플러그인 사용 방법
Runtime Speech Recognizer 플러그인은 들어오는 오디오 데이터에서 단어를 인식하도록 설계되었습니다. 엔진과 함께 작동하기 위해 약간 수정된 whisper.cpp 버전을 사용합니다. 플러그인을 사용하려면 다음 단계를 따르세요:
에디터 측
- 여기에 설명된 대로 프로젝트에 적합한 언어 모델을 선택하세요.
런타임 측
- Speech Recognizer를 생성하고 필요한 매개변수를 설정하세요 (CreateSpeechRecognizer, 매개변수에 대해서는 여기 참조).
- 필요한 델리게이트에 바인딩하세요 (OnRecognitionFinished, OnRecognizedTextSegment 및 OnRecognitionError).
- 음성 인식을 시작하세요 (StartSpeechRecognition).
- 오디오 데이터를 처리하고 델리게이트로부터 결과를 기다리세요 (ProcessAudioData).
- 필요할 때(예: OnRecognitionFinished 브로드캐스트 후) 음성 인식기를 중지하세요.
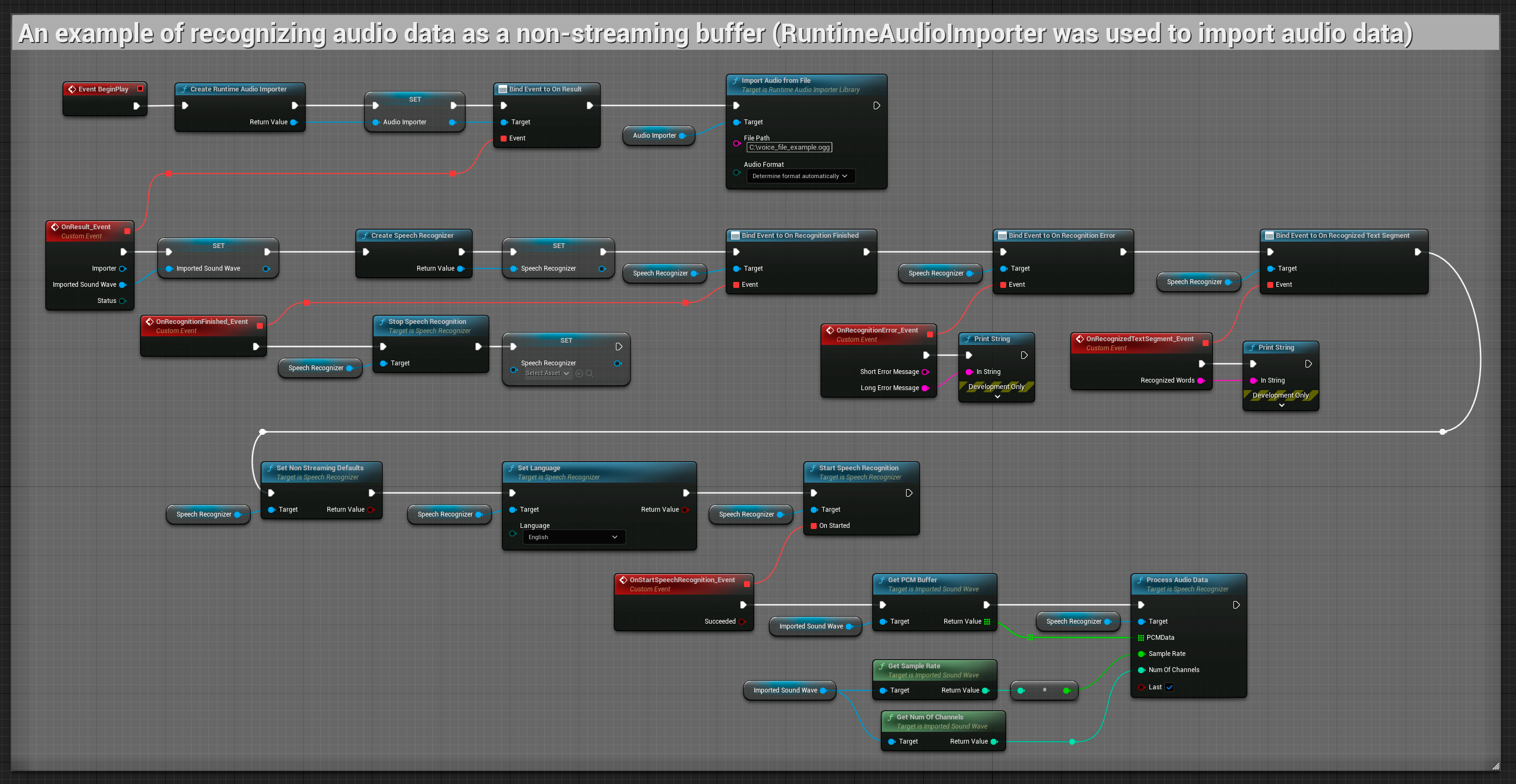
이 플러그인은 부동 소수점 32비트 인터리브 PCM 형식으로 들어오는 오디오를 지원합니다. Runtime Audio Importer와 잘 작동하지만, 직접적으로 의존하지는 않습니다.
인식 매개변수
이 플러그인은 스트리밍 및 비스트리밍 오디오 데이터 인식을 모두 지원합니다. 특정 사용 사례에 맞게 인식 매개변수를 조정하려면 SetStreamingDefaults 또는 SetNonStreamingDefaults를 호출하세요. 또한 스레드 수, 스텝 크기, 들어오는 언어를 영어로 번역할지 여부, 이전 전사를 사용할지 여부와 같은 개별 매개변수를 수동으로 설정할 수 있는 유연성이 있습니다. 사용 가능한 매개변수의 전체 목록은 인식 매개변수 목록을 참조하세요.
성능 향상
플러그인의 성능을 최적화하는 방법에 대한 팁은 성능 향상 방법 섹션을 참조하세요.
음성 활동 감지 (VAD)
오디오 입력을 처리할 때, 특히 스트리밍 시나리오에서는 인식기에 도달하기 전에 빈 또는 잡음만 있는 오디오 세그먼트를 필터링하기 위해 음성 활동 감지(VAD)를 사용하는 것이 좋습니다. 이 필터링은 Runtime Audio Importer 플러그인을 사용하여 캡처 가능한 사운드 웨이브 측에서 활성화할 수 있으며, 이는 언어 모델이 잡음에서 패턴을 찾고 잘못된 전사를 생성하려는 환각(hallucinating) 현상을 방지하는 데 도움이 됩니다.
최적의 음성 인식 결과를 위해 우수한 노이즈 내성과 더 정확한 음성 감지를 제공하는 Silero VAD provider 사용을 권장합니다. Silero VAD는 Runtime Audio Importer 플러그인의 확장으로 사용할 수 있습니다. VAD 구성에 대한 자세한 지침은 음성 활동 감지 문서를 참조하세요.
아래 예제에서 복사 가능한 노드들은 호환성 이유로 기본 VAD 제공자를 사용합니다. 인식 정확도를 향상시키려면 다음과 같이 Silero VAD로 쉽게 전환할 수 있습니다:
- Silero VAD Extension 섹션에 설명된 대로 Silero VAD 확장 프로그램 설치
- Toggle VAD 노드로 VAD를 활성화한 후, Set VAD Provider 노드를 추가하고 드롭다운에서 "Silero" 선택
플러그인에 포함된 데모 프로젝트에서는 VAD가 기본적으로 활성화되어 있습니다. 데모 구현에 대한 자세한 정보는 Demo Project에서 확인할 수 있습니다.
예제
플러그인의 Content -> Demo 폴더에 포함된 훌륭한 프로젝트 데모가 있으며, 구현 예시로 사용할 수 있습니다.
이 예제들은 Runtime Audio Importer를 사용하여 오디오 데이터를 얻는 것을 예로 들어, 스트리밍 및 비스트리밍 오디오 입력과 함께 Runtime Speech Recognizer 플러그인을 사용하는 방법을 보여줍니다. 예제에서 보여주는 동일한 오디오 임포트 기능 세트(예: 캡처 가능한 사운드 웨이브 및 ImportAudioFromFile)에 액세스하려면 RuntimeAudioImporter를 별도로 다운로드해야 합니다. 이러한 예제들은 핵심 개념을 설명하기 위한 목적으로만 제공되며 오류 처리를 포함하지 않습니다.
스트리밍 오디오 입력 예제
참고: UE 5.3 및 다른 버전에서는 Blueprint 복사 후 노드가 누락될 수 있습니다. 이는 엔진 버전 간 노드 직렬화 차이로 인해 발생할 수 있습니다. 구현 시 모든 노드가 제대로 연결되었는지 항상 확인하십시오.
1. 기본 스트리밍 인식
이 예제는 Capturable 사운드 웨이브를 사용하여 마이크로폰에서 오디오 데이터를 스트림으로 캡처하고 이를 음성 인식기에 전달하기 위한 기본 설정을 보여줍니다. 약 5초 동안 음성을 녹음한 후 인식을 처리하므로 빠른 테스트와 간단한 구현에 적합합니다. 복사 가능한 노드.
이 설정의 주요 특징:
- 고정된 5초 녹음 시간
- 간단한 원샷 인식
- 최소 설정 요구사항
- 테스트 및 프로토타이핑에 완벽함
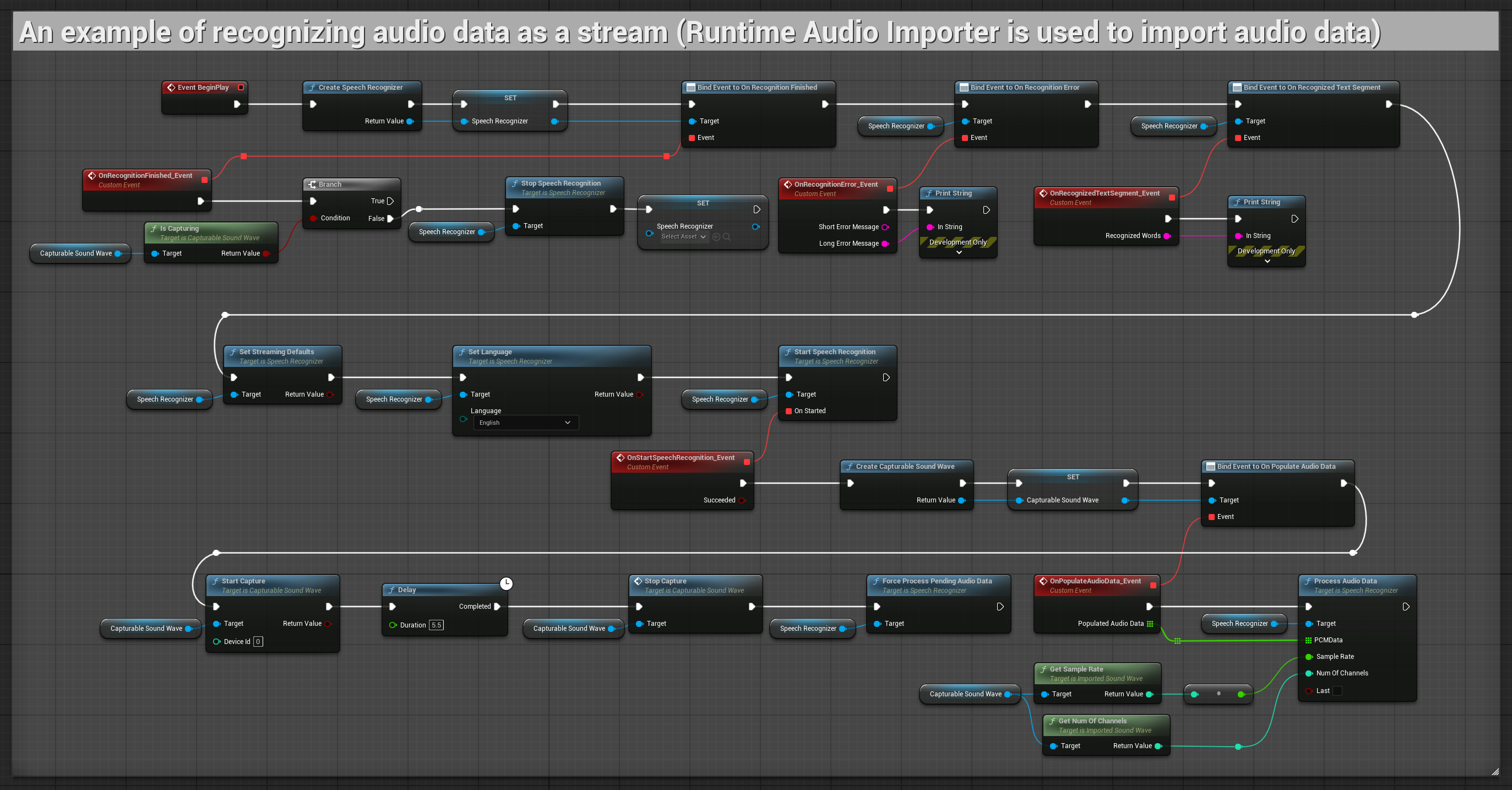
2. 제어된 스트리밍 인식
이 예제는 인식 프로세스를 수동으로 제어하는 기능을 추가하여 기본 스트리밍 설정을 확장합니다. 원하는 때에 인식을 시작하고 중지할 수 있도록 하여, 인식이 발생하는 시점을 정밀하게 제어해야 하는 시나리오에 적합합니다. 복사 가능한 노드.
이 설정의 주요 특징:
- 수동 시작/중단 제어
- 연속 인식 기능
- 유연한 녹음 지속 시간
- 대화형 애플리케이션에 적합
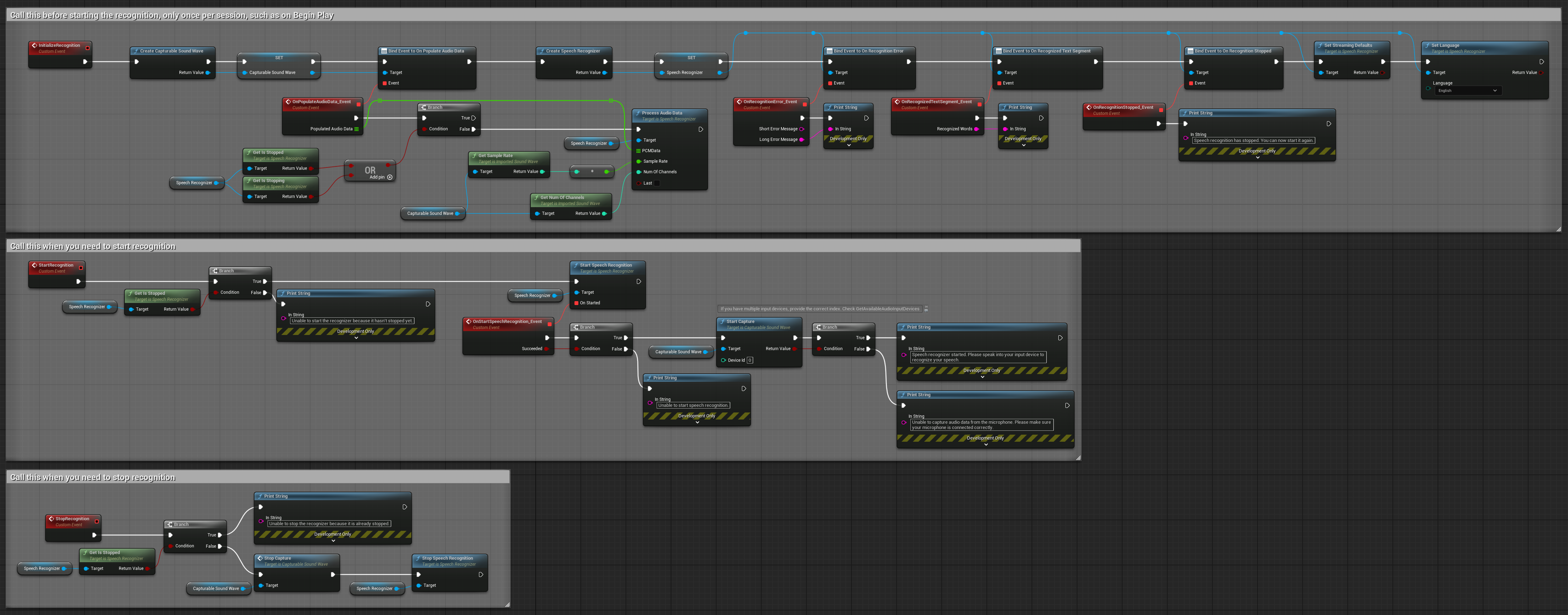
3. 음성 활성화 명령 인식
이 예제는 명령 인식 시나리오에 최적화되어 있습니다. 스트리밍 인식과 음성 활동 감지(VAD)를 결합하여 사용자가 말을 멈출 때 자동으로 음성을 처리합니다. 인식기는 침묵이 감지되었을 때만 누적된 음성을 처리하기 시작하므로, 명령 기반 인터페이스에 이상적입니다. 복사 가능한 노드.
이 설정의 주요 특징:
- 수동 시작/중단 제어
- 음성 구간 감지를 위해 음성 활동 감지(VAD) 활성화
- 침묵 감지 시 자동 인식 트리거
- 짧은 명령 인식에 최적
- 실제 음성만 인식하여 처리 오버헤드 감소
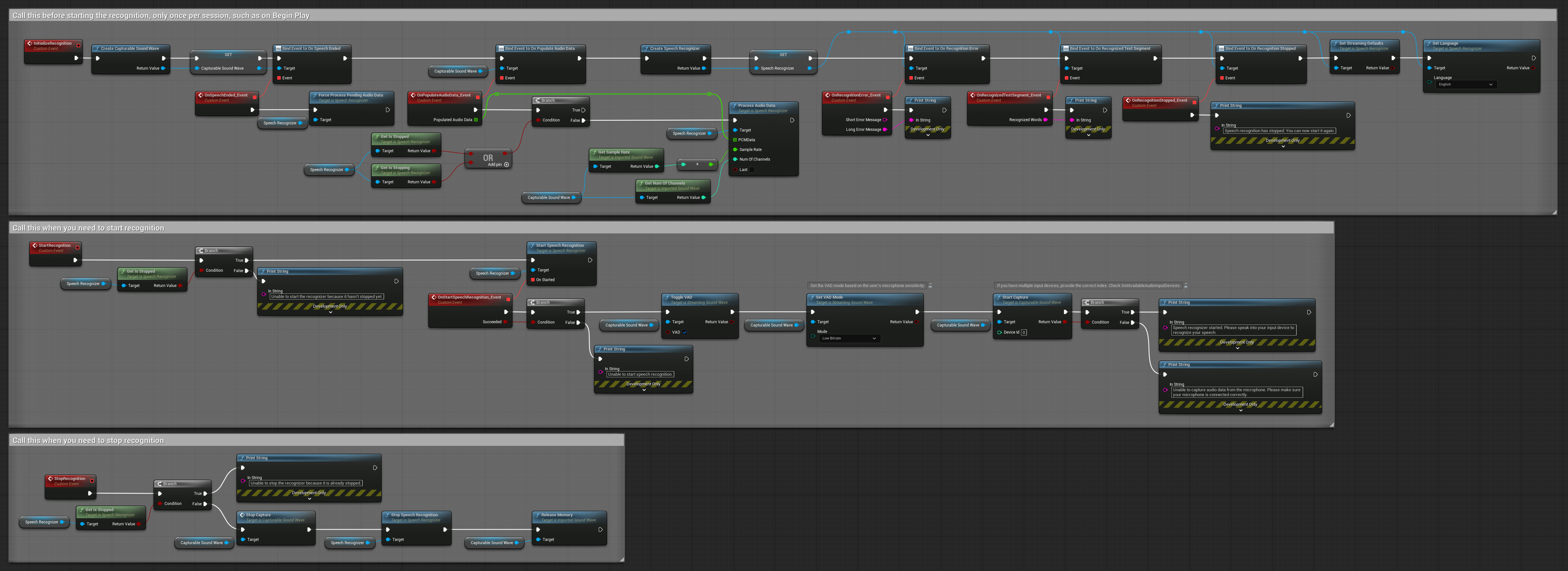
4. 최종 버퍼 처리를 통한 자동 초기화 음성 인식
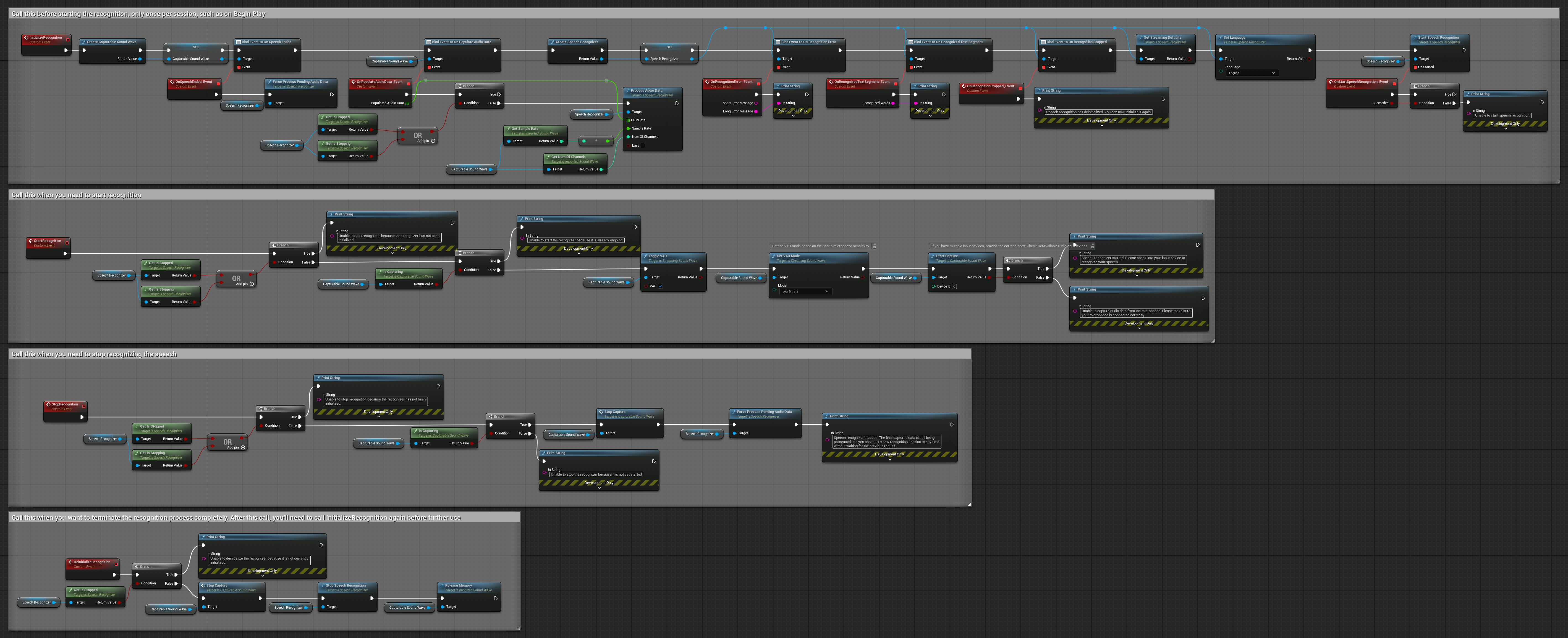
이 예제는 다른 생명주기 처리를 가진 음성 활성화 인식 접근법의 또 다른 변형입니다. 초기화 중에 인식기를 자동으로 시작하고 초기화 해제 중에 중단합니다. 주요 특징은 인식기를 중단하기 전에 마지막으로 누적된 오디오 버퍼를 처리하여 사용자가 인식 프로세스를 종료하려 할 때 음성 데이터가 손실되지 않도록 보장한다는 점입니다. 이 설정은 사용자가 말하는 도중에 중단하더라도 완전한 발화를 캡처해야 하는 애플리케이션에 특히 유용합니다. 복사 가능한 노드.
이 설정의 주요 특징:
- 초기화 시 인식기 자동 시작
- 초기화 해제 시 인식기 자동 중단
- 완전히 중단하기 전에 최종 오디오 버퍼 처리
- 효율적인 인식을 위해 음성 활동 감지(VAD) 사용
- 중단 시 음성 데이터 손실 없음 보장
비스트리밍 오디오 입력
이 예제는 오디오 데이터를 Imported sound wave로 가져오고, 가져온 전체 오디오 데이터를 한 번에 인식합니다. 복사 가능한 노드.