So verwenden Sie das Plugin
Das Runtime Speech Recognizer Plugin ist dafür ausgelegt, Wörter aus eingehenden Audiodaten zu erkennen. Es verwendet eine leicht modifizierte Version von whisper.cpp, um mit der Engine zu arbeiten. Um das Plugin zu verwenden, folgen Sie diesen Schritten:
Editor-Seite
- Wählen Sie die entsprechenden Sprachmodelle für Ihr Projekt aus, wie hier beschrieben.
Laufzeit-Seite
- Erstellen Sie einen Speech Recognizer und setzen Sie die notwendigen Parameter (CreateSpeechRecognizer, für Parameter siehe hier).
- Binden Sie die benötigten Delegaten (OnRecognitionFinished, OnRecognizedTextSegment und OnRecognitionError).
- Starten Sie die Spracherkennung (StartSpeechRecognition).
- Verarbeiten Sie Audiodaten und warten Sie auf Ergebnisse von den Delegaten (ProcessAudioData).
- Stoppen Sie den Speech Recognizer bei Bedarf (z.B. nach der OnRecognitionFinished-Übertragung).
Das Plugin unterstützt eingehendes Audio im Floating-Point-32-Bit-Interleaved-PCM-Format. Während es gut mit dem Runtime Audio Importer funktioniert, ist es nicht direkt davon abhängig.
Erkennungsparameter
Das Plugin unterstützt die Erkennung von Streaming- und Nicht-Streaming-Audiodaten. Um die Erkennungsparameter für Ihren spezifischen Anwendungsfall anzupassen, rufen Sie SetStreamingDefaults oder SetNonStreamingDefaults auf. Zusätzlich haben Sie die Flexibilität, individuelle Parameter manuell zu setzen, wie die Anzahl der Threads, die Schrittgröße, ob die eingehende Sprache ins Englische übersetzt werden soll und ob vergangene Transkription verwendet werden soll. Weitere Informationen finden Sie in der Liste der Erkennungsparameter für eine vollständige Liste der verfügbaren Parameter.
Leistungsverbesserung
Bitte lesen Sie den Abschnitt Wie Sie die Leistung verbessern können für Tipps zur Optimierung der Plugin-Leistung.
Voice Activity Detection (VAD)
Bei der Verarbeitung von Audioeingängen, insbesondere in Streaming-Szenarien, wird empfohlen, Voice Activity Detection (VAD) zu verwenden, um leere oder nur Rauschen enthaltende Audiosegmente herauszufiltern, bevor sie den Recognizer erreichen. Diese Filterung kann auf der Seite der aufnehmbaren Schallwelle mit dem Runtime Audio Importer Plugin aktiviert werden, was verhindert, dass die Sprachmodelle halluzinieren – also versuchen, Muster im Rauschen zu finden und falsche Transkriptionen zu erzeugen.
Für optimale Spracherkennungsergebnisse empfehlen wir die Verwendung des Silero VAD-Providers, der eine überlegene Rauschunterdrückung und genauere Spracherkennung bietet. Der Silero VAD ist als Erweiterung des Runtime Audio Importer Plugins verfügbar. Detaillierte Anweisungen zur VAD-Konfiguration finden Sie in der Voice Activity Detection-Dokumentation.
Die kopierbaren Nodes in den folgenden Beispielen verwenden aus Kompatibilitätsgründen den standardmäßigen VAD-Provider. Um die Erkennungsgenauigkeit zu verbessern, können Sie problemlos auf Silero VAD umschalten, indem Sie:
- Die Silero VAD-Erweiterung wie im Abschnitt Silero VAD-Erweiterung beschrieben installieren
- Nach dem Aktivieren von VAD mit dem Toggle VAD-Node einen Set VAD Provider-Node hinzufügen und "Silero" aus dem Dropdown-Menü auswählen
Im Demo-Projekt, das im Plugin enthalten ist, ist VAD standardmäßig aktiviert. Weitere Informationen zur Demo-Implementierung finden Sie unter Demo-Projekt.
Beispiele
Diese Beispiele veranschaulichen die Verwendung des Runtime Speech Recognizer-Plugins mit sowohl Streaming- als auch Nicht-Streaming-Audioeingabe, wobei der Runtime Audio Importer als Beispiel zur Beschaffung von Audiodaten dient. Bitte beachten Sie, dass für den Zugriff auf denselben Satz von Audioimport-Funktionen, die in den Beispielen gezeigt werden (z.B. capturable sound wave und ImportAudioFromFile), ein separates Herunterladen des RuntimeAudioImporter erforderlich ist. Diese Beispiele dienen ausschließlich der Veranschaulichung des Kernkonzepts und enthalten keine Fehlerbehandlung.
Beispiele für Streaming-Audioeingabe
Hinweis: In UE 5.3 und anderen Versionen könnten Ihnen fehlende Nodes nach dem Kopieren von Blueprints begegnen. Dies kann aufgrund von Unterschieden in der Node-Serialisierung zwischen Engine-Versionen auftreten. Überprüfen Sie stets, ob alle Nodes in Ihrer Implementierung korrekt verbunden sind.
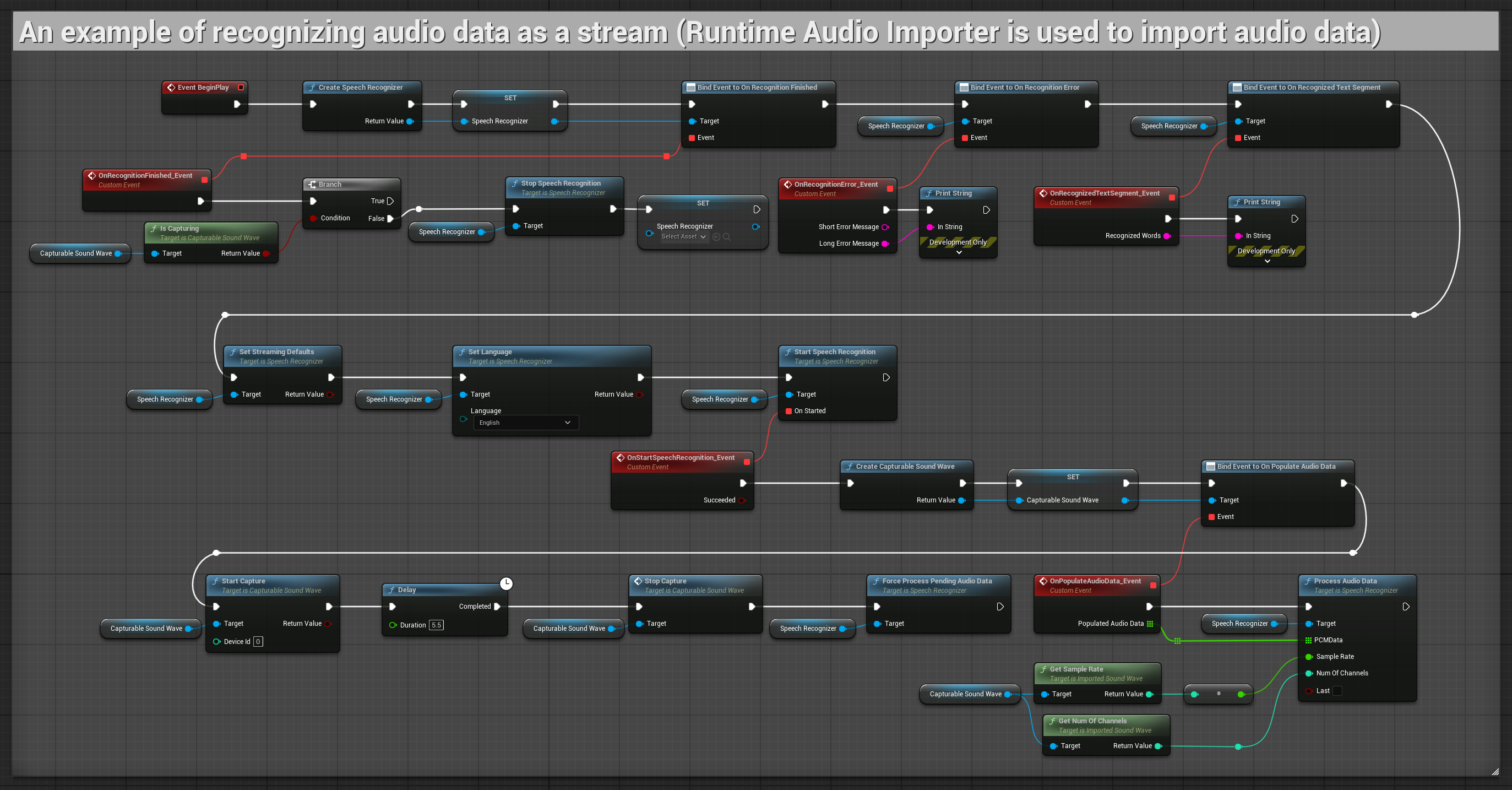
1. Grundlegende Streaming-Erkennung
Dieses Beispiel demonstriert den grundlegenden Aufbau zur Erfassung von Audiodaten vom Mikrofon als Stream unter Verwendung der Capturable sound wave und deren Übergabe an die Spracherkennung. Es zeichnet Sprache für etwa 5 Sekunden auf und verarbeitet dann die Erkennung, was es für schnelle Tests und einfache Implementierungen geeignet macht. Kopierbare Nodes.
Wesentliche Merkmale dieses Aufbaus:
- Feste Aufnahmedauer von 5 Sekunden
- Einfache One-Shot-Erkennung
- Minimale Einrichtungsanforderungen
- Ideal für Tests und Prototyping
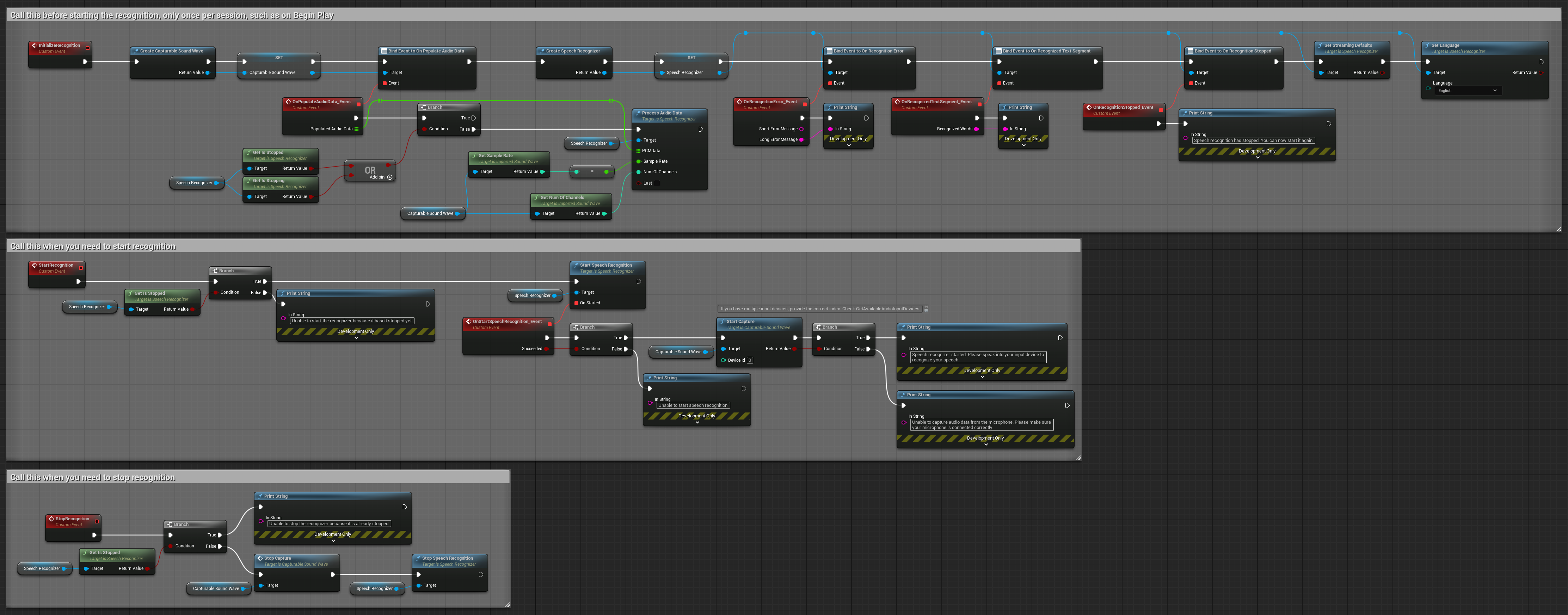
2. Gestuerte Streaming-Erkennung
Dieses Beispiel erweitert den grundlegenden Streaming-Aufbau durch Hinzufügen manueller Steuerung über den Erkennungsprozess. Es ermöglicht Ihnen, die Erkennung nach Belieben zu starten und zu stoppen, was es für Szenarien geeignet macht, in denen Sie präzise Kontrolle darüber benötigen, wann die Erkennung stattfindet. Kopierbare Nodes.
Wesentliche Merkmale dieses Aufbaus:
- Manuelle Start-/Stopp-Steuerung
- Kontinuierliche Erkennungsfähigkeit
- Flexible Aufnahmedauer
- Geeignet für interaktive Anwendungen
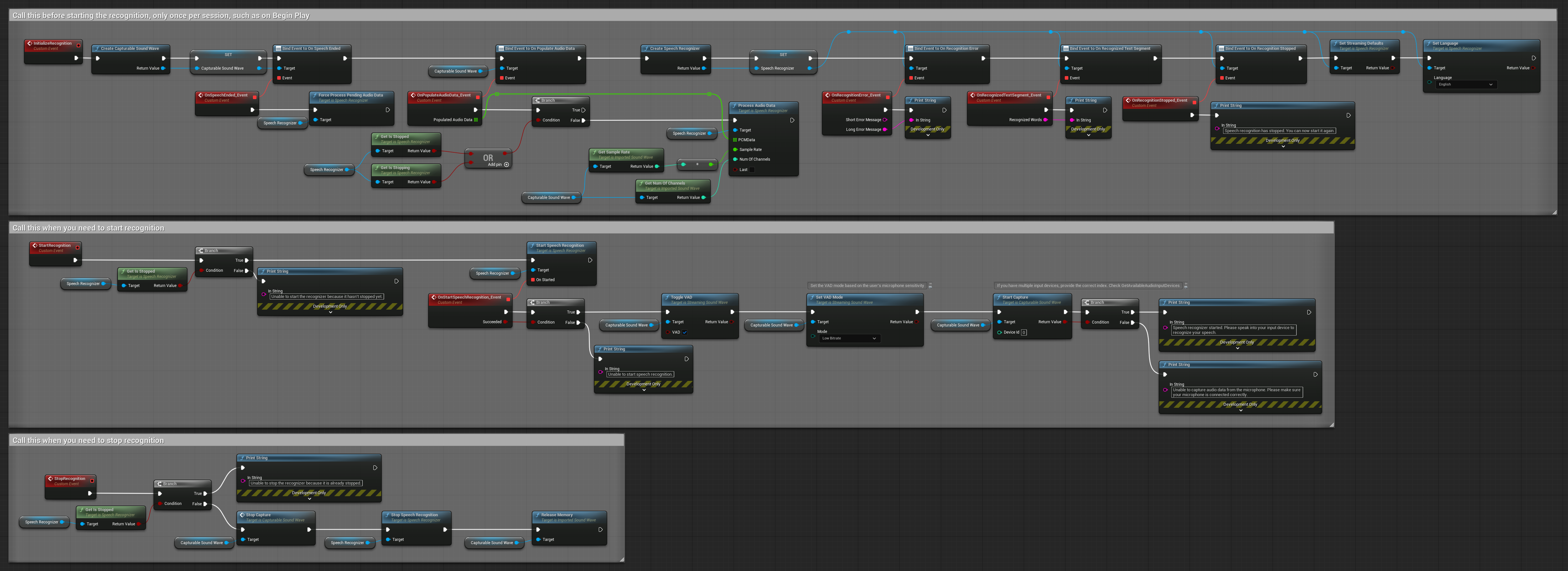
3. Sprachaktivierte Befehlserkennung
Dieses Beispiel ist für Befehlserkennungsszenarien optimiert. Es kombiniert Streaming-Erkennung mit Sprachaktivitätserkennung (VAD), um Sprache automatisch zu verarbeiten, wenn der Benutzer aufhört zu sprechen. Der Erkennungsprozess startet nur, wenn Stille erkannt wird, was es ideal für befehlsbasierte Schnittstellen macht. Kopierbare Nodes.
Hauptmerkmale dieses Setups:
- Manuelle Start-/Stopp-Steuerung
- Sprachaktivitätserkennung (VAD) aktiviert zur Erkennung von Sprachsegmenten
- Automatische Erkennungsauslösung bei Stilleerkennung
- Optimal für kurze Befehlserkennung
- Reduzierte Verarbeitungslast durch ausschließliche Erkennung tatsächlicher Sprache
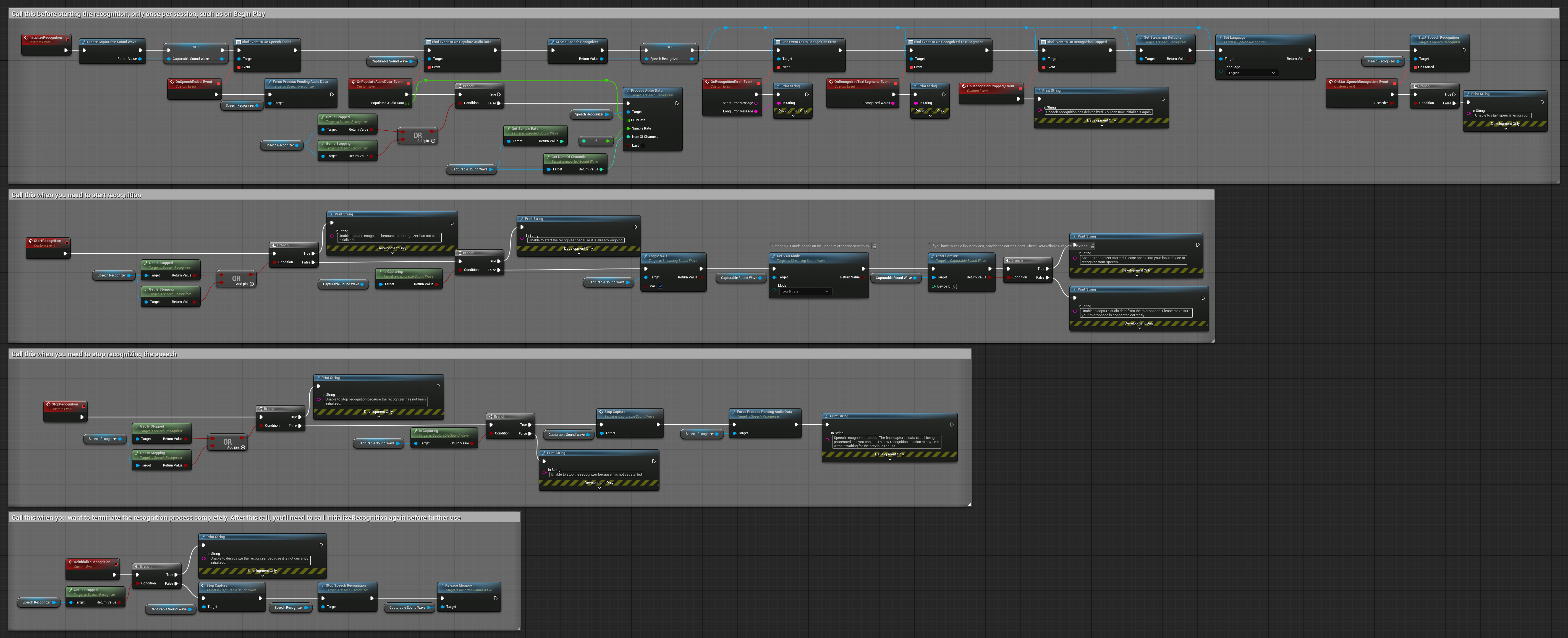
4. Auto-initialisierende Spracherkennung mit Endpuffer-Verarbeitung
Dieses Beispiel ist eine weitere Variante des sprachaktivierten Erkennungsansatzes mit unterschiedlicher Lebenszyklusbehandlung. Es startet den Erkennungsprozess automatisch während der Initialisierung und stoppt ihn während der Deinitialisierung. Ein Hauptmerkmal ist die Verarbeitung des letzten akkumulierten Audiopuffers vor dem Stoppen des Erkennungsprozesses, um sicherzustellen, dass keine Sprachdaten verloren gehen, wenn der Benutzer den Erkennungsprozess beenden möchte. Dieses Setup ist besonders nützlich für Anwendungen, in denen vollständige Benutzeräußerungen erfasst werden müssen, selbst wenn mitten in der Sprache gestoppt wird. Kopierbare Nodes.
Hauptmerkmale dieses Setups:
- Auto-Start des Erkennungsprozesses bei Initialisierung
- Auto-Stopp des Erkennungsprozesses bei Deinitialisierung
- Verarbeitung des finalen Audiopuffers vor vollständigem Stopp
- Verwendet Sprachaktivitätserkennung (VAD) für effiziente Erkennung
- Stellt sicher, dass keine Sprachdaten beim Stoppen verloren gehen
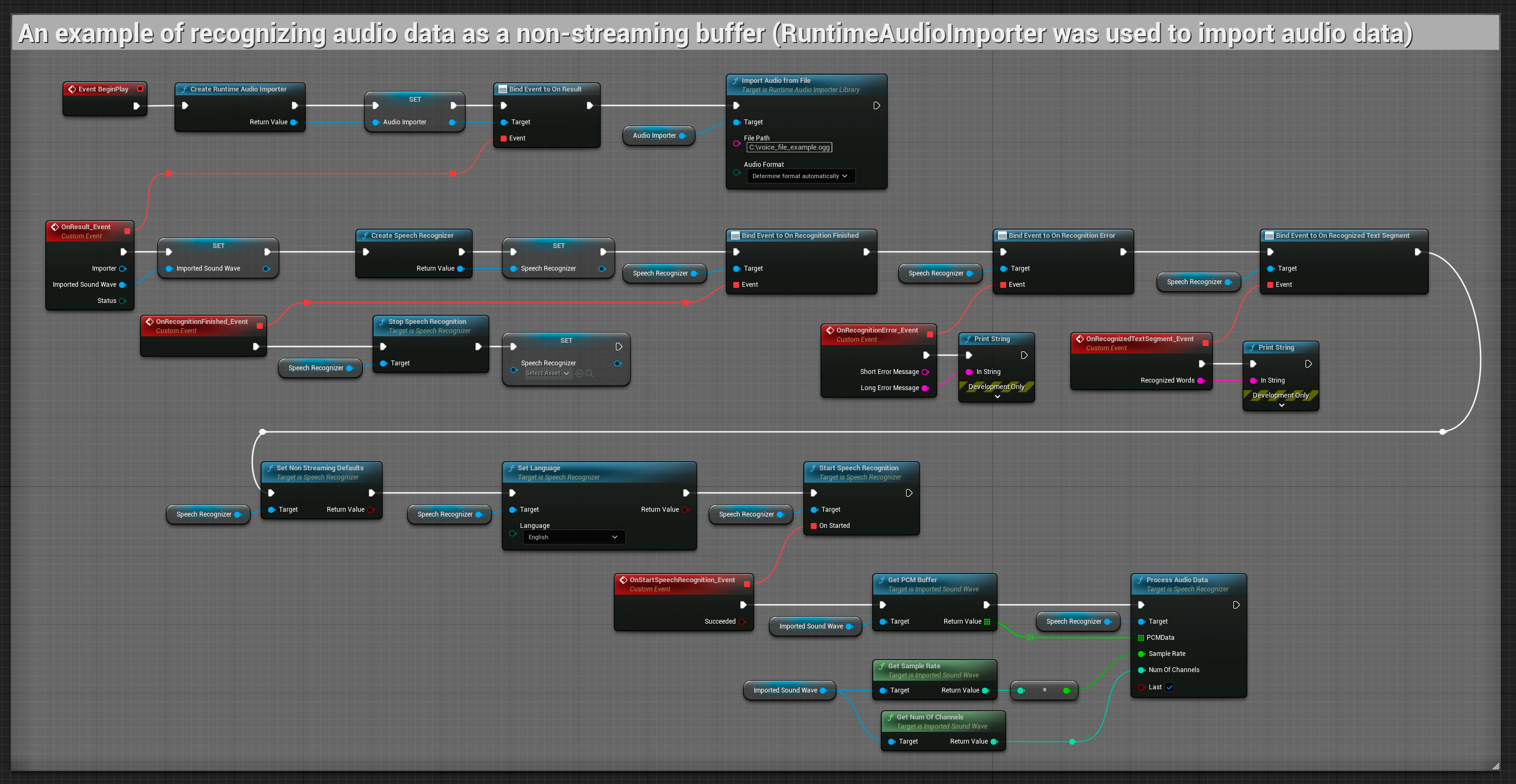
Nicht-Streaming Audioeingabe
Dieses Beispiel importiert Audiodaten in den Importierten Sound Wave und erkennt die vollständigen Audiodaten einmalig nach dem Import. Kopierbare Nodes.