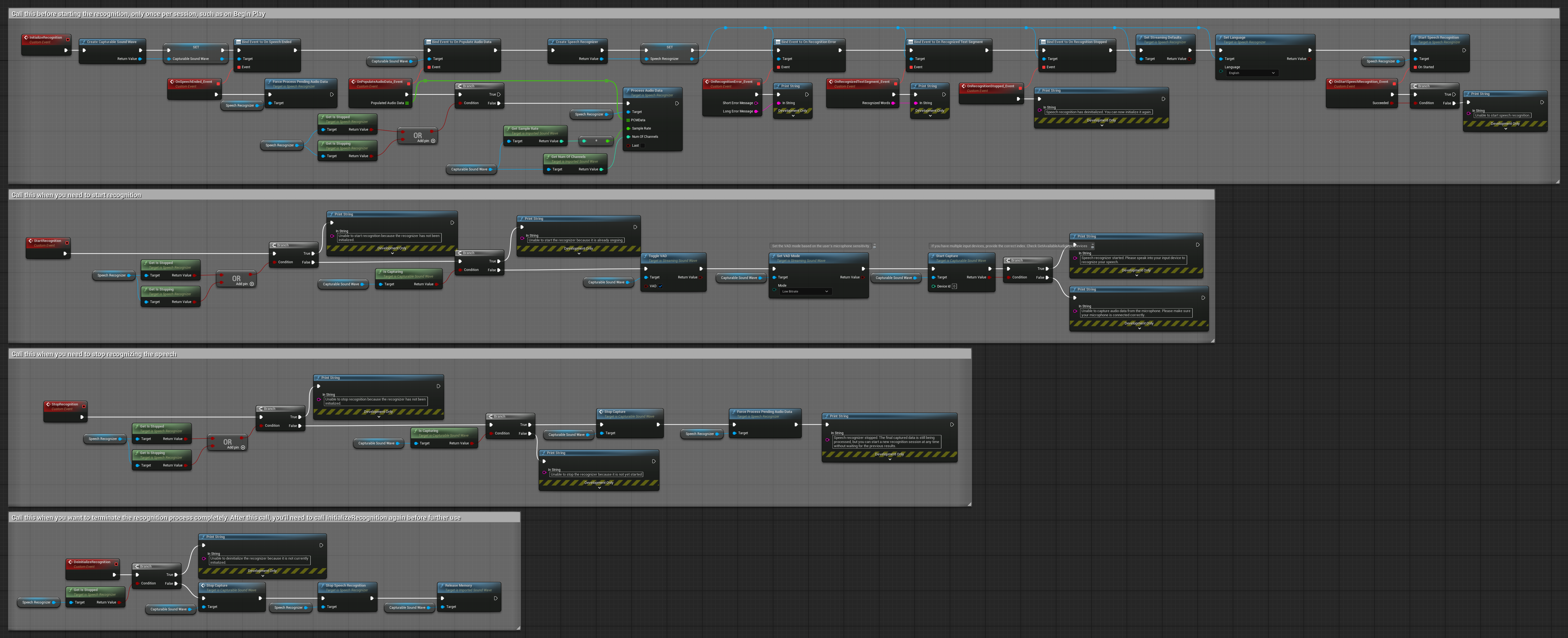
Cet exemple est une autre variante de l'approche de reconnaissance activée par la voix avec une gestion différente du cycle de vie. Il démarre automatiquement le reconnaisseur lors de l'initialisation et l'arrête lors de la désinitialisation. Une caractéristique clé est qu'il traite le dernier tampon audio accumulé avant d'arrêter le reconnaisseur, garantissant qu'aucune donnée vocale n'est perdue lorsque l'utilisateur souhaite mettre fin au processus de reconnaissance. Cette configuration est particulièrement utile pour les applications où vous devez capturer des énoncés utilisateur complets, même lors d'un arrêt en cours de parole. Nœuds copiables.
Caractéristiques clés de cette configuration :
- Démarre automatiquement le reconnaisseur à l'initialisation
- Arrête automatiquement le reconnaisseur à la désinitialisation
- Traite le tampon audio final avant l'arrêt complet
- Utilise la Détection d'Activité Vocale (VAD) pour une reconnaissance efficace
- Garantit qu'aucune donnée vocale n'est perdue à l'arrêt
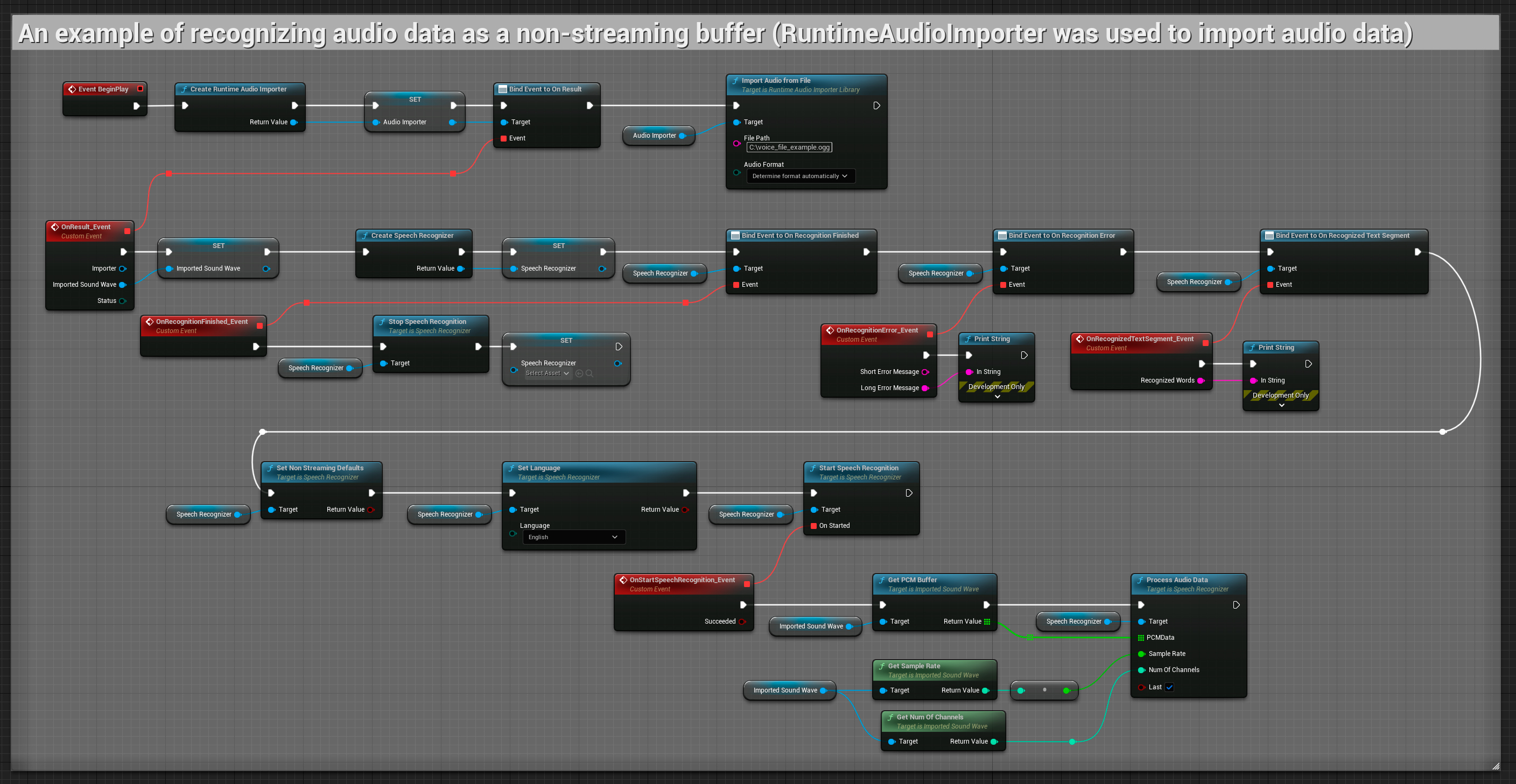
Entrée audio non-streaming
Cet exemple importe des données audio vers l'Onde sonore importée et reconnaît l'intégralité des données audio une fois qu'elles ont été importées. Nœuds copiables.