Как использовать плагин
Плагин Runtime Speech Recognizer предназначен для распознавания слов из входящих аудиоданных. Он использует слегка модифицированную версию whisper.cpp для работы с движком. Чтобы использовать плагин, выполните следующие шаги:
Со стороны редактора
- Выберите подходящие языковые модели для вашего проекта, как описано здесь.
Со стороны рантайма
- Создайте Speech Recognizer и установите необходимые параметры (CreateSpeechRecognizer, параметры см. здесь).
- Привяжитесь к нужным делегатам (OnRecognitionFinished, OnRecognizedTextSegment и OnRecognitionError).
- Запустите распознавание речи (StartSpeechRecognition).
- Обрабатывайте аудиоданные и ожидайте результатов от делегатов (ProcessAudioData).
- Остановите распознаватель речи, когда это необходимо (например, после трансляции OnRecognitionFinished).
Плагин поддерживает входящее аудио в формате floating point 32-bit interleaved PCM. Хотя он хорошо работает с Runtime Audio Importer, он не зависит от него напрямую.
Параметры распознавания
Плагин поддерживает распознавание как потоковых, так и непотоковых аудиоданных. Чтобы настроить параметры распознавания под ваш конкретный случай использования, вызовите SetStreamingDefaults или SetNonStreamingDefaults. Дополнительно у вас есть гибкость для ручной установки отдельных параметров, таких как количество потоков, размер шага, нужно ли переводить входящий язык на английский и использовать ли предыдущую транскрипцию. Обратитесь к Списку параметров распознавания для полного перечня доступных параметров.
Повышение производительности
Пожалуйста, обратитесь к разделу Как повысить производительность для получения советов по оптимизации производительности плагина.
Детекция голосовой активности (VAD)
При обработке аудиовхода, особенно в потоковых сценариях, рекомендуется использовать Детекцию голосовой активности (VAD) для фильтрации пустых или содержащих только шум сегментов аудио до того, как они достигнут распознавателя. Эта фильтрация может быть включена на стороне захватываемой звуковой волны с использованием плагина Runtime Audio Importer, что помогает предотвратить галлюцинации языковых моделей — попытки найти паттерны в шуме и генерацию некорректных транскрипций.
Для оптимальных результатов распознавания речи мы рекомендуем использовать провайдер Silero VAD, который предлагает превосходную устойчивость к шуму и более точное обнаружение речи. Silero VAD доступен как расширение для плагина Runtime Audio Importer. Подробные инструкции по настройке VAD смотрите в документации по детекции голосовой активности.
Копируемые узлы в примерах ниже используют провайдер VAD по умолчанию для совместимости. Чтобы повысить точность распознавания, вы можете легко переключиться на Silero VAD, выполнив следующие действия:
- Установите расширение Silero VAD, как описано в разделе Расширение Silero VAD
- После включения VAD с помощью узла Toggle VAD, добавьте узел Set VAD Provider и выберите "Silero" из выпадающего списка
В демо-проекте, включенном в плагин, VAD включен по умолчанию. Подробнее о реализации демо-проекта можно узнать в разделе Демо-проект.
Примеры
Эти примеры иллюстрируют, как использовать плагин Runtime Speech Recognizer как с потоковым, так и с непотоковым аудиовходом, используя Runtime Audio Importer для получения аудиоданных в качестве примера. Обратите внимание, что для доступа к тому же набору функций импорта аудио, показанных в примерах (например, захватываемая звуковая волна и ImportAudioFromFile), требуется отдельная загрузка RuntimeAudioImporter. Эти примеры предназначены исключительно для иллюстрации основной концепции и не включают обработку ошибок.
Примеры потокового аудиовхода
Примечание: В UE 5.3 и других версиях вы можете столкнуться с отсутствующими узлами после копирования Blueprints. Это может произойти из-за различий в сериализации узлов между версиями движка. Всегда проверяйте, что все узлы правильно подключены в вашей реализации.
1. Базовое потоковое распознавание
Этот пример демонстрирует базовую настройку для захвата аудиоданных с микрофона в виде потока с использованием Capturable sound wave и передачи их в распознаватель речи. Он записывает речь в течение примерно 5 секунд, а затем обрабатывает распознавание, что делает его подходящим для быстрых тестов и простых реализаций. Копируемые узлы.
Ключевые особенности этой настройки:
- Фиксированная длительность записи 5 секунд
- Простое одноразовое распознавание
- Минимальные требования к настройке
- Идеально подходит для тестирования и прототипирования
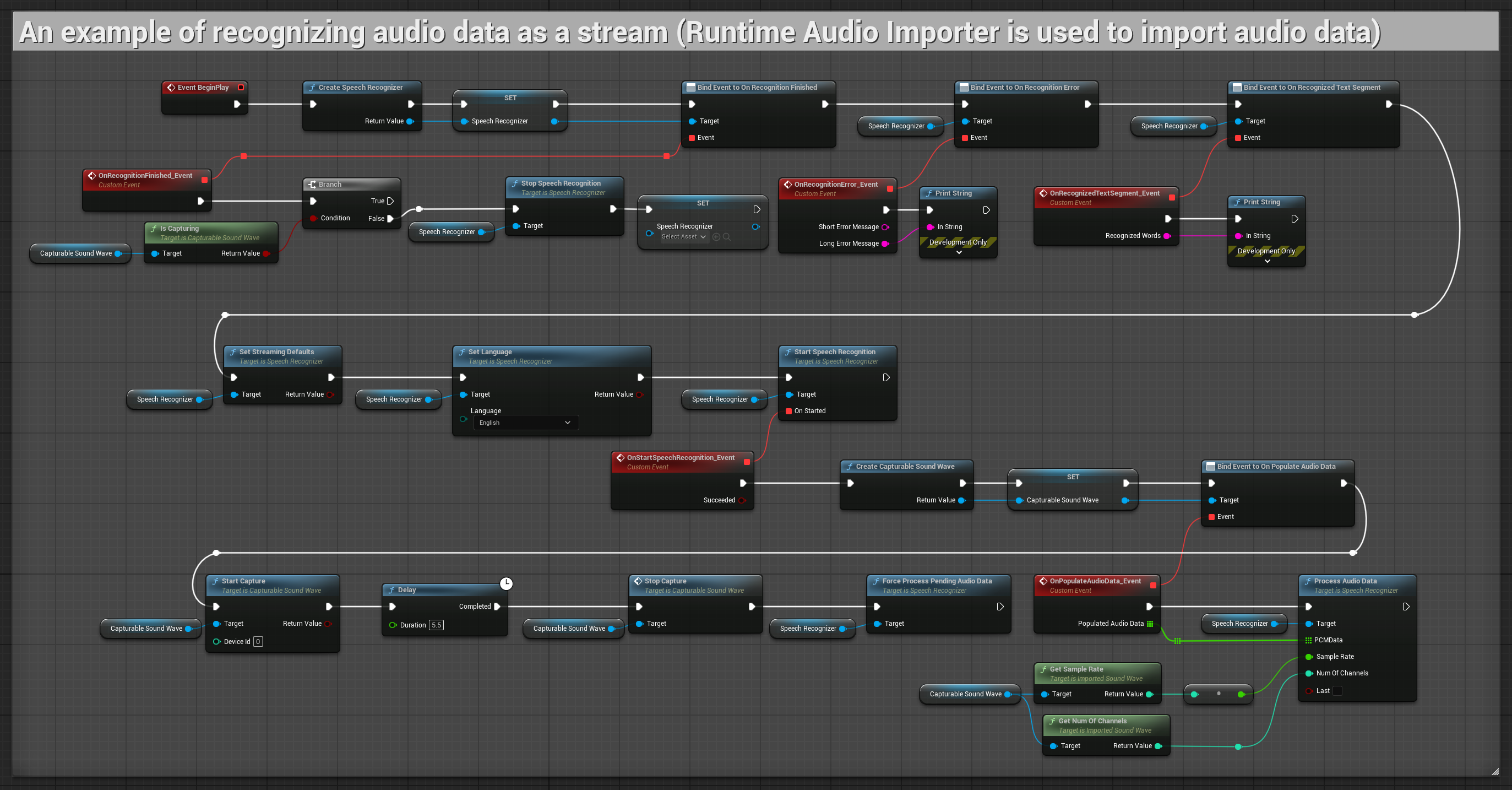
2. Управляемое потоковое распознавание
Этот пример расширяет базовую потоковую настройку, добавляя ручное управление процессом распознавания. Он позволяет запускать и останавливать распознавание по желанию, что делает его подходящим для сценариев, где требуется точный контроль над моментом распознавания. Копируемые узлы.
Ключевые особенности этой настройки:
- Ручное управление запуском/остановкой
- Возможность непрерывного распознавания
- Гибкая продолжительность записи
- Подходит для интерактивных приложений
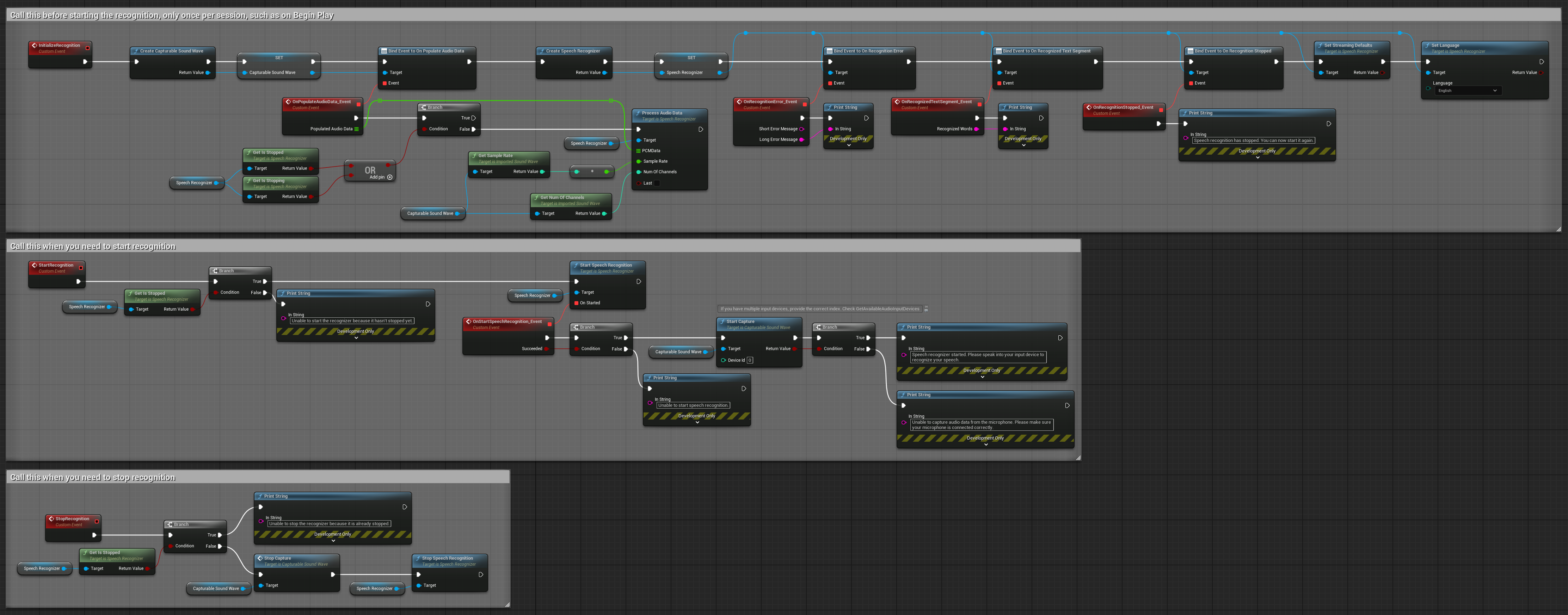
3. Распознавание голосовых команд по активации
Этот пример оптимизирован для сценариев распознавания команд. Он сочетает потоковое распознавание с Детектированием речевой активности (VAD) для автоматической обработки речи, когда пользователь перестает говорить. Распознаватель начинает обрабатывать накопленную речь только при обнаружении тишины, что делает его идеальным для интерфейсов на основе команд. Копируемые ноды.
Ключевые особенности этой настройки:
- Ручное управление запуском/остановкой
- Включено Детектирование речевой активности (VAD) для обнаружения сегментов речи
- Автоматический запуск распознавания при обнаружении тишины
- Оптимально для распознавания коротких команд
- Сниженная вычислительная нагрузка за счёт распознавания только реальной речи
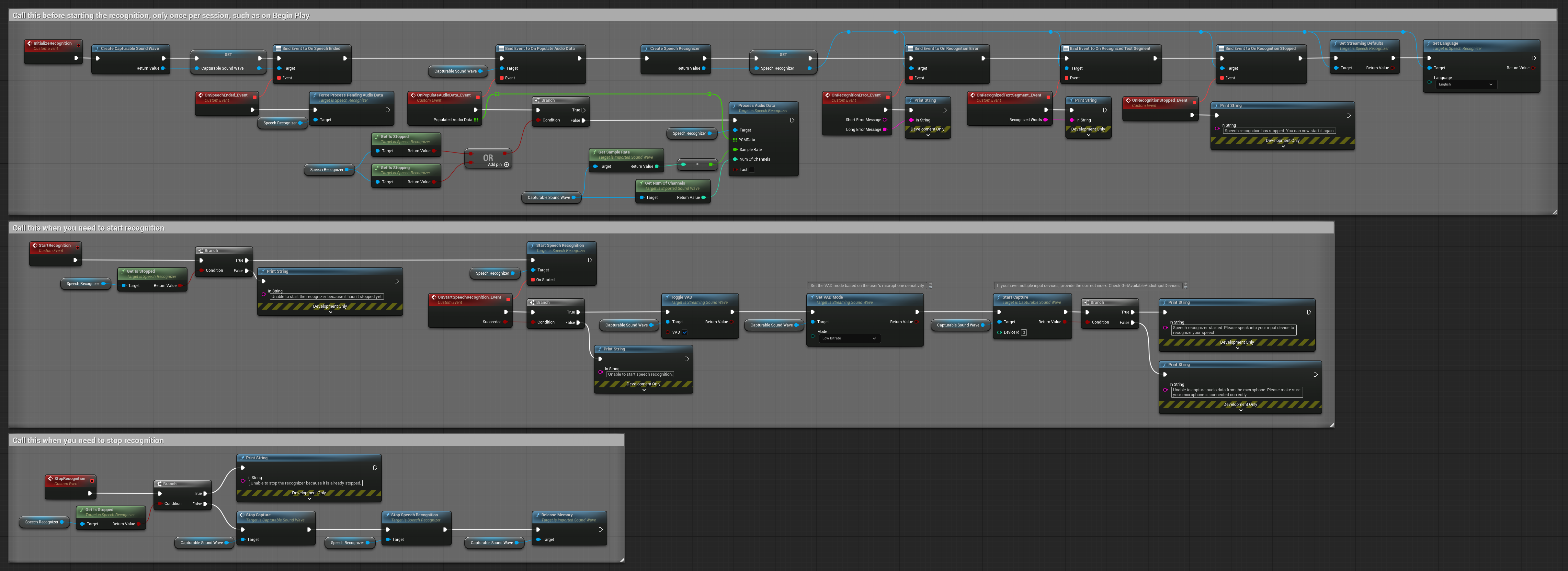
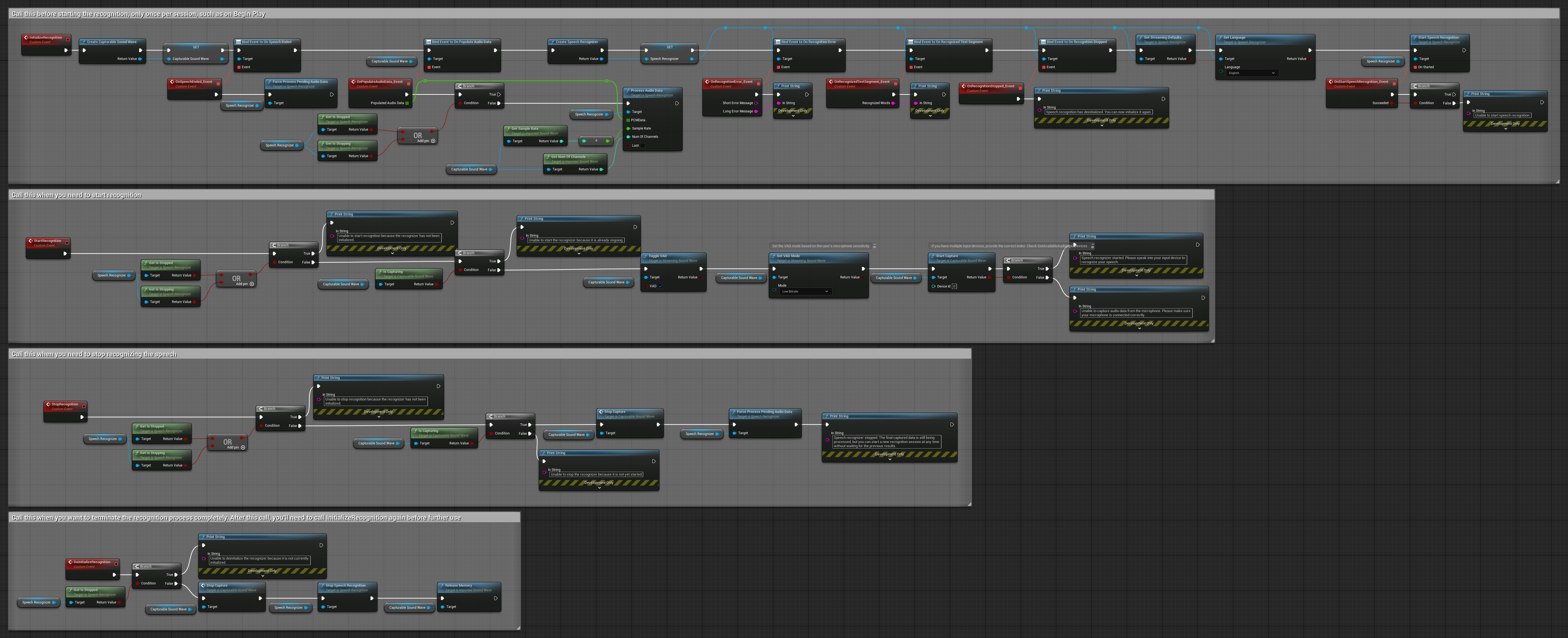
4. Автоинициализирующееся голосовое распознавание с обработкой финального буфера
Этот пример представляет собой ещё одну вариацию подхода к распознаванию по голосовой активации с другим управлением жизненным циклом. Он автоматически запускает распознаватель при инициализации и останавливает его при деинициализации. Ключевая особенность заключается в том, что он обрабатывает последний накопленный аудиобуфер перед остановкой распознавателя, гарантируя, что никакие речевые данные не будут потеряны, когда пользователь хочет завершить процесс распознавания. Эта настройка особенно полезна для приложений, где необходимо захватывать полные высказывания пользователя, даже при остановке в середине речи. Копируемые ноды.
Ключевые особенности этой настройки:
- Автоматически запускает распознаватель при инициализации
- Автоматически останавливает распознаватель при деинициализации
- Обрабатывает финальный аудиобуфер перед полной остановкой
- Использует Детектирование речевой активности (VAD) для эффективного распознавания
- Гарантирует, что речевые данные не теряются при остановке
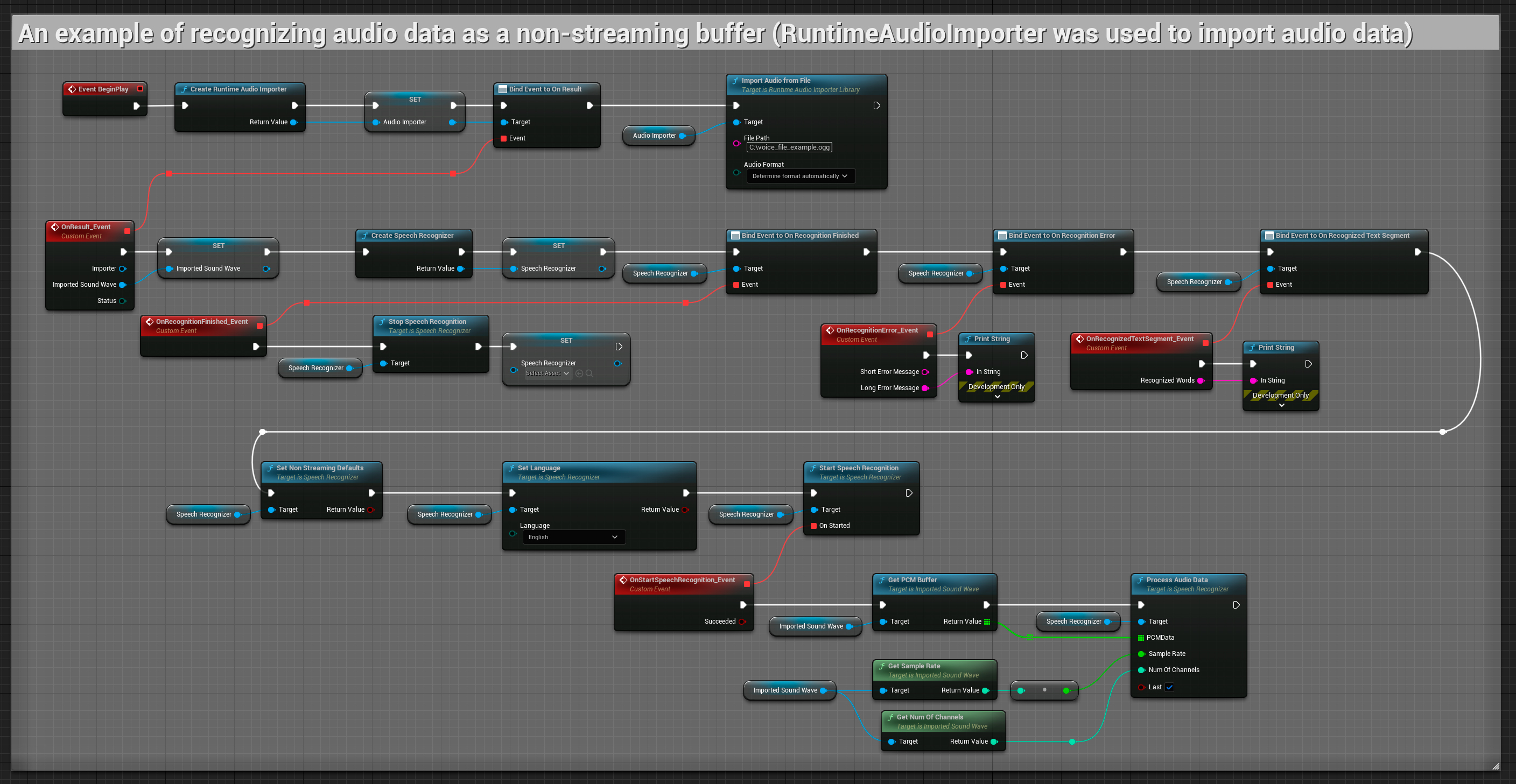
Непотоковый аудиоввод
Этот пример импортирует аудиоданные в Imported sound wave и распознаёт полные аудиоданные после их импорта. Копируемые ноды.